 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARIKSHA : A Large-Scale Investigation of Human-LLM Evaluator Agreement on Multilingual and Multi-Cultural Data
Jun 21, 2024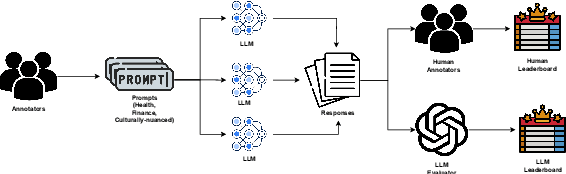
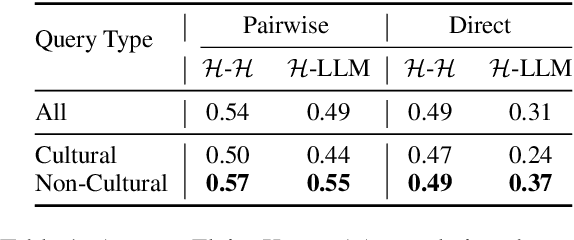
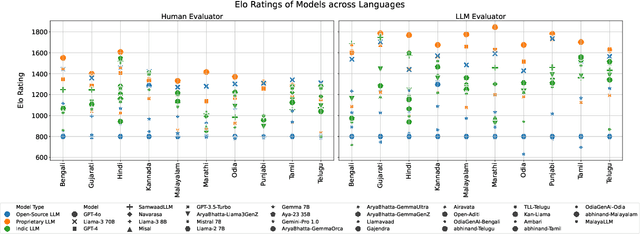
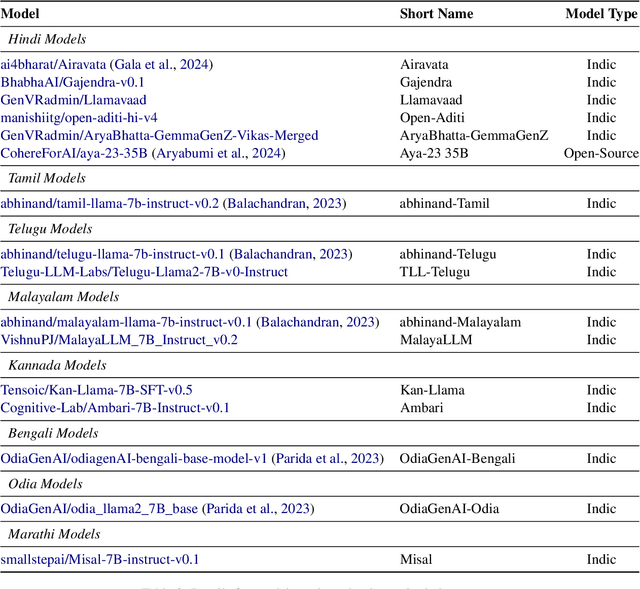
Evaluation of multilingual Large Language Models (LLMs) is challenging due to a variety of factors -- the lack of benchmarks with sufficient linguistic diversity, contamination of popular benchmarks into LLM pre-training data and the lack of local, cultural nuances in translated benchmarks. In this work, we study human and LLM-based evaluation in a multilingual, multi-cultural setting. We evaluate 30 models across 10 Indic languages by conducting 90K human evaluations and 30K LLM-based evaluations and find that models such as GPT-4o and Llama-3 70B consistently perform best for most Indic languages. We build leaderboards for two evaluation settings - pairwise comparison and direct assessment and analyse the agreement between humans and LLMs. We find that humans and LLMs agree fairly well in the pairwise setting but the agreement drops for direct assessment evaluation especially for languages such as Bengali and Odia. We also check for various biases in human and LLM-based evaluation and find evidence of self-bias in the GPT-based evaluator. Our work presents a significant step towards scaling up multilingual evaluation of LLMs.
Private Benchmarking to Prevent Contamination and Improve Comparative Evaluation of LLMs
Mar 01, 2024Benchmarking is the de-facto standard for evaluating LLMs, due to its speed, replicability and low cost. However, recent work has pointed out that the majority of the open source benchmarks available today have been contaminated or leaked into LLMs, meaning that LLMs have access to test data during pretraining and/or fine-tuning. This raises serious concerns about the validity of benchmarking studies conducted so far and the future of evaluation using benchmarks. To solve this problem, we propose Private Benchmarking, a solution where test datasets are kept private and models are evaluated without revealing the test data to the model. We describe various scenarios (depending on the trust placed on model owners or dataset owners), and present solutions to avoid data contamination using private benchmarking. For scenarios where the model weights need to be kept private, we describe solutions from confidential computing and cryptography that can aid in private benchmarking. Finally, we present solutions the problem of benchmark dataset auditing, to ensure that private benchmarks are of sufficiently high quality.