 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKOALA: Knowledge Conflict Augmentations for Robustness in Vision Language Models
Feb 19, 2025
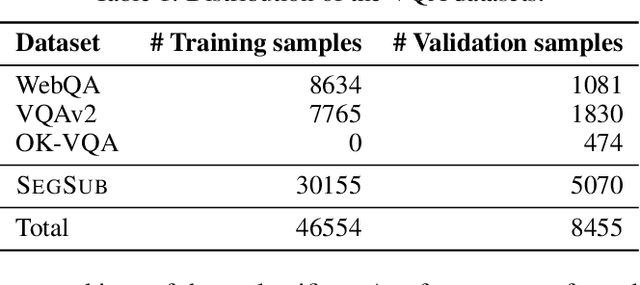


The robustness of large language models (LLMs) against knowledge conflicts in unimodal question answering systems has been well studied. However, the effect of conflicts in information sources on vision language models (VLMs) in multimodal settings has not yet been explored. In this work, we propose \segsub, a framework that applies targeted perturbations to image sources to study and improve the robustness of VLMs against three different types of knowledge conflicts, namely parametric, source, and counterfactual conflicts. Contrary to prior findings that showed that LLMs are sensitive to parametric conflicts arising from textual perturbations, we find VLMs are largely robust to image perturbation. On the other hand, VLMs perform poorly on counterfactual examples (<30% accuracy) and fail to reason over source conflicts (<1% accuracy). We also find a link between hallucinations and image context, with GPT-4o prone to hallucination when presented with highly contextualized counterfactual examples. While challenges persist with source conflicts, finetuning models significantly improves reasoning over counterfactual samples. Our findings highlight the need for VLM training methodologies that enhance their reasoning capabilities, particularly in addressing complex knowledge conflicts between multimodal sources.
Quantifying Memorization and Retriever Performance in Retrieval-Augmented Vision-Language Models
Feb 19, 2025Large Language Models (LLMs) demonstrate remarkable capabilities in question answering (QA), but metrics for assessing their reliance on memorization versus retrieval remain underdeveloped. Moreover, while finetuned models are state-of-the-art on closed-domain tasks, general-purpose models like GPT-4o exhibit strong zero-shot performance. This raises questions about the trade-offs between memorization, generalization, and retrieval. In this work, we analyze the extent to which multimodal retrieval-augmented VLMs memorize training data compared to baseline VLMs. Using the WebQA benchmark, we contrast finetuned models with baseline VLMs on multihop retrieval and question answering, examining the impact of finetuning on data memorization. To quantify memorization in end-to-end retrieval and QA systems, we propose several proxy metrics by investigating instances where QA succeeds despite retrieval failing. Our results reveal the extent to which finetuned models rely on memorization. In contrast, retrieval-augmented VLMs have lower memorization scores, at the cost of accuracy (72% vs 52% on WebQA test set). As such, our measures pose a challenge for future work to reconcile memorization and generalization in both Open-Domain QA and joint Retrieval-QA tasks.
Intent Identification and Entity Extraction for Healthcare Queries in Indic Languages
Feb 19, 2023Scarcity of data and technological limitations for resource-poor languages in developing countries like India poses a threat to the development of sophisticated NLU systems for healthcare. To assess the current status of various state-of-the-art language models in healthcare, this paper studies the problem by initially proposing two different Healthcare datasets, Indian Healthcare Query Intent-WebMD and 1mg (IHQID-WebMD and IHQID-1mg) and one real world Indian hospital query data in English and multiple Indic languages (Hindi, Bengali, Tamil, Telugu, Marathi and Gujarati) which are annotated with the query intents as well as entities. Our aim is to detect query intents and extract corresponding entities. We perform extensive experiments on a set of models in various realistic settings and explore two scenarios based on the access to English data only (less costly) and access to target language data (more expensive). We analyze context specific practical relevancy through empirical analysis. The results, expressed in terms of overall F1 score show that our approach is practically useful to identify intents and entities.
An Evaluation Framework for Legal Document Summarization
May 17, 2022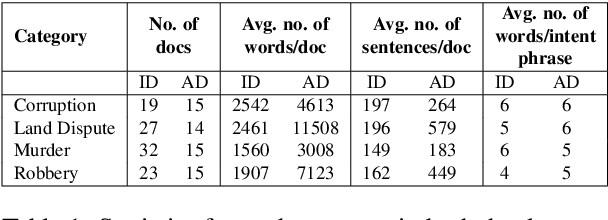
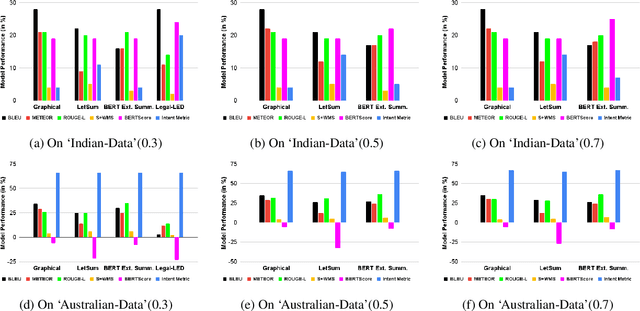
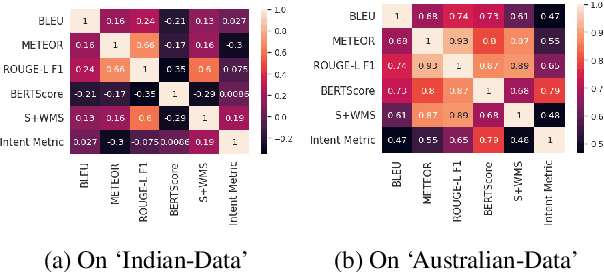
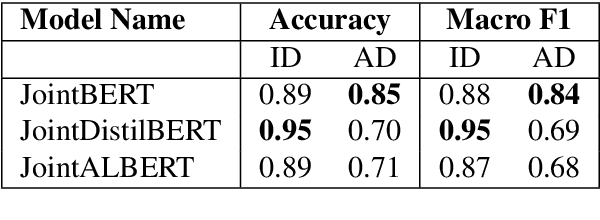
A law practitioner has to go through numerous lengthy legal case proceedings for their practices of various categories, such as land dispute, corruption, etc. Hence, it is important to summarize these documents, and ensure that summaries contain phrases with intent matching the category of the case. To the best of our knowledge, there is no evaluation metric that evaluates a summary based on its intent. We propose an automated intent-based summarization metric, which shows a better agreement with human evaluation as compared to other automated metrics like BLEU, ROUGE-L etc. in terms of human satisfaction. We also curate a dataset by annotating intent phrases in legal documents, and show a proof of concept as to how this system can be automated. Additionally, all the code and data to generate reproducible results is available on Github.
Fine-grained Intent Classification in the Legal Domain
May 06, 2022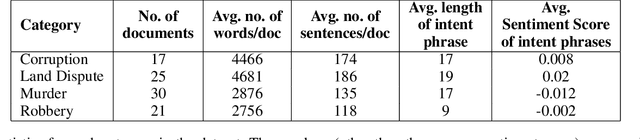

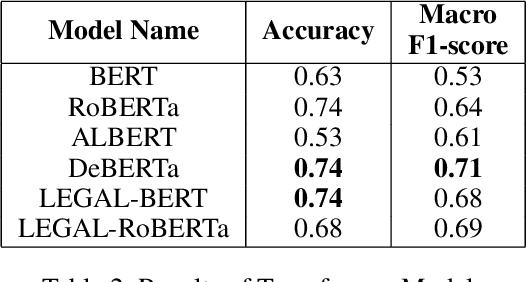
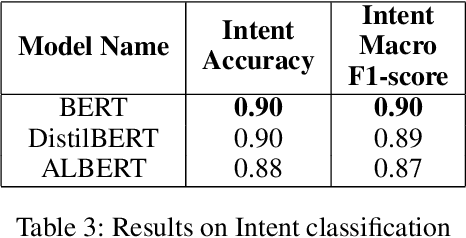
A law practitioner has to go through a lot of long legal case proceedings. To understand the motivation behind the actions of different parties/individuals in a legal case, it is essential that the parts of the document that express an intent corresponding to the case be clearly understood. In this paper, we introduce a dataset of 93 legal documents, belonging to the case categories of either Murder, Land Dispute, Robbery, or Corruption, where phrases expressing intent same as the category of the document are annotated. Also, we annotate fine-grained intents for each such phrase to enable a deeper understanding of the case for a reader. Finally, we analyze the performance of several transformer-based models in automating the process of extracting intent phrases (both at a coarse and a fine-grained level), and classifying a document into one of the possible 4 categories, and observe that, our dataset is challenging, especially in the case of fine-grained intent classification.