 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Do Prosody and Text Convey? Characterizing How Meaningful Information is Distributed Across Multiple Channels
Dec 18, 2025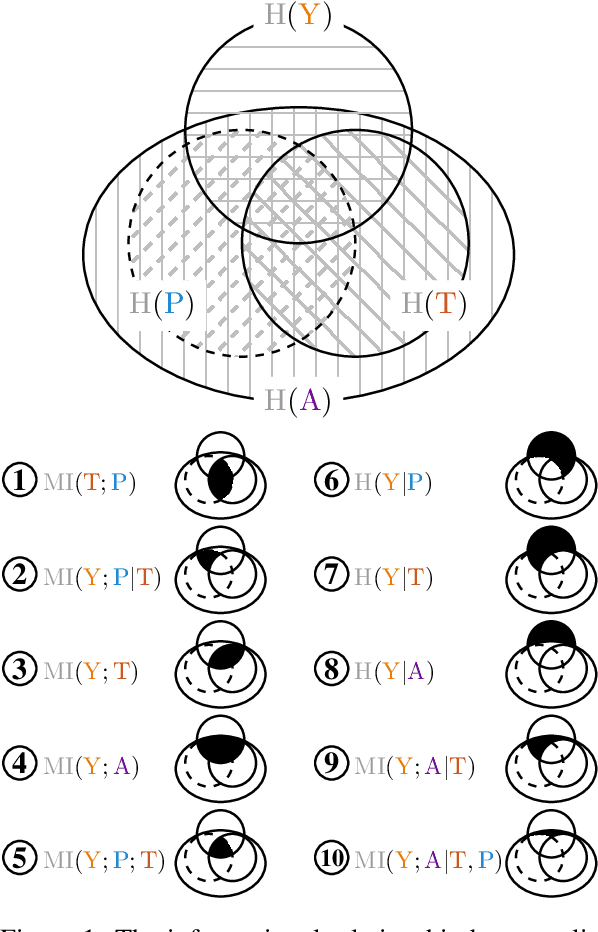
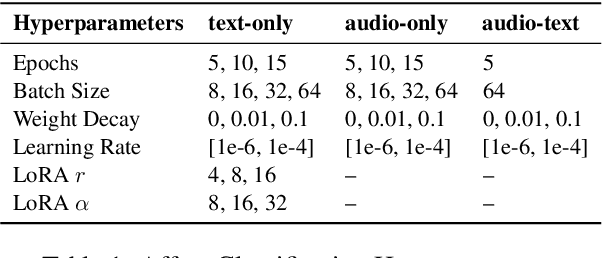
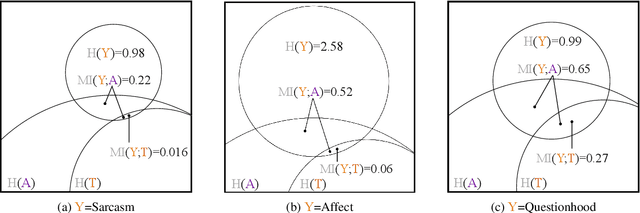
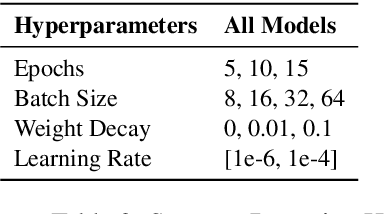
Prosody -- the melody of speech -- conveys critical information often not captured by the words or text of a message. In this paper, we propose an information-theoretic approach to quantify how much information is expressed by prosody alone and not by text, and crucially, what that information is about. Our approach applies large speech and language models to estimate the mutual information between a particular dimension of an utterance's meaning (e.g., its emotion) and any of its communication channels (e.g., audio or text). We then use this approach to quantify how much information is conveyed by audio and text about sarcasm, emotion, and questionhood, using speech from television and podcasts. We find that for sarcasm and emotion the audio channel -- and by implication the prosodic channel -- transmits over an order of magnitude more information about these features than the text channel alone, at least when long-term context beyond the current sentence is unavailable. For questionhood, prosody provides comparatively less additional information. We conclude by outlining a program applying our approach to more dimensions of meaning, communication channels, and languages.
PARIKSHA : A Large-Scale Investigation of Human-LLM Evaluator Agreement on Multilingual and Multi-Cultural Data
Jun 21, 2024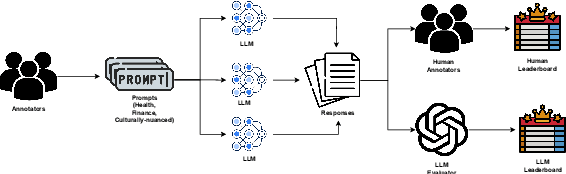
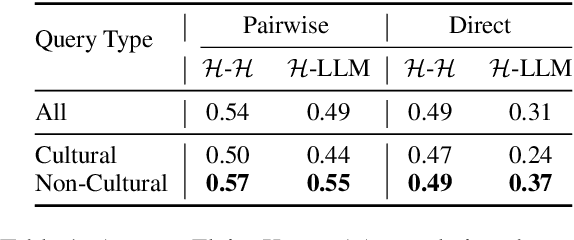
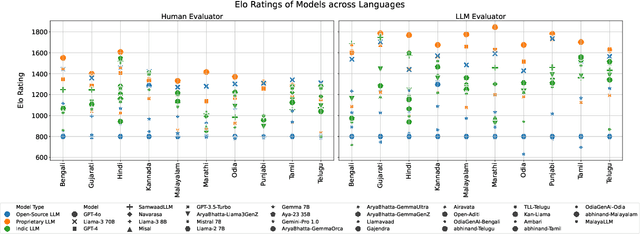
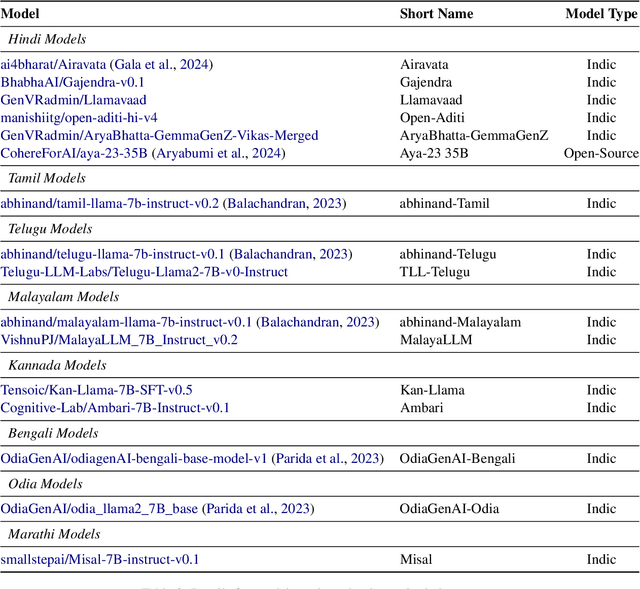
Evaluation of multilingual Large Language Models (LLMs) is challenging due to a variety of factors -- the lack of benchmarks with sufficient linguistic diversity, contamination of popular benchmarks into LLM pre-training data and the lack of local, cultural nuances in translated benchmarks. In this work, we study human and LLM-based evaluation in a multilingual, multi-cultural setting. We evaluate 30 models across 10 Indic languages by conducting 90K human evaluations and 30K LLM-based evaluations and find that models such as GPT-4o and Llama-3 70B consistently perform best for most Indic languages. We build leaderboards for two evaluation settings - pairwise comparison and direct assessment and analyse the agreement between humans and LLMs. We find that humans and LLMs agree fairly well in the pairwise setting but the agreement drops for direct assessment evaluation especially for languages such as Bengali and Odia. We also check for various biases in human and LLM-based evaluation and find evidence of self-bias in the GPT-based evaluator. Our work presents a significant step towards scaling up multilingual evaluation of LLMs.
Akal Badi ya Bias: An Exploratory Study of Gender Bias in Hindi Language Technology
May 10, 2024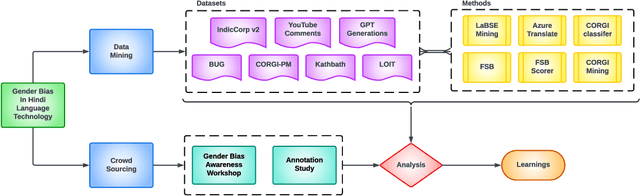

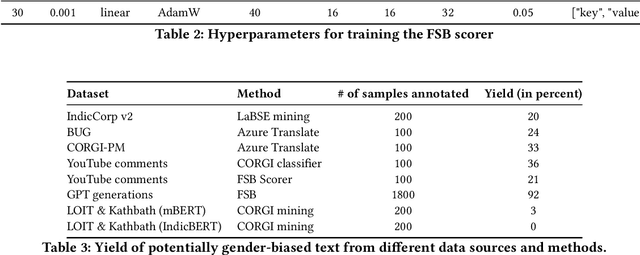
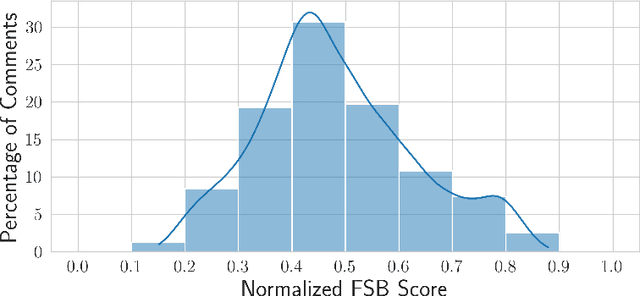
Existing research in measuring and mitigating gender bias predominantly centers on English, overlooking the intricate challenges posed by non-English languages and the Global South. This paper presents the first comprehensive study delving into the nuanced landscape of gender bias in Hindi, the third most spoken language globally. Our study employs diverse mining techniques, computational models, field studies and sheds light on the limitations of current methodologies. Given the challenges faced with mining gender biased statements in Hindi using existing methods, we conducted field studies to bootstrap the collection of such sentences. Through field studies involving rural and low-income community women, we uncover diverse perceptions of gender bias, underscoring the necessity for context-specific approaches. This paper advocates for a community-centric research design, amplifying voices often marginalized in previous studies. Our findings not only contribute to the understanding of gender bias in Hindi but also establish a foundation for further exploration of Indic languages. By exploring the intricacies of this understudied context, we call for thoughtful engagement with gender bias, promoting inclusivity and equity in linguistic and cultural contexts beyond the Global North.
AccentFold: A Journey through African Accents for Zero-Shot ASR Adaptation to Target Accents
Feb 05, 2024Despite advancements in speech recognition, accented speech remains challenging. While previous approaches have focused on modeling techniques or creating accented speech datasets, gathering sufficient data for the multitude of accents, particularly in the African context, remains impractical due to their sheer diversity and associated budget constraints. To address these challenges, we propose AccentFold, a method that exploits spatial relationships between learned accent embeddings to improve downstream Automatic Speech Recognition (ASR). Our exploratory analysis of speech embeddings representing 100+ African accents reveals interesting spatial accent relationships highlighting geographic and genealogical similarities, capturing consistent phonological, and morphological regularities, all learned empirically from speech. Furthermore, we discover accent relationships previously uncharacterized by the Ethnologue. Through empirical evaluation, we demonstrate the effectiveness of AccentFold by showing that, for out-of-distribution (OOD) accents, sampling accent subsets for training based on AccentFold information outperforms strong baselines a relative WER improvement of 4.6%. AccentFold presents a promising approach for improving ASR performance on accented speech, particularly in the context of African accents, where data scarcity and budget constraints pose significant challenges. Our findings emphasize the potential of leveraging linguistic relationships to improve zero-shot ASR adaptation to target accents.
MunTTS: A Text-to-Speech System for Mundari
Jan 28, 2024



We present MunTTS, an end-to-end text-to-speech (TTS) system specifically for Mundari, a low-resource Indian language of the Austo-Asiatic family. Our work addresses the gap in linguistic technology for underrepresented languages by collecting and processing data to build a speech synthesis system. We begin our study by gathering a substantial dataset of Mundari text and speech and train end-to-end speech models. We also delve into the methods used for training our models, ensuring they are efficient and effective despite the data constraints. We evaluate our system with native speakers and objective metrics, demonstrating its potential as a tool for preserving and promoting the Mundari language in the digital age.
AfriSpeech-200: Pan-African Accented Speech Dataset for Clinical and General Domain ASR
Sep 30, 2023Africa has a very low doctor-to-patient ratio. At very busy clinics, doctors could see 30+ patients per day -- a heavy patient burden compared with developed countries -- but productivity tools such as clinical automatic speech recognition (ASR) are lacking for these overworked clinicians. However, clinical ASR is mature, even ubiquitous, in developed nations, and clinician-reported performance of commercial clinical ASR systems is generally satisfactory. Furthermore, the recent performance of general domain ASR is approaching human accuracy. However, several gaps exist. Several publications have highlighted racial bias with speech-to-text algorithms and performance on minority accents lags significantly. To our knowledge, there is no publicly available research or benchmark on accented African clinical ASR, and speech data is non-existent for the majority of African accents. We release AfriSpeech, 200hrs of Pan-African English speech, 67,577 clips from 2,463 unique speakers across 120 indigenous accents from 13 countries for clinical and general domain ASR, a benchmark test set, with publicly available pre-trained models with SOTA performance on the AfriSpeech benchmark.
X-RiSAWOZ: High-Quality End-to-End Multilingual Dialogue Datasets and Few-shot Agents
Jun 30, 2023



Task-oriented dialogue research has mainly focused on a few popular languages like English and Chinese, due to the high dataset creation cost for a new language. To reduce the cost, we apply manual editing to automatically translated data. We create a new multilingual benchmark, X-RiSAWOZ, by translating the Chinese RiSAWOZ to 4 languages: English, French, Hindi, Korean; and a code-mixed English-Hindi language. X-RiSAWOZ has more than 18,000 human-verified dialogue utterances for each language, and unlike most multilingual prior work, is an end-to-end dataset for building fully-functioning agents. The many difficulties we encountered in creating X-RiSAWOZ led us to develop a toolset to accelerate the post-editing of a new language dataset after translation. This toolset improves machine translation with a hybrid entity alignment technique that combines neural with dictionary-based methods, along with many automated and semi-automated validation checks. We establish strong baselines for X-RiSAWOZ by training dialogue agents in the zero- and few-shot settings where limited gold data is available in the target language. Our results suggest that our translation and post-editing methodology and toolset can be used to create new high-quality multilingual dialogue agents cost-effectively. Our dataset, code, and toolkit are released open-source.
SLABERT Talk Pretty One Day: Modeling Second Language Acquisition with BERT
May 31, 2023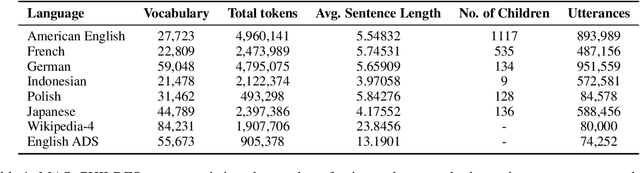
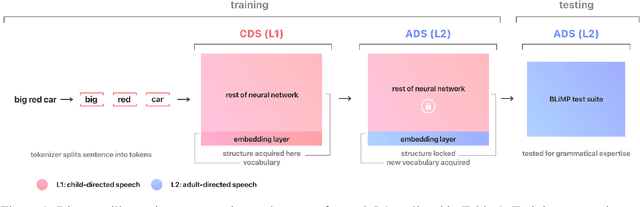
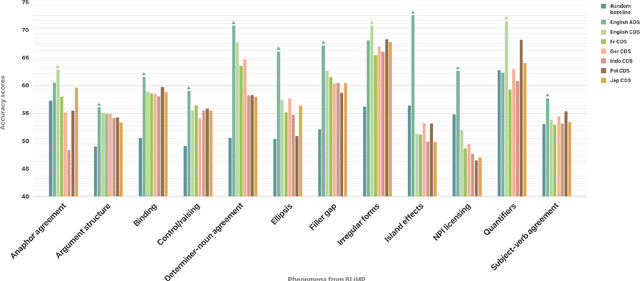
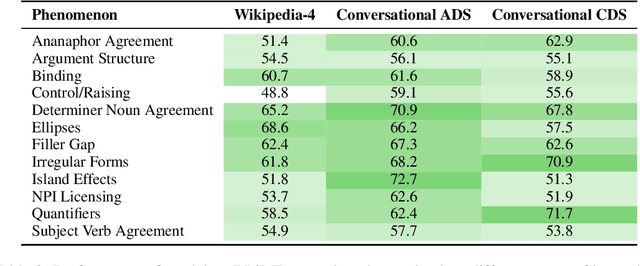
Second language acquisition (SLA) research has extensively studied cross-linguistic transfer, the influence of linguistic structure of a speaker's native language [L1] on the successful acquisition of a foreign language [L2]. Effects of such transfer can be positive (facilitating acquisition) or negative (impeding acquisition). We find that NLP literature has not given enough attention to the phenomenon of negative transfer. To understand patterns of both positive and negative transfer between L1 and L2, we model sequential second language acquisition in LMs. Further, we build a Mutlilingual Age Ordered CHILDES (MAO-CHILDES) -- a dataset consisting of 5 typologically diverse languages, i.e., German, French, Polish, Indonesian, and Japanese -- to understand the degree to which native Child-Directed Speech (CDS) [L1] can help or conflict with English language acquisition [L2]. To examine the impact of native CDS, we use the TILT-based cross lingual transfer learning approach established by Papadimitriou and Jurafsky (2020) and find that, as in human SLA, language family distance predicts more negative transfer. Additionally, we find that conversational speech data shows greater facilitation for language acquisition than scripted speech data. Our findings call for further research using our novel Transformer-based SLA models and we would like to encourage it by releasing our code, data, and models.