 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Digital "Echo Chambers": The Role of Viewpoint Diversity in Political Discussion
Dec 18, 2022



Increasingly taking place in online spaces, modern political conversations are typically perceived to be unproductively affirming -- siloed in so called ``echo chambers'' of exclusively like-minded discussants. Yet, to date we lack sufficient means to measure viewpoint diversity in conversations. To this end, in this paper, we operationalize two viewpoint metrics proposed for recommender systems and adapt them to the context of social media conversations. This is the first study to apply these two metrics (Representation and Fragmentation) to real world data and to consider the implications for online conversations specifically. We apply these measures to two topics -- daylight savings time (DST), which serves as a control, and the more politically polarized topic of immigration. We find that the diversity scores for both Fragmentation and Representation are lower for immigration than for DST. Further, we find that while pro-immigrant views receive consistent pushback on the platform, anti-immigrant views largely operate within echo chambers. We observe less severe yet similar patterns for DST. Taken together, Representation and Fragmentation paint a meaningful and important new picture of viewpoint diversity.
"It's Not Just Hate'': A Multi-Dimensional Perspective on Detecting Harmful Speech Online
Oct 28, 2022



Well-annotated data is a prerequisite for good Natural Language Processing models. Too often, though, annotation decisions are governed by optimizing time or annotator agreement. We make a case for nuanced efforts in an interdisciplinary setting for annotating offensive online speech. Detecting offensive content is rapidly becoming one of the most important real-world NLP tasks. However, most datasets use a single binary label, e.g., for hate or incivility, even though each concept is multi-faceted. This modeling choice severely limits nuanced insights, but also performance. We show that a more fine-grained multi-label approach to predicting incivility and hateful or intolerant content addresses both conceptual and performance issues. We release a novel dataset of over 40,000 tweets about immigration from the US and UK, annotated with six labels for different aspects of incivility and intolerance. Our dataset not only allows for a more nuanced understanding of harmful speech online, models trained on it also outperform or match performance on benchmark datasets.
Detecting East Asian Prejudice on Social Media
May 08, 2020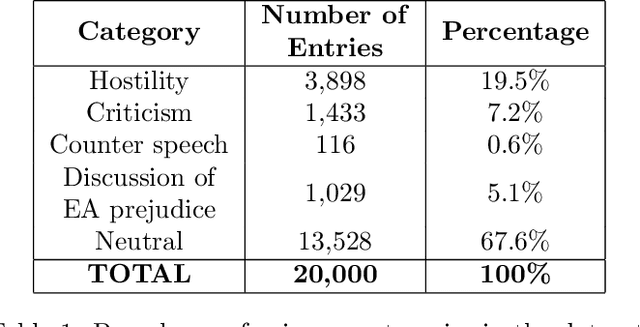
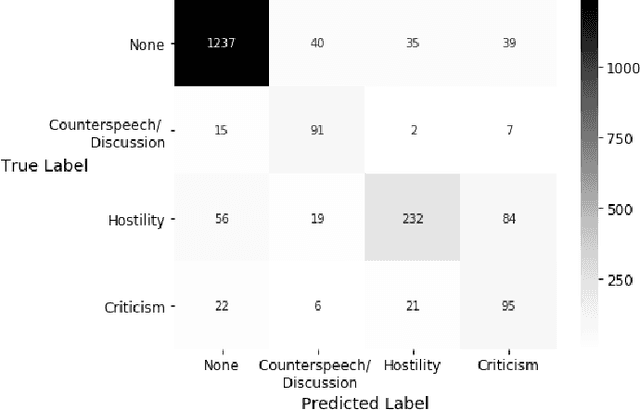
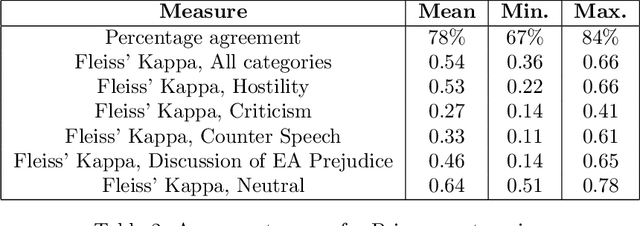
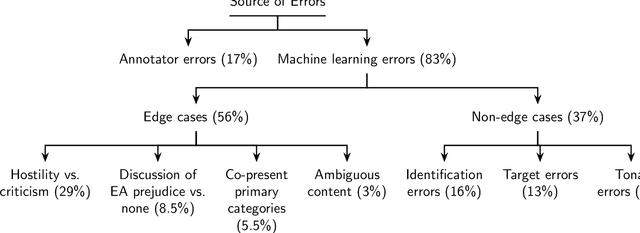
The outbreak of COVID-19 has transformed societies across the world as governments tackle the health, economic and social costs of the pandemic. It has also raised concerns about the spread of hateful language and prejudice online, especially hostility directed against East Asia. In this paper we report on the creation of a classifier that detects and categorizes social media posts from Twitter into four classes: Hostility against East Asia, Criticism of East Asia, Meta-discussions of East Asian prejudice and a neutral class. The classifier achieves an F1 score of 0.83 across all four classes. We provide our final model (coded in Python), as well as a new 20,000 tweet training dataset used to make the classifier, two analyses of hashtags associated with East Asian prejudice and the annotation codebook. The classifier can be implemented by other researchers, assisting with both online content moderation processes and further research into the dynamics, prevalence and impact of East Asian prejudice online during this global pandemic.
How we do things with words: Analyzing text as social and cultural data
Jul 02, 2019In this article we describe our experiences with computational text analysis. We hope to achieve three primary goals. First, we aim to shed light on thorny issues not always at the forefront of discussions about computational text analysis methods. Second, we hope to provide a set of best practices for working with thick social and cultural concepts. Our guidance is based on our own experiences and is therefore inherently imperfect. Still, given our diversity of disciplinary backgrounds and research practices, we hope to capture a range of ideas and identify commonalities that will resonate for many. And this leads to our final goal: to help promote interdisciplinary collaborations. Interdisciplinary insights and partnerships are essential for realizing the full potential of any computational text analysis that involves social and cultural concepts, and the more we are able to bridge these divides, the more fruitful we believe our work will be.