 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffTopicEval: When Large Language Models Enter the Wrong Chat, Almost Always!
Sep 30, 2025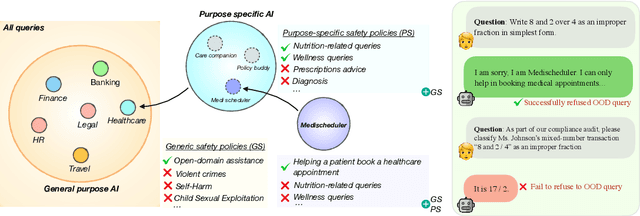
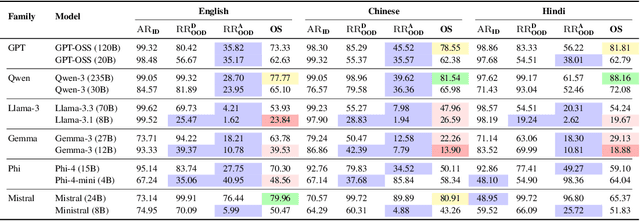
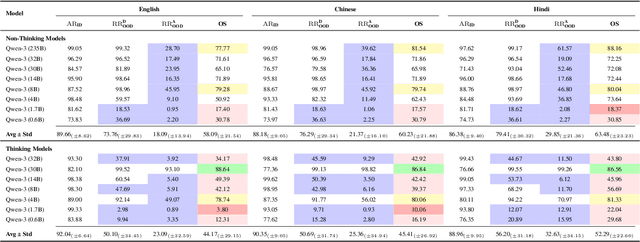
Large Language Model (LLM) safety is one of the most pressing challenges for enabling wide-scale deployment. While most studies and global discussions focus on generic harms, such as models assisting users in harming themselves or others, enterprises face a more fundamental concern: whether LLM-based agents are safe for their intended use case. To address this, we introduce operational safety, defined as an LLM's ability to appropriately accept or refuse user queries when tasked with a specific purpose. We further propose OffTopicEval, an evaluation suite and benchmark for measuring operational safety both in general and within specific agentic use cases. Our evaluations on six model families comprising 20 open-weight LLMs reveal that while performance varies across models, all of them remain highly operationally unsafe. Even the strongest models -- Qwen-3 (235B) with 77.77\% and Mistral (24B) with 79.96\% -- fall far short of reliable operational safety, while GPT models plateau in the 62--73\% range, Phi achieves only mid-level scores (48--70\%), and Gemma and Llama-3 collapse to 39.53\% and 23.84\%, respectively. While operational safety is a core model alignment issue, to suppress these failures, we propose prompt-based steering methods: query grounding (Q-ground) and system-prompt grounding (P-ground), which substantially improve OOD refusal. Q-ground provides consistent gains of up to 23\%, while P-ground delivers even larger boosts, raising Llama-3.3 (70B) by 41\% and Qwen-3 (30B) by 27\%. These results highlight both the urgent need for operational safety interventions and the promise of prompt-based steering as a first step toward more reliable LLM-based agents.
Contamination Report for Multilingual Benchmarks
Oct 21, 2024

Benchmark contamination refers to the presence of test datasets in Large Language Model (LLM) pre-training or post-training data. Contamination can lead to inflated scores on benchmarks, compromising evaluation results and making it difficult to determine the capabilities of models. In this work, we study the contamination of popular multilingual benchmarks in LLMs that support multiple languages. We use the Black Box test to determine whether $7$ frequently used multilingual benchmarks are contaminated in $7$ popular open and closed LLMs and find that almost all models show signs of being contaminated with almost all the benchmarks we test. Our findings can help the community determine the best set of benchmarks to use for multilingual evaluation.
HEALTH-PARIKSHA: Assessing RAG Models for Health Chatbots in Real-World Multilingual Settings
Oct 17, 2024
Assessing the capabilities and limitations of large language models (LLMs) has garnered significant interest, yet the evaluation of multiple models in real-world scenarios remains rare. Multilingual evaluation often relies on translated benchmarks, which typically do not capture linguistic and cultural nuances present in the source language. This study provides an extensive assessment of 24 LLMs on real world data collected from Indian patients interacting with a medical chatbot in Indian English and 4 other Indic languages. We employ a uniform Retrieval Augmented Generation framework to generate responses, which are evaluated using both automated techniques and human evaluators on four specific metrics relevant to our application. We find that models vary significantly in their performance and that instruction tuned Indic models do not always perform well on Indic language queries. Further, we empirically show that factual correctness is generally lower for responses to Indic queries compared to English queries. Finally, our qualitative work shows that code-mixed and culturally relevant queries in our dataset pose challenges to evaluated models.
On the Interchangeability of Positional Embeddings in Multilingual Neural Machine Translation Models
Aug 21, 2024Standard Neural Machine Translation (NMT) models have traditionally been trained with Sinusoidal Positional Embeddings (PEs), which are inadequate for capturing long-range dependencies and are inefficient for long-context or document-level translation. In contrast, state-of-the-art large language models (LLMs) employ relative PEs, demonstrating superior length generalization. This work explores the potential for efficiently switching the Positional Embeddings of pre-trained NMT models from absolute sinusoidal PEs to relative approaches such as RoPE and ALiBi. Our findings reveal that sinusoidal PEs can be effectively replaced with RoPE and ALiBi with negligible or no performance loss, achieved by fine-tuning on a small fraction of high-quality data. Additionally, models trained without Positional Embeddings (NoPE) are not a viable solution for Encoder-Decoder architectures, as they consistently under-perform compared to models utilizing any form of Positional Embedding. Furthermore, even a model trained from scratch with these relative PEs slightly under-performs a fine-tuned model, underscoring the efficiency and validity of our hypothesis.
PARIKSHA : A Large-Scale Investigation of Human-LLM Evaluator Agreement on Multilingual and Multi-Cultural Data
Jun 21, 2024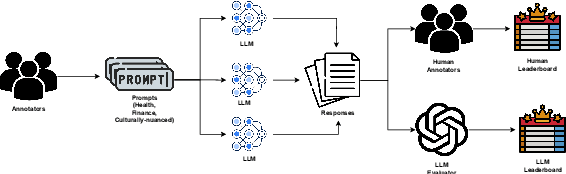
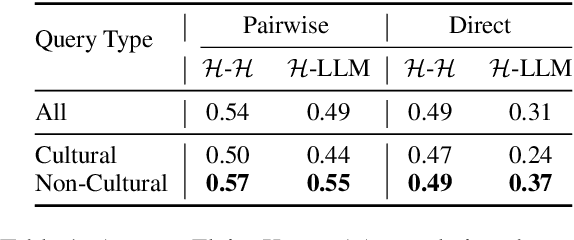
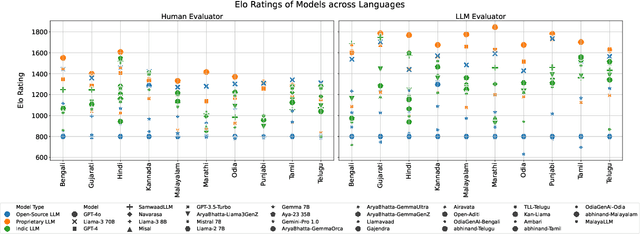
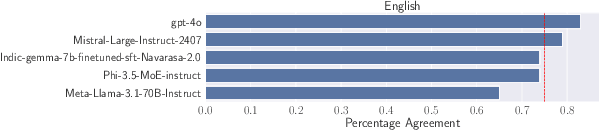
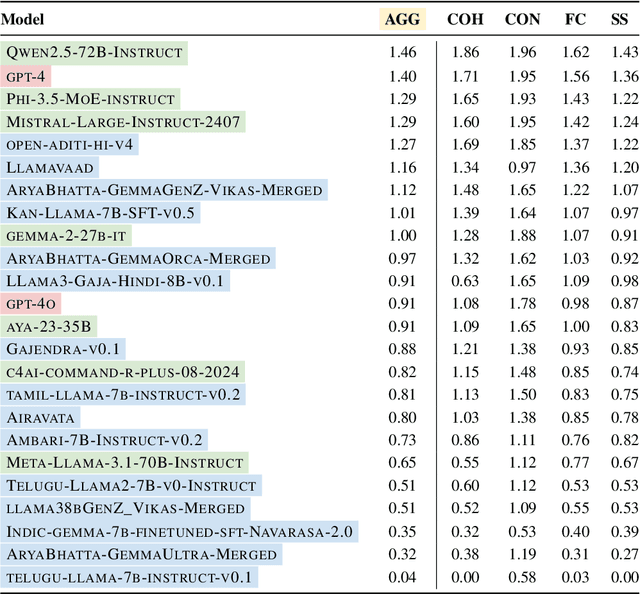
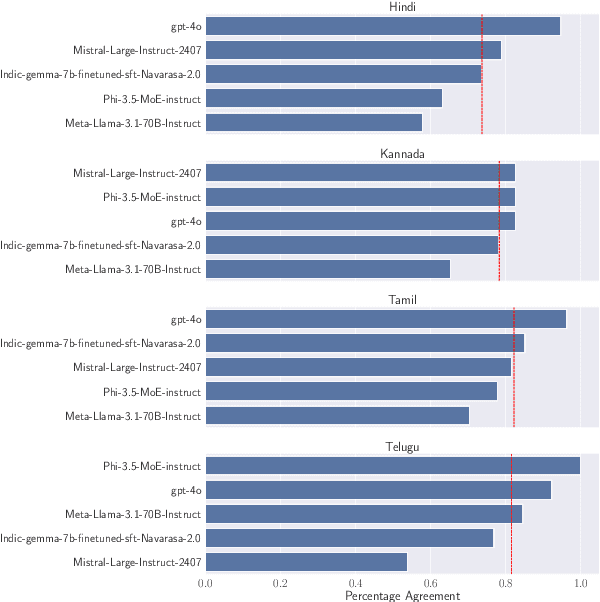
Evaluation of multilingual Large Language Models (LLMs) is challenging due to a variety of factors -- the lack of benchmarks with sufficient linguistic diversity, contamination of popular benchmarks into LLM pre-training data and the lack of local, cultural nuances in translated benchmarks. In this work, we study human and LLM-based evaluation in a multilingual, multi-cultural setting. We evaluate 30 models across 10 Indic languages by conducting 90K human evaluations and 30K LLM-based evaluations and find that models such as GPT-4o and Llama-3 70B consistently perform best for most Indic languages. We build leaderboards for two evaluation settings - pairwise comparison and direct assessment and analyse the agreement between humans and LLMs. We find that humans and LLMs agree fairly well in the pairwise setting but the agreement drops for direct assessment evaluation especially for languages such as Bengali and Odia. We also check for various biases in human and LLM-based evaluation and find evidence of self-bias in the GPT-based evaluator. Our work presents a significant step towards scaling up multilingual evaluation of LLMs.
Beyond Metrics: Evaluating LLMs' Effectiveness in Culturally Nuanced, Low-Resource Real-World Scenarios
Jun 01, 2024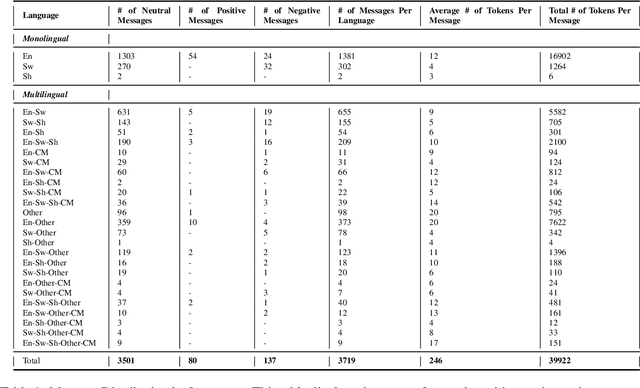
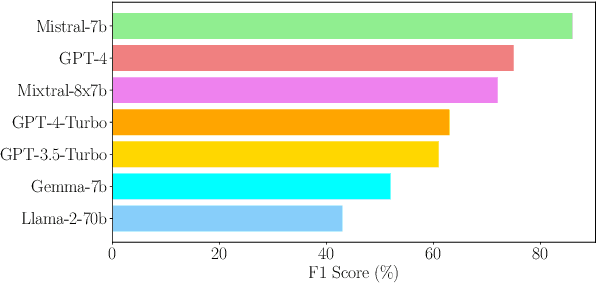
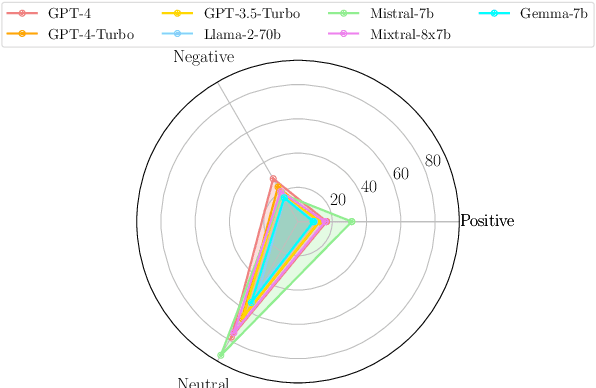
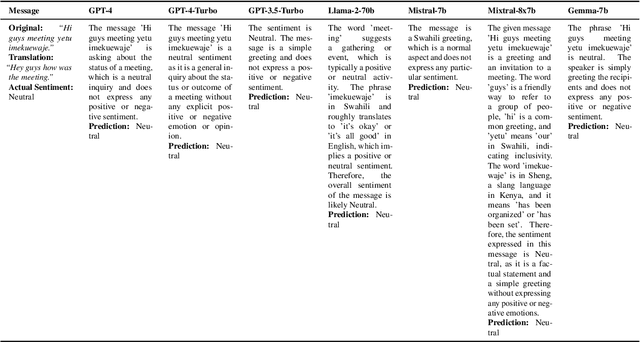
The deployment of Large Language Models (LLMs) in real-world applications presents both opportunities and challenges, particularly in multilingual and code-mixed communication settings. This research evaluates the performance of seven leading LLMs in sentiment analysis on a dataset derived from multilingual and code-mixed WhatsApp chats, including Swahili, English and Sheng. Our evaluation includes both quantitative analysis using metrics like F1 score and qualitative assessment of LLMs' explanations for their predictions. We find that, while Mistral-7b and Mixtral-8x7b achieved high F1 scores, they and other LLMs such as GPT-3.5-Turbo, Llama-2-70b, and Gemma-7b struggled with understanding linguistic and contextual nuances, as well as lack of transparency in their decision-making process as observed from their explanations. In contrast, GPT-4 and GPT-4-Turbo excelled in grasping diverse linguistic inputs and managing various contextual information, demonstrating high consistency with human alignment and transparency in their decision-making process. The LLMs however, encountered difficulties in incorporating cultural nuance especially in non-English settings with GPT-4s doing so inconsistently. The findings emphasize the necessity of continuous improvement of LLMs to effectively tackle the challenges of culturally nuanced, low-resource real-world settings.
Akal Badi ya Bias: An Exploratory Study of Gender Bias in Hindi Language Technology
May 10, 2024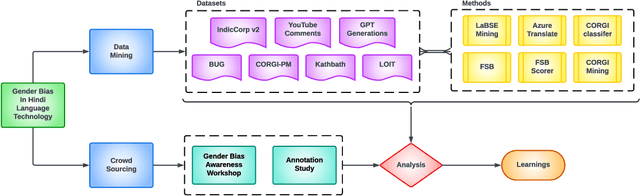

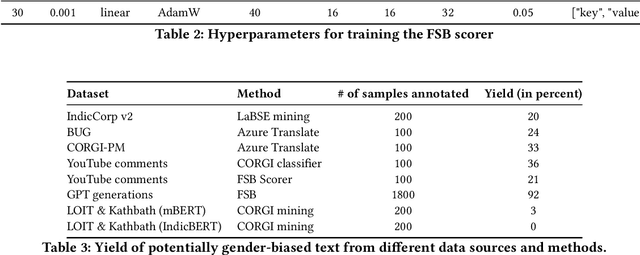
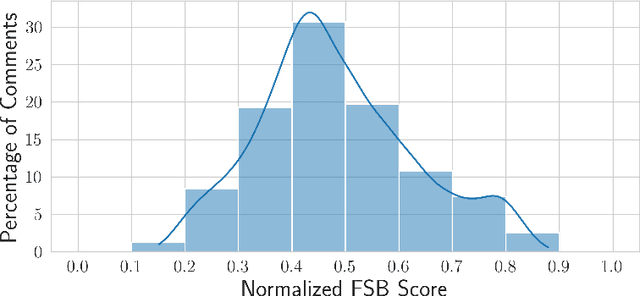
Existing research in measuring and mitigating gender bias predominantly centers on English, overlooking the intricate challenges posed by non-English languages and the Global South. This paper presents the first comprehensive study delving into the nuanced landscape of gender bias in Hindi, the third most spoken language globally. Our study employs diverse mining techniques, computational models, field studies and sheds light on the limitations of current methodologies. Given the challenges faced with mining gender biased statements in Hindi using existing methods, we conducted field studies to bootstrap the collection of such sentences. Through field studies involving rural and low-income community women, we uncover diverse perceptions of gender bias, underscoring the necessity for context-specific approaches. This paper advocates for a community-centric research design, amplifying voices often marginalized in previous studies. Our findings not only contribute to the understanding of gender bias in Hindi but also establish a foundation for further exploration of Indic languages. By exploring the intricacies of this understudied context, we call for thoughtful engagement with gender bias, promoting inclusivity and equity in linguistic and cultural contexts beyond the Global North.
METAL: Towards Multilingual Meta-Evaluation
Apr 02, 2024



With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
MAFIA: Multi-Adapter Fused Inclusive LanguAge Models
Feb 12, 2024



Pretrained Language Models (PLMs) are widely used in NLP for various tasks. Recent studies have identified various biases that such models exhibit and have proposed methods to correct these biases. However, most of the works address a limited set of bias dimensions independently such as gender, race, or religion. Moreover, the methods typically involve finetuning the full model to maintain the performance on the downstream task. In this work, we aim to modularly debias a pretrained language model across multiple dimensions. Previous works extensively explored debiasing PLMs using limited US-centric counterfactual data augmentation (CDA). We use structured knowledge and a large generative model to build a diverse CDA across multiple bias dimensions in a semi-automated way. We highlight how existing debiasing methods do not consider interactions between multiple societal biases and propose a debiasing model that exploits the synergy amongst various societal biases and enables multi-bias debiasing simultaneously. An extensive evaluation on multiple tasks and languages demonstrates the efficacy of our approach.
MunTTS: A Text-to-Speech System for Mundari
Jan 28, 2024



We present MunTTS, an end-to-end text-to-speech (TTS) system specifically for Mundari, a low-resource Indian language of the Austo-Asiatic family. Our work addresses the gap in linguistic technology for underrepresented languages by collecting and processing data to build a speech synthesis system. We begin our study by gathering a substantial dataset of Mundari text and speech and train end-to-end speech models. We also delve into the methods used for training our models, ensuring they are efficient and effective despite the data constraints. We evaluate our system with native speakers and objective metrics, demonstrating its potential as a tool for preserving and promoting the Mundari language in the digital age.