 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfrIFact: Cultural Information Retrieval, Evidence Extraction and Fact Checking for African Languages
Apr 01, 2026Assessing the veracity of a claim made online is a complex and important task with real-world implications. When these claims are directed at communities with limited access to information and the content concerns issues such as healthcare and culture, the consequences intensify, especially in low-resource languages. In this work, we introduce AfrIFact, a dataset that covers the necessary steps for automatic fact-checking (i.e., information retrieval, evidence extraction, and fact checking), in ten African languages and English. Our evaluation results show that even the best embedding models lack cross-lingual retrieval capabilities, and that cultural and news documents are easier to retrieve than healthcare-domain documents, both in large corpora and in single documents. We show that LLMs lack robust multilingual fact-verification capabilities in African languages, while few-shot prompting improves performance by up to 43% in AfriqueQwen-14B, and task-specific fine-tuning further improves fact-checking accuracy by up to 26%. These findings, along with our release of the AfrIFact dataset, encourage work on low-resource information retrieval, evidence retrieval, and fact checking.
AfriHate: A Multilingual Collection of Hate Speech and Abusive Language Datasets for African Languages
Jan 15, 2025



Hate speech and abusive language are global phenomena that need socio-cultural background knowledge to be understood, identified, and moderated. However, in many regions of the Global South, there have been several documented occurrences of (1) absence of moderation and (2) censorship due to the reliance on keyword spotting out of context. Further, high-profile individuals have frequently been at the center of the moderation process, while large and targeted hate speech campaigns against minorities have been overlooked. These limitations are mainly due to the lack of high-quality data in the local languages and the failure to include local communities in the collection, annotation, and moderation processes. To address this issue, we present AfriHate: a multilingual collection of hate speech and abusive language datasets in 15 African languages. Each instance in AfriHate is annotated by native speakers familiar with the local culture. We report the challenges related to the construction of the datasets and present various classification baseline results with and without using LLMs. The datasets, individual annotations, and hate speech and offensive language lexicons are available on https://github.com/AfriHate/AfriHate
IrokoBench: A New Benchmark for African Languages in the Age of Large Language Models
Jun 05, 2024

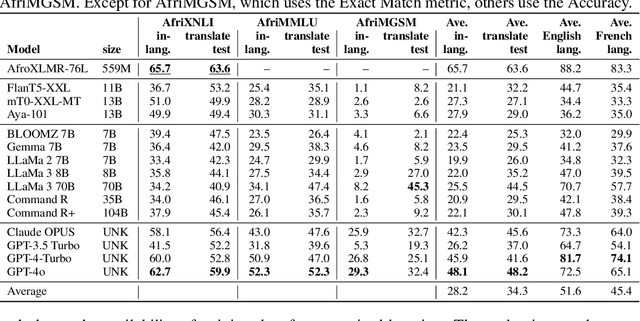
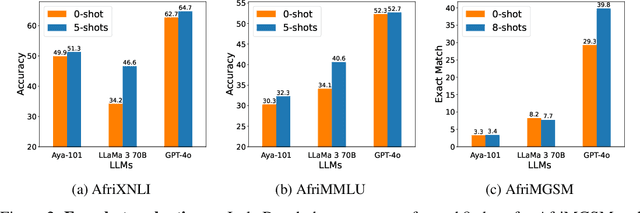
Despite the widespread adoption of Large language models (LLMs), their remarkable capabilities remain limited to a few high-resource languages. Additionally, many low-resource languages (e.g. African languages) are often evaluated only on basic text classification tasks due to the lack of appropriate or comprehensive benchmarks outside of high-resource languages. In this paper, we introduce IrokoBench -- a human-translated benchmark dataset for 16 typologically-diverse low-resource African languages covering three tasks: natural language inference~(AfriXNLI), mathematical reasoning~(AfriMGSM), and multi-choice knowledge-based QA~(AfriMMLU). We use IrokoBench to evaluate zero-shot, few-shot, and translate-test settings~(where test sets are translated into English) across 10 open and four proprietary LLMs. Our evaluation reveals a significant performance gap between high-resource languages~(such as English and French) and low-resource African languages. We observe a significant performance gap between open and proprietary models, with the highest performing open model, Aya-101 only at 58\% of the best-performing proprietary model GPT-4o performance. Machine translating the test set to English before evaluation helped to close the gap for larger models that are English-centric, like LLaMa 3 70B. These findings suggest that more efforts are needed to develop and adapt LLMs for African languages.
AfriMTE and AfriCOMET: Empowering COMET to Embrace Under-resourced African Languages
Nov 16, 2023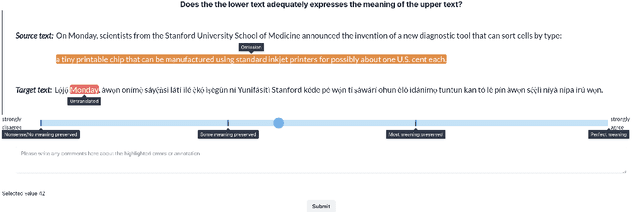
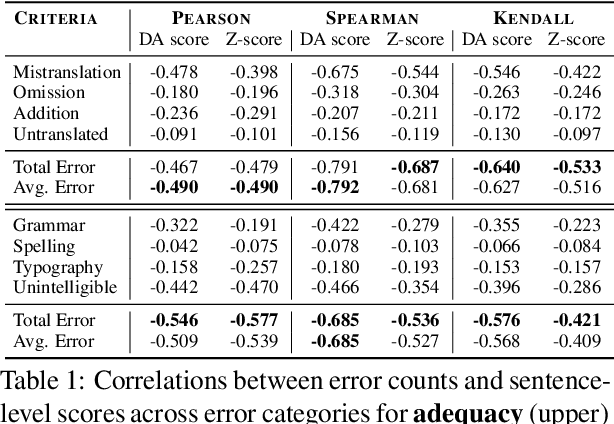
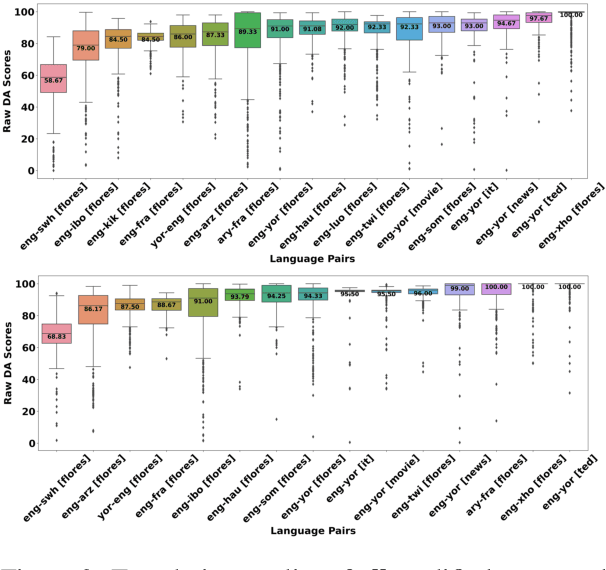
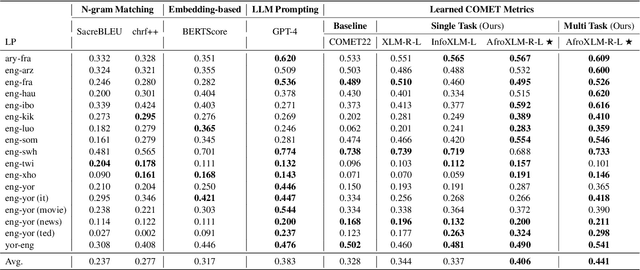
Despite the progress we have recorded in scaling multilingual machine translation (MT) models and evaluation data to several under-resourced African languages, it is difficult to measure accurately the progress we have made on these languages because evaluation is often performed on n-gram matching metrics like BLEU that often have worse correlation with human judgments. Embedding-based metrics such as COMET correlate better; however, lack of evaluation data with human ratings for under-resourced languages, complexity of annotation guidelines like Multidimensional Quality Metrics (MQM), and limited language coverage of multilingual encoders have hampered their applicability to African languages. In this paper, we address these challenges by creating high-quality human evaluation data with a simplified MQM guideline for error-span annotation and direct assessment (DA) scoring for 13 typologically diverse African languages. Furthermore, we develop AfriCOMET, a COMET evaluation metric for African languages by leveraging DA training data from high-resource languages and African-centric multilingual encoder (AfroXLM-Roberta) to create the state-of-the-art evaluation metric for African languages MT with respect to Spearman-rank correlation with human judgments (+0.406).
AfriSpeech-200: Pan-African Accented Speech Dataset for Clinical and General Domain ASR
Sep 30, 2023Africa has a very low doctor-to-patient ratio. At very busy clinics, doctors could see 30+ patients per day -- a heavy patient burden compared with developed countries -- but productivity tools such as clinical automatic speech recognition (ASR) are lacking for these overworked clinicians. However, clinical ASR is mature, even ubiquitous, in developed nations, and clinician-reported performance of commercial clinical ASR systems is generally satisfactory. Furthermore, the recent performance of general domain ASR is approaching human accuracy. However, several gaps exist. Several publications have highlighted racial bias with speech-to-text algorithms and performance on minority accents lags significantly. To our knowledge, there is no publicly available research or benchmark on accented African clinical ASR, and speech data is non-existent for the majority of African accents. We release AfriSpeech, 200hrs of Pan-African English speech, 67,577 clips from 2,463 unique speakers across 120 indigenous accents from 13 countries for clinical and general domain ASR, a benchmark test set, with publicly available pre-trained models with SOTA performance on the AfriSpeech benchmark.
Adapting Pretrained ASR Models to Low-resource Clinical Speech using Epistemic Uncertainty-based Data Selection
Jun 03, 2023While there has been significant progress in ASR, African-accented clinical ASR has been understudied due to a lack of training datasets. Building robust ASR systems in this domain requires large amounts of annotated or labeled data, for a wide variety of linguistically and morphologically rich accents, which are expensive to create. Our study aims to address this problem by reducing annotation expenses through informative uncertainty-based data selection. We show that incorporating epistemic uncertainty into our adaptation rounds outperforms several baseline results, established using state-of-the-art (SOTA) ASR models, while reducing the required amount of labeled data, and hence reducing annotation costs. Our approach also improves out-of-distribution generalization for very low-resource accents, demonstrating the viability of our approach for building generalizable ASR models in the context of accented African clinical ASR, where training datasets are predominantly scarce.
AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages
May 11, 2023



African languages have far less in-language content available digitally, making it challenging for question answering systems to satisfy the information needs of users. Cross-lingual open-retrieval question answering (XOR QA) systems -- those that retrieve answer content from other languages while serving people in their native language -- offer a means of filling this gap. To this end, we create AfriQA, the first cross-lingual QA dataset with a focus on African languages. AfriQA includes 12,000+ XOR QA examples across 10 African languages. While previous datasets have focused primarily on languages where cross-lingual QA augments coverage from the target language, AfriQA focuses on languages where cross-lingual answer content is the only high-coverage source of answer content. Because of this, we argue that African languages are one of the most important and realistic use cases for XOR QA. Our experiments demonstrate the poor performance of automatic translation and multilingual retrieval methods. Overall, AfriQA proves challenging for state-of-the-art QA models. We hope that the dataset enables the development of more equitable QA technology.
AfriSenti: A Twitter Sentiment Analysis Benchmark for African Languages
Feb 17, 2023



Africa is home to over 2000 languages from over six language families and has the highest linguistic diversity among all continents. This includes 75 languages with at least one million speakers each. Yet, there is little NLP research conducted on African languages. Crucial in enabling such research is the availability of high-quality annotated datasets. In this paper, we introduce AfriSenti, which consists of 14 sentiment datasets of 110,000+ tweets in 14 African languages (Amharic, Algerian Arabic, Hausa, Igbo, Kinyarwanda, Moroccan Arabic, Mozambican Portuguese, Nigerian Pidgin, Oromo, Swahili, Tigrinya, Twi, Xitsonga, and Yor\`ub\'a) from four language families annotated by native speakers. The data is used in SemEval 2023 Task 12, the first Afro-centric SemEval shared task. We describe the data collection methodology, annotation process, and related challenges when curating each of the datasets. We conduct experiments with different sentiment classification baselines and discuss their usefulness. We hope AfriSenti enables new work on under-represented languages. The dataset is available at https://github.com/afrisenti-semeval/afrisent-semeval-2023 and can also be loaded as a huggingface datasets (https://huggingface.co/datasets/shmuhammad/AfriSenti).
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
AfroLM: A Self-Active Learning-based Multilingual Pretrained Language Model for 23 African Languages
Nov 07, 2022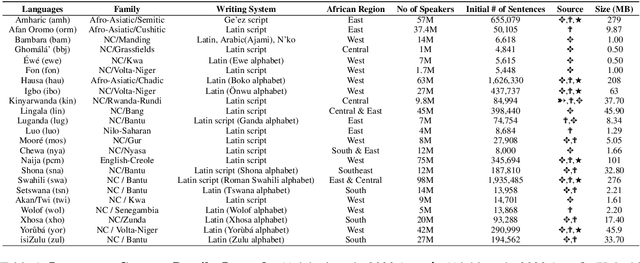
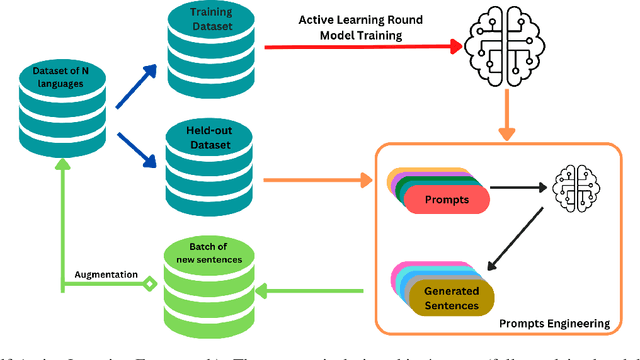


In recent years, multilingual pre-trained language models have gained prominence due to their remarkable performance on numerous downstream Natural Language Processing tasks (NLP). However, pre-training these large multilingual language models requires a lot of training data, which is not available for African Languages. Active learning is a semi-supervised learning algorithm, in which a model consistently and dynamically learns to identify the most beneficial samples to train itself on, in order to achieve better optimization and performance on downstream tasks. Furthermore, active learning effectively and practically addresses real-world data scarcity. Despite all its benefits, active learning, in the context of NLP and especially multilingual language models pretraining, has received little consideration. In this paper, we present AfroLM, a multilingual language model pretrained from scratch on 23 African languages (the largest effort to date) using our novel self-active learning framework. Pretrained on a dataset significantly (14x) smaller than existing baselines, AfroLM outperforms many multilingual pretrained language models (AfriBERTa, XLMR-base, mBERT) on various NLP downstream tasks (NER, text classification, and sentiment analysis). Additional out-of-domain sentiment analysis experiments show that \textbf{AfroLM} is able to generalize well across various domains. We release the code source, and our datasets used in our framework at https://github.com/bonaventuredossou/MLM_AL.