 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentCompass: Towards Reliable Evaluation of Agentic Workflows in Production
Sep 18, 2025With the growing adoption of Large Language Models (LLMs) in automating complex, multi-agent workflows, organizations face mounting risks from errors, emergent behaviors, and systemic failures that current evaluation methods fail to capture. We present AgentCompass, the first evaluation framework designed specifically for post-deployment monitoring and debugging of agentic workflows. AgentCompass models the reasoning process of expert debuggers through a structured, multi-stage analytical pipeline: error identification and categorization, thematic clustering, quantitative scoring, and strategic summarization. The framework is further enhanced with a dual memory system-episodic and semantic-that enables continual learning across executions. Through collaborations with design partners, we demonstrate the framework's practical utility on real-world deployments, before establishing its efficacy against the publicly available TRAIL benchmark. AgentCompass achieves state-of-the-art results on key metrics, while uncovering critical issues missed in human annotations, underscoring its role as a robust, developer-centric tool for reliable monitoring and improvement of agentic systems in production.
Akal Badi ya Bias: An Exploratory Study of Gender Bias in Hindi Language Technology
May 10, 2024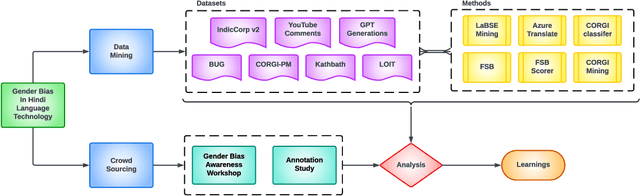

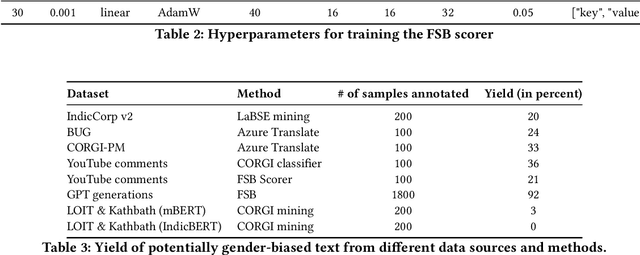
Existing research in measuring and mitigating gender bias predominantly centers on English, overlooking the intricate challenges posed by non-English languages and the Global South. This paper presents the first comprehensive study delving into the nuanced landscape of gender bias in Hindi, the third most spoken language globally. Our study employs diverse mining techniques, computational models, field studies and sheds light on the limitations of current methodologies. Given the challenges faced with mining gender biased statements in Hindi using existing methods, we conducted field studies to bootstrap the collection of such sentences. Through field studies involving rural and low-income community women, we uncover diverse perceptions of gender bias, underscoring the necessity for context-specific approaches. This paper advocates for a community-centric research design, amplifying voices often marginalized in previous studies. Our findings not only contribute to the understanding of gender bias in Hindi but also establish a foundation for further exploration of Indic languages. By exploring the intricacies of this understudied context, we call for thoughtful engagement with gender bias, promoting inclusivity and equity in linguistic and cultural contexts beyond the Global North.
METAL: Towards Multilingual Meta-Evaluation
Apr 02, 2024



With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
MunTTS: A Text-to-Speech System for Mundari
Jan 28, 2024



We present MunTTS, an end-to-end text-to-speech (TTS) system specifically for Mundari, a low-resource Indian language of the Austo-Asiatic family. Our work addresses the gap in linguistic technology for underrepresented languages by collecting and processing data to build a speech synthesis system. We begin our study by gathering a substantial dataset of Mundari text and speech and train end-to-end speech models. We also delve into the methods used for training our models, ensuring they are efficient and effective despite the data constraints. We evaluate our system with native speakers and objective metrics, demonstrating its potential as a tool for preserving and promoting the Mundari language in the digital age.
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks
Nov 13, 2023Recently, there has been a rapid advancement in research on Large Language Models (LLMs), resulting in significant progress in several Natural Language Processing (NLP) tasks. Consequently, there has been a surge in LLM evaluation research to comprehend the models' capabilities and limitations. However, much of this research has been confined to the English language, leaving LLM building and evaluation for non-English languages relatively unexplored. There has been an introduction of several new LLMs, necessitating their evaluation on non-English languages. This study aims to expand our MEGA benchmarking suite by including six new datasets to form the MEGAVERSE benchmark. The benchmark comprises 22 datasets covering 81 languages, including low-resource African languages. We evaluate several state-of-the-art LLMs like GPT-3.5-Turbo, GPT4, PaLM2, and Llama2 on the MEGAVERSE datasets. Additionally, we include two multimodal datasets in the benchmark and assess the performance of the LLaVa-v1.5 model. Our experiments suggest that GPT4 and PaLM2 outperform the Llama models on various tasks, notably on low-resource languages, with GPT4 outperforming PaLM2 on more datasets than vice versa. However, issues such as data contamination must be addressed to obtain an accurate assessment of LLM performance on non-English languages.
''Fifty Shades of Bias'': Normative Ratings of Gender Bias in GPT Generated English Text
Oct 26, 2023
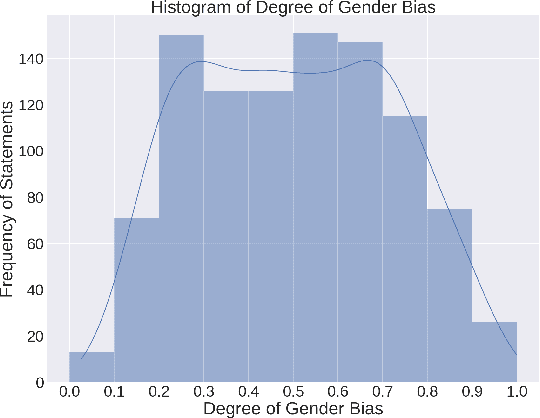

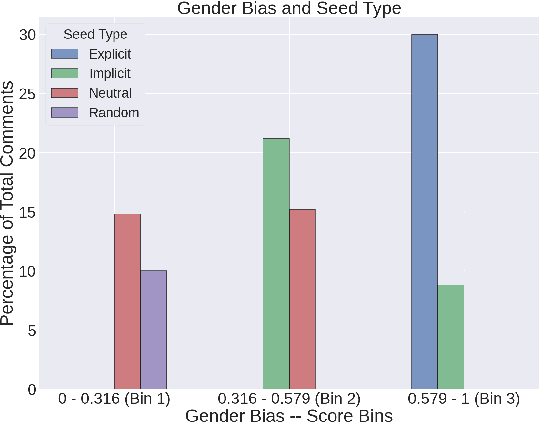
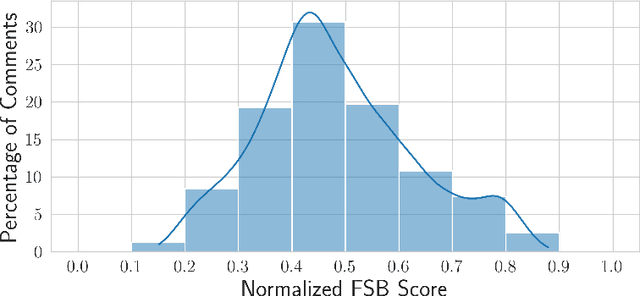
Language serves as a powerful tool for the manifestation of societal belief systems. In doing so, it also perpetuates the prevalent biases in our society. Gender bias is one of the most pervasive biases in our society and is seen in online and offline discourses. With LLMs increasingly gaining human-like fluency in text generation, gaining a nuanced understanding of the biases these systems can generate is imperative. Prior work often treats gender bias as a binary classification task. However, acknowledging that bias must be perceived at a relative scale; we investigate the generation and consequent receptivity of manual annotators to bias of varying degrees. Specifically, we create the first dataset of GPT-generated English text with normative ratings of gender bias. Ratings were obtained using Best--Worst Scaling -- an efficient comparative annotation framework. Next, we systematically analyze the variation of themes of gender biases in the observed ranking and show that identity-attack is most closely related to gender bias. Finally, we show the performance of existing automated models trained on related concepts on our dataset.
Are Large Language Model-based Evaluators the Solution to Scaling Up Multilingual Evaluation?
Sep 14, 2023



Large Language Models (LLMs) have demonstrated impressive performance on Natural Language Processing (NLP) tasks, such as Question Answering, Summarization, and Classification. The use of LLMs as evaluators, that can rank or score the output of other models (usually LLMs) has become increasingly popular, due to the limitations of current evaluation techniques including the lack of appropriate benchmarks, metrics, cost, and access to human annotators. While LLMs are capable of handling approximately 100 languages, the majority of languages beyond the top 20 lack systematic evaluation across various tasks, metrics, and benchmarks. This creates an urgent need to scale up multilingual evaluation to ensure a precise understanding of LLM performance across diverse languages. LLM-based evaluators seem like the perfect solution to this problem, as they do not require human annotators, human-created references, or benchmarks and can theoretically be used to evaluate any language covered by the LLM. In this paper, we investigate whether LLM-based evaluators can help scale up multilingual evaluation. Specifically, we calibrate LLM-based evaluation against 20k human judgments of five metrics across three text-generation tasks in eight languages. Our findings indicate that LLM-based evaluators may exhibit bias towards higher scores and should be used with caution and should always be calibrated with a dataset of native speaker judgments, particularly in low-resource and non-Latin script languages.
MEGA: Multilingual Evaluation of Generative AI
Apr 03, 2023



Generative AI models have impressive performance on many Natural Language Processing tasks such as language understanding, reasoning and language generation. One of the most important questions that is being asked by the AI community today is about the capabilities and limits of these models, and it is clear that evaluating generative AI is very challenging. Most studies on generative Large Language Models (LLMs) are restricted to English and it is unclear how capable these models are at understanding and generating other languages. We present the first comprehensive benchmarking of generative LLMs - MEGA, which evaluates models on standard NLP benchmarks, covering 8 diverse tasks and 33 typologically diverse languages. We also compare the performance of generative LLMs to State of the Art (SOTA) non-autoregressive models on these tasks to determine how well generative models perform compared to the previous generation of LLMs. We present a thorough analysis of the performance of models across languages and discuss some of the reasons why generative LLMs are currently not optimal for all languages. We create a framework for evaluating generative LLMs in the multilingual setting and provide directions for future progress in the field.
Beyond Digital "Echo Chambers": The Role of Viewpoint Diversity in Political Discussion
Dec 18, 2022



Increasingly taking place in online spaces, modern political conversations are typically perceived to be unproductively affirming -- siloed in so called ``echo chambers'' of exclusively like-minded discussants. Yet, to date we lack sufficient means to measure viewpoint diversity in conversations. To this end, in this paper, we operationalize two viewpoint metrics proposed for recommender systems and adapt them to the context of social media conversations. This is the first study to apply these two metrics (Representation and Fragmentation) to real world data and to consider the implications for online conversations specifically. We apply these measures to two topics -- daylight savings time (DST), which serves as a control, and the more politically polarized topic of immigration. We find that the diversity scores for both Fragmentation and Representation are lower for immigration than for DST. Further, we find that while pro-immigrant views receive consistent pushback on the platform, anti-immigrant views largely operate within echo chambers. We observe less severe yet similar patterns for DST. Taken together, Representation and Fragmentation paint a meaningful and important new picture of viewpoint diversity.
Ruddit: Norms of Offensiveness for English Reddit Comments
Jun 11, 2021
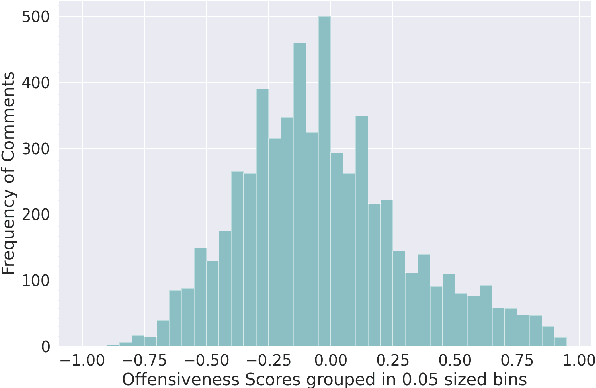

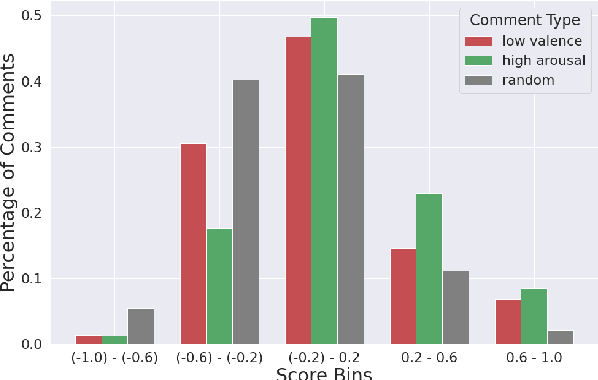
On social media platforms, hateful and offensive language negatively impact the mental well-being of users and the participation of people from diverse backgrounds. Automatic methods to detect offensive language have largely relied on datasets with categorical labels. However, comments can vary in their degree of offensiveness. We create the first dataset of English language Reddit comments that has fine-grained, real-valued scores between -1 (maximally supportive) and 1 (maximally offensive). The dataset was annotated using Best--Worst Scaling, a form of comparative annotation that has been shown to alleviate known biases of using rating scales. We show that the method produces highly reliable offensiveness scores. Finally, we evaluate the ability of widely-used neural models to predict offensiveness scores on this new dataset.