 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Good Talk Does not Look Like a Summary, It Teaches You! Measuring Takeaways from Paper-to-Video Talks
Jun 26, 2026Automatically generated videos from scientific papers are increasingly used for education and research dissemination. However, existing evaluation metrics mainly measure visual quality or whether key points from the paper appear in the video without assessing whether the video actually helps viewers understand the ideas. We introduce EffectivePresentationScorer, a framework for evaluating the instructional quality of scientific presentation videos. It checks whether a video explains the main ideas clearly, introduces needed background concepts, and connects technical details to the main contribution of the paper. When we apply EffectivePresentationScorer to the existing paper-to-video generation systems, we find that generated videos mention the correct topics and follow the structure of the paper but fail to explain prerequisite concepts or clarify why the method works. These failures are often ignored by existing video evaluation metrics, which focus on content presence rather than explanatory quality.
Helping Figures Tell their Story! Paper-Grounded Video Generation Explaining Complex Scientific Figures
Jun 10, 2026Scientific figures compress complex pipelines into a single canvas, yet understanding them requires paper-grounded, step-by-step narration aligned with visual highlights a capability missing from current video generation systems and benchmarks. To address this, we introduce paper-grounded figure-to-video generation: generating narrated, region-grounded walkthrough videos from a figure and its paper. We propose MINARD (Multimodal Interpretation of Narrated Architecture via Region Decomposition), a pipeline that generates paper-grounded narrations and sequentially grounds them to figure regions. We also release FigTalk, a benchmark with new sequential and component-level grounding metrics derived. On FigTalk, MINARD generates humanlike, paper-faithful narrations and outperforms narration-conditioned figure spatial grounding compared to existing approaches in both automatic and human evaluation
CANVAS: Continuity-Aware Narratives via Visual Agentic Storyboarding
Apr 15, 2026Long-form visual storytelling requires maintaining continuity across shots, including consistent characters, stable environments, and smooth scene transitions. While existing generative models can produce strong individual frames, they fail to preserve such continuity, leading to appearance changes, inconsistent backgrounds, and abrupt scene shifts. We introduce CANVAS (Continuity-Aware Narratives via Visual Agentic Storyboarding), a multi-agent framework that explicitly plans visual continuity in multi-shot narratives. CANVAS enforces coherence through character continuity, persistent background anchors, and location-aware scene planning for smooth transitions within the same setting We evaluate CANVAS on two storyboard generation benchmarks ST-BENCH and ViStoryBench and introduce a new challenging benchmark HardContinuityBench for long-range narrative consistency. CANVAS consistently outperforms the best-performing baseline, improving background continuity by 21.6%, character consistency by 9.6% and props consistency by 7.6%.
NLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
Correlating instruction-tuning (in multimodal models) with vision-language processing (in the brain)
May 26, 2025Transformer-based language models, though not explicitly trained to mimic brain recordings, have demonstrated surprising alignment with brain activity. Progress in these models-through increased size, instruction-tuning, and multimodality-has led to better representational alignment with neural data. Recently, a new class of instruction-tuned multimodal LLMs (MLLMs) have emerged, showing remarkable zero-shot capabilities in open-ended multimodal vision tasks. However, it is unknown whether MLLMs, when prompted with natural instructions, lead to better brain alignment and effectively capture instruction-specific representations. To address this, we first investigate brain alignment, i.e., measuring the degree of predictivity of neural visual activity using text output response embeddings from MLLMs as participants engage in watching natural scenes. Experiments with 10 different instructions show that MLLMs exhibit significantly better brain alignment than vision-only models and perform comparably to non-instruction-tuned multimodal models like CLIP. We also find that while these MLLMs are effective at generating high-quality responses suitable to the task-specific instructions, not all instructions are relevant for brain alignment. Further, by varying instructions, we make the MLLMs encode instruction-specific visual concepts related to the input image. This analysis shows that MLLMs effectively capture count-related and recognition-related concepts, demonstrating strong alignment with brain activity. Notably, the majority of the explained variance of the brain encoding models is shared between MLLM embeddings of image captioning and other instructions. These results suggest that enhancing MLLMs' ability to capture task-specific information could lead to better differentiation between various types of instructions, and thereby improving their precision in predicting brain responses.
* 30 pages, 22 figures, The Thirteenth International Conference on Learning Representations, ICLR-2025, Singapore. https://openreview.net/pdf?id=xkgfLXZ4e0
Group Preference Alignment: Customized LLM Response Generation from In-Situ Conversations
Mar 11, 2025LLMs often fail to meet the specialized needs of distinct user groups due to their one-size-fits-all training paradigm \cite{lucy-etal-2024-one} and there is limited research on what personalization aspects each group expect. To address these limitations, we propose a group-aware personalization framework, Group Preference Alignment (GPA), that identifies context-specific variations in conversational preferences across user groups and then steers LLMs to address those preferences. Our approach consists of two steps: (1) Group-Aware Preference Extraction, where maximally divergent user-group preferences are extracted from real-world conversation logs and distilled into interpretable rubrics, and (2) Tailored Response Generation, which leverages these rubrics through two methods: a) Context-Tuned Inference (GAP-CT), that dynamically adjusts responses via context-dependent prompt instructions, and b) Rubric-Finetuning Inference (GPA-FT), which uses the rubrics to generate contrastive synthetic data for personalization of group-specific models via alignment. Experiments demonstrate that our framework significantly improves alignment of the output with respect to user preferences and outperforms baseline methods, while maintaining robust performance on standard benchmarks.
Large Language Models Are Effective Human Annotation Assistants, But Not Good Independent Annotators
Mar 09, 2025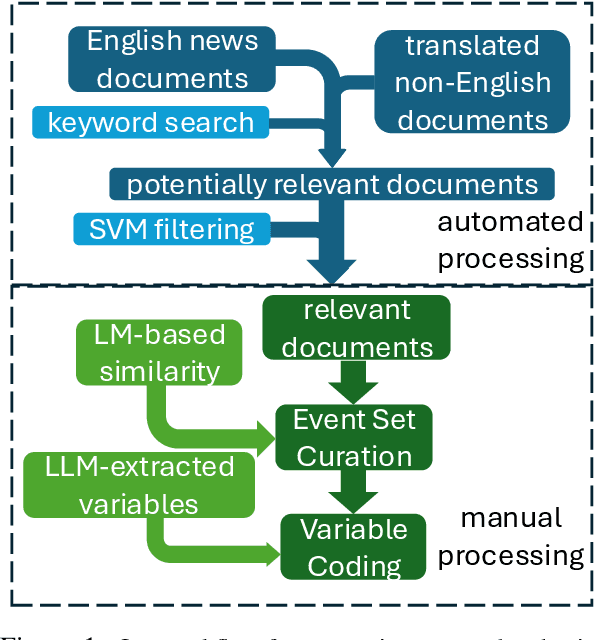
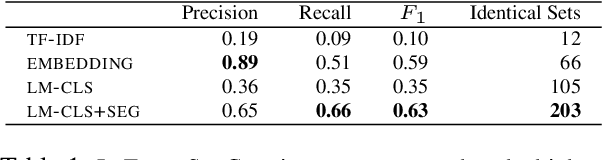

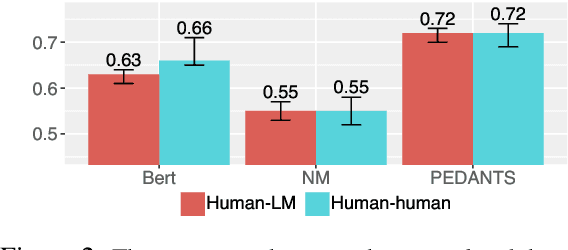
Event annotation is important for identifying market changes, monitoring breaking news, and understanding sociological trends. Although expert annotators set the gold standards, human coding is expensive and inefficient. Unlike information extraction experiments that focus on single contexts, we evaluate a holistic workflow that removes irrelevant documents, merges documents about the same event, and annotates the events. Although LLM-based automated annotations are better than traditional TF-IDF-based methods or Event Set Curation, they are still not reliable annotators compared to human experts. However, adding LLMs to assist experts for Event Set Curation can reduce the time and mental effort required for Variable Annotation. When using LLMs to extract event variables to assist expert annotators, they agree more with the extracted variables than fully automated LLMs for annotation.
SciDoc2Diagrammer-MAF: Towards Generation of Scientific Diagrams from Documents guided by Multi-Aspect Feedback Refinement
Sep 28, 2024Automating the creation of scientific diagrams from academic papers can significantly streamline the development of tutorials, presentations, and posters, thereby saving time and accelerating the process. Current text-to-image models struggle with generating accurate and visually appealing diagrams from long-context inputs. We propose SciDoc2Diagram, a task that extracts relevant information from scientific papers and generates diagrams, along with a benchmarking dataset, SciDoc2DiagramBench. We develop a multi-step pipeline SciDoc2Diagrammer that generates diagrams based on user intentions using intermediate code generation. We observed that initial diagram drafts were often incomplete or unfaithful to the source, leading us to develop SciDoc2Diagrammer-Multi-Aspect-Feedback (MAF), a refinement strategy that significantly enhances factual correctness and visual appeal and outperforms existing models on both automatic and human judgement.
* Code and data available at https://github.com/Ishani-Mondal/SciDoc2DiagramGeneration
ADVSCORE: A Metric for the Evaluation and Creation of Adversarial Benchmarks
Jun 24, 2024



Adversarial benchmarks validate model abilities by providing samples that fool models but not humans. However, despite the proliferation of datasets that claim to be adversarial, there does not exist an established metric to evaluate how adversarial these datasets are. To address this lacuna, we introduce ADVSCORE, a metric which quantifies how adversarial and discriminative an adversarial dataset is and exposes the features that make data adversarial. We then use ADVSCORE to underpin a dataset creation pipeline that incentivizes writing a high-quality adversarial dataset. As a proof of concept, we use ADVSCORE to collect an adversarial question answering (QA) dataset, ADVQA, from our pipeline. The high-quality questions in ADVQA surpasses three adversarial benchmarks across domains at fooling several models but not humans. We validate our result based on difficulty estimates from 9,347 human responses on four datasets and predictions from three models. Moreover, ADVSCORE uncovers which adversarial tactics used by human writers fool models (e.g., GPT-4) but not humans. Through ADVSCORE and its analyses, we offer guidance on revealing language model vulnerabilities and producing reliable adversarial examples.
How much reliable is ChatGPT's prediction on Information Extraction under Input Perturbations?
Apr 07, 2024In this paper, we assess the robustness (reliability) of ChatGPT under input perturbations for one of the most fundamental tasks of Information Extraction (IE) i.e. Named Entity Recognition (NER). Despite the hype, the majority of the researchers have vouched for its language understanding and generation capabilities; a little attention has been paid to understand its robustness: How the input-perturbations affect 1) the predictions, 2) the confidence of predictions and 3) the quality of rationale behind its prediction. We perform a systematic analysis of ChatGPT's robustness (under both zero-shot and few-shot setup) on two NER datasets using both automatic and human evaluation. Based on automatic evaluation metrics, we find that 1) ChatGPT is more brittle on Drug or Disease replacements (rare entities) compared to the perturbations on widely known Person or Location entities, 2) the quality of explanations for the same entity considerably differ under different types of "Entity-Specific" and "Context-Specific" perturbations and the quality can be significantly improved using in-context learning, and 3) it is overconfident for majority of the incorrect predictions, and hence it could lead to misguidance of the end-users.