 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Crate Digging: DJ Tool Retrieval Using Speech Activity, Music Structure And CLAP Embeddings
Nov 19, 2024In genres like Hip-Hop, RnB, Reggae, Dancehall and just about every Electronic/Dance/Club style, DJ tools are a special set of audio files curated to heighten the DJ's musical performance and creative mixing choices. In this work we demonstrate an approach to discovering DJ tools in personal music collections. Leveraging open-source libraries for speech/music activity, music boundary analysis and a Contrastive Language-Audio Pretraining (CLAP) model for zero-shot audio classification, we demonstrate a novel system designed to retrieve (or rediscover) compelling DJ tools for use live or in the studio.
Facing the Music: Tackling Singing Voice Separation in Cinematic Audio Source Separation
Aug 07, 2024Cinematic audio source separation (CASS) is a fairly new subtask of audio source separation. A typical setup of CASS is a three-stem problem, with the aim of separating the mixture into the dialogue stem (DX), music stem (MX), and effects stem (FX). In practice, however, several edge cases exist as some sound sources do not fit neatly in either of these three stems, necessitating the use of additional auxiliary stems in production. One very common edge case is the singing voice in film audio, which may belong in either the DX or MX, depending heavily on the cinematic context. In this work, we demonstrate a very straightforward extension of the dedicated-decoder Bandit and query-based single-decoder Banquet models to a four-stem problem, treating non-musical dialogue, instrumental music, singing voice, and effects as separate stems. Interestingly, the query-based Banquet model outperformed the dedicated-decoder Bandit model. We hypothesized that this is due to a better feature alignment at the bottleneck as enforced by the band-agnostic FiLM layer. Dataset and model implementation will be made available at https://github.com/kwatcharasupat/source-separation-landing.
Remastering Divide and Remaster: A Cinematic Audio Source Separation Dataset with Multilingual Support
Jul 09, 2024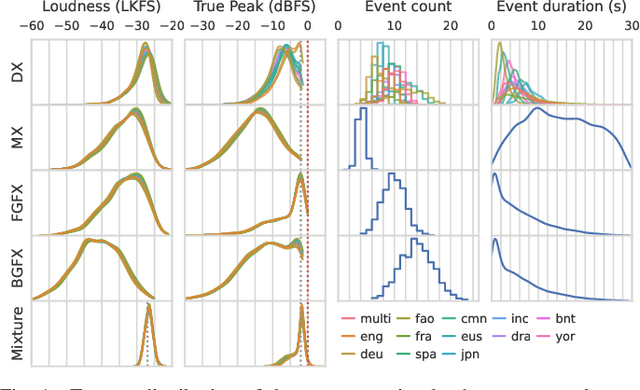
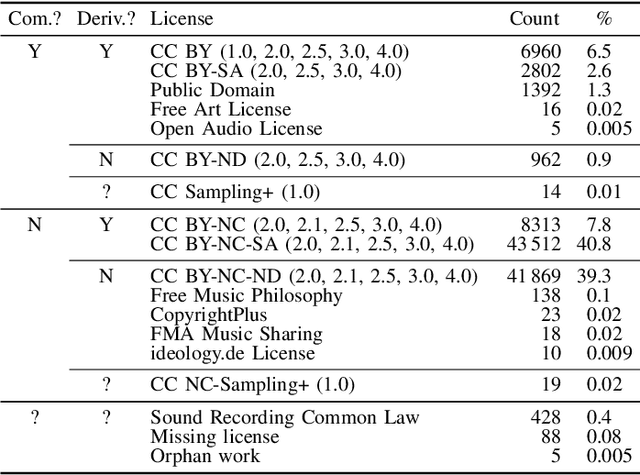
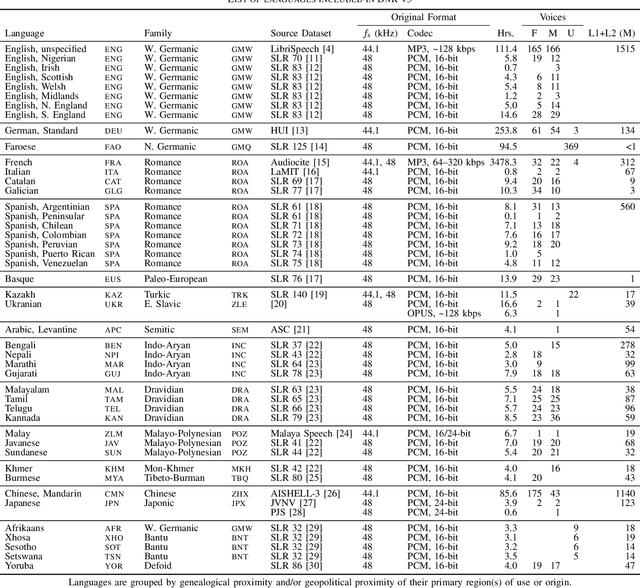
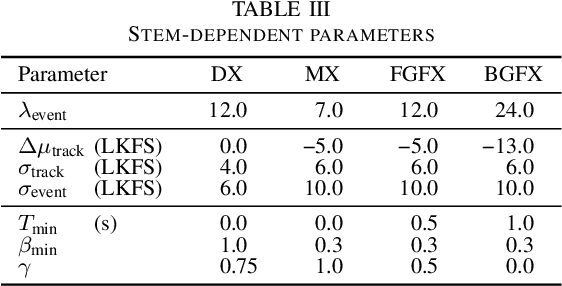
Cinematic audio source separation (CASS) is a relatively new subtask of audio source separation, concerned with the separation of a mixture into the dialogue, music, and effects stems. To date, only one publicly available dataset exists for CASS, that is, the Divide and Remaster (DnR) dataset, which is currently at version 2. While DnR v2 has been an incredibly useful resource for CASS, several areas of improvement have been identified, particularly through its use in the 2023 Sound Demixing Challenge. In this work, we develop version 3 of the DnR dataset, addressing issues relating to vocal content in non-dialogue stems, loudness distributions, mastering process, and linguistic diversity. In particular, the dialogue stem of DnR v3 includes speech content from more than 30 languages from multiple families including but not limited to the Germanic, Romance, Indo-Aryan, Dravidian, Malayo-Polynesian, and Bantu families. Benchmark results using the Bandit model indicated that training on multilingual data yields significant generalizability to the model even in languages with low data availability. Even in languages with high data availability, the multilingual model often performs on par or better than dedicated models trained on monolingual CASS datasets.
A Generalized Bandsplit Neural Network for Cinematic Audio Source Separation
Sep 07, 2023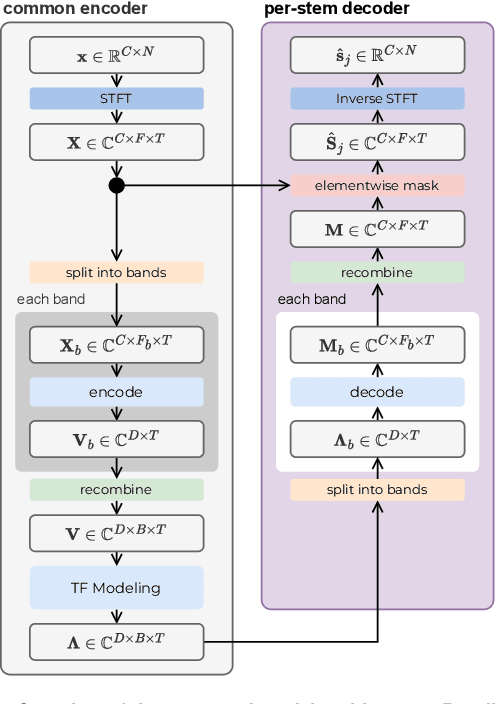
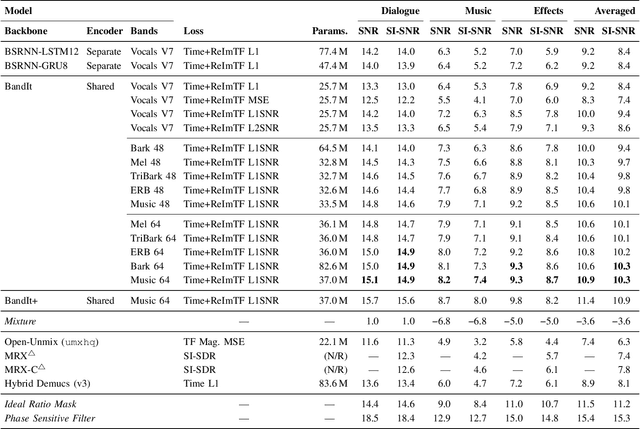
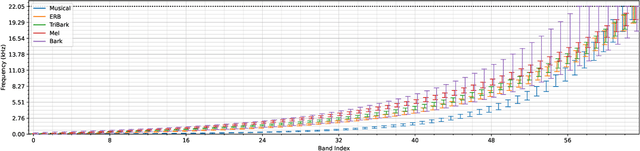

Cinematic audio source separation is a relatively new subtask of audio source separation, with the aim of extracting the dialogue stem, the music stem, and the effects stem from their mixture. In this work, we developed a model generalizing the Bandsplit RNN for any complete or overcomplete partitions of the frequency axis. Psycho-acoustically motivated frequency scales were used to inform the band definitions which are now defined with redundancy for more reliable feature extraction. A loss function motivated by the signal-to-noise ratio and the sparsity-promoting property of the 1-norm was proposed. We additionally exploit the information-sharing property of a common-encoder setup to reduce computational complexity during both training and inference, improve separation performance for hard-to-generalize classes of sounds, and allow flexibility during inference time with easily detachable decoders. Our best model sets the state of the art on the Divide and Remaster dataset with performance above the ideal ratio mask for the dialogue stem.
ÌròyìnSpeech: A multi-purpose Yorùbá Speech Corpus
Jul 29, 2023
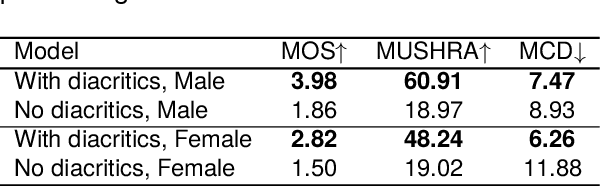
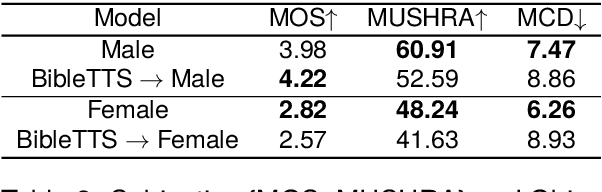
We introduce the \`{I}r\`{o}y\`{i}nSpeech corpus -- a new dataset influenced by a desire to increase the amount of high quality, freely available, contemporary Yor\`{u}b\'{a} speech. We release a multi-purpose dataset that can be used for both TTS and ASR tasks. We curated text sentences from the news and creative writing domains under an open license i.e., CC-BY-4.0 and had multiple speakers record each sentence. We provide 5000 of our utterances to the Common Voice platform to crowdsource transcriptions online. The dataset has 38.5 hours of data in total, recorded by 80 volunteers.
Looking Similar, Sounding Different: Leveraging Counterfactual Cross-Modal Pairs for Audiovisual Representation Learning
Apr 12, 2023

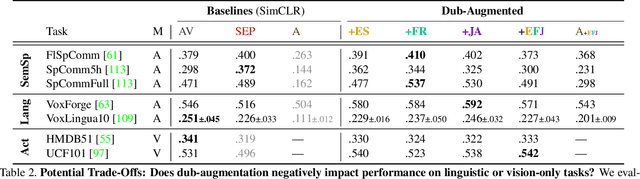

Audiovisual representation learning typically relies on the correspondence between sight and sound. However, there are often multiple audio tracks that can correspond with a visual scene. Consider, for example, different conversations on the same crowded street. The effect of such counterfactual pairs on audiovisual representation learning has not been previously explored. To investigate this, we use dubbed versions of movies to augment cross-modal contrastive learning. Our approach learns to represent alternate audio tracks, differing only in speech content, similarly to the same video. Our results show that dub-augmented training improves performance on a range of auditory and audiovisual tasks, without significantly affecting linguistic task performance overall. We additionally compare this approach to a strong baseline where we remove speech before pretraining, and find that dub-augmented training is more effective, including for paralinguistic and audiovisual tasks where speech removal leads to worse performance. These findings highlight the importance of considering speech variation when learning scene-level audiovisual correspondences and suggest that dubbed audio can be a useful augmentation technique for training audiovisual models toward more robust performance.
BibleTTS: a large, high-fidelity, multilingual, and uniquely African speech corpus
Jul 07, 2022
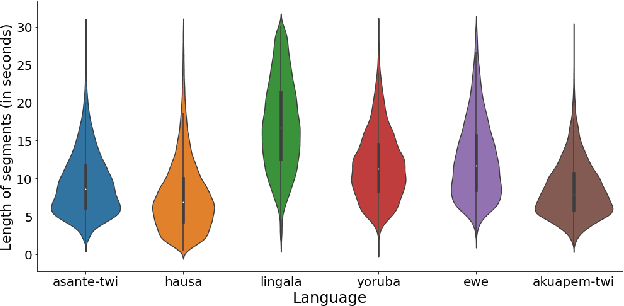

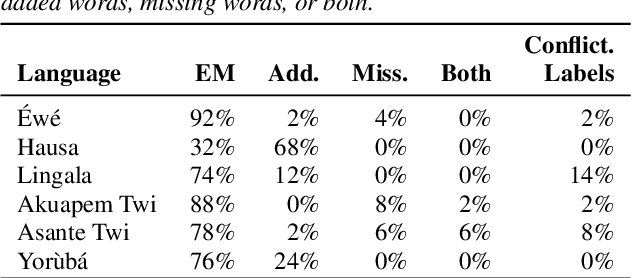
BibleTTS is a large, high-quality, open speech dataset for ten languages spoken in Sub-Saharan Africa. The corpus contains up to 86 hours of aligned, studio quality 48kHz single speaker recordings per language, enabling the development of high-quality text-to-speech models. The ten languages represented are: Akuapem Twi, Asante Twi, Chichewa, Ewe, Hausa, Kikuyu, Lingala, Luganda, Luo, and Yoruba. This corpus is a derivative work of Bible recordings made and released by the Open.Bible project from Biblica. We have aligned, cleaned, and filtered the original recordings, and additionally hand-checked a subset of the alignments for each language. We present results for text-to-speech models with Coqui TTS. The data is released under a commercial-friendly CC-BY-SA license.
Learning Nigerian accent embeddings from speech: preliminary results based on SautiDB-Naija corpus
Dec 12, 2021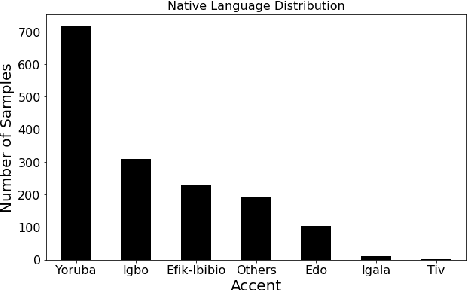
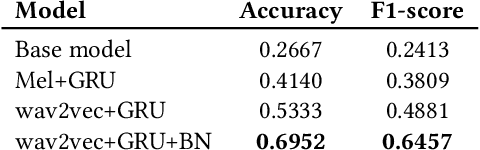
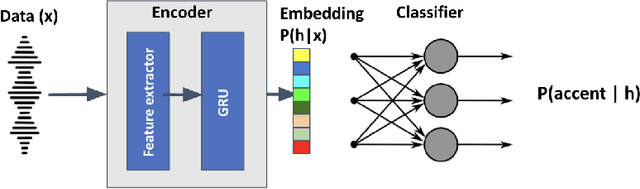
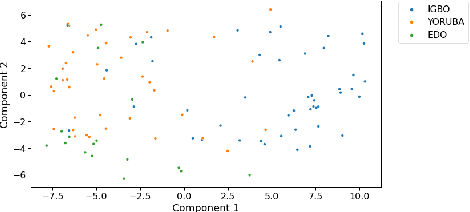
This paper describes foundational efforts with SautiDB-Naija, a novel corpus of non-native (L2) Nigerian English speech. We describe how the corpus was created and curated as well as preliminary experiments with accent classification and learning Nigerian accent embeddings. The initial version of the corpus includes over 900 recordings from L2 English speakers of Nigerian languages, such as Yoruba, Igbo, Edo, Efik-Ibibio, and Igala. We further demonstrate how fine-tuning on a pre-trained model like wav2vec can yield representations suitable for related speech tasks such as accent classification. SautiDB-Naija has been published to Zenodo for general use under a flexible Creative Commons License.
AVASpeech-SMAD: A Strongly Labelled Speech and Music Activity Detection Dataset with Label Co-Occurrence
Nov 02, 2021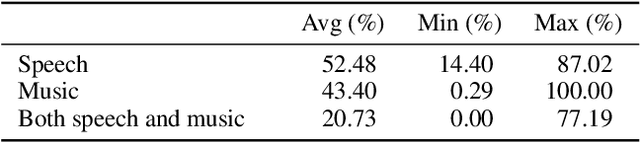
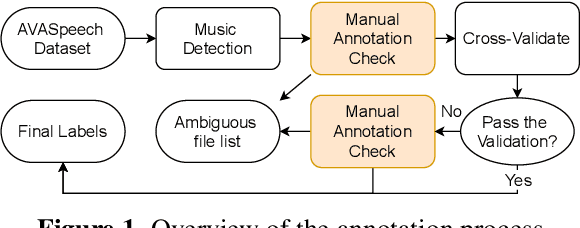

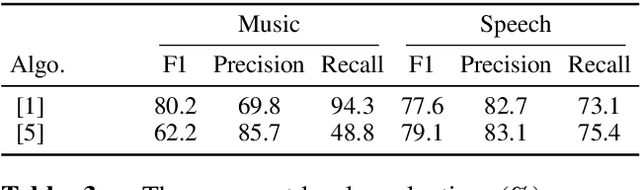
We propose a dataset, AVASpeech-SMAD, to assist speech and music activity detection research. With frame-level music labels, the proposed dataset extends the existing AVASpeech dataset, which originally consists of 45 hours of audio and speech activity labels. To the best of our knowledge, the proposed AVASpeech-SMAD is the first open-source dataset that features strong polyphonic labels for both music and speech. The dataset was manually annotated and verified via an iterative cross-checking process. A simple automatic examination was also implemented to further improve the quality of the labels. Evaluation results from two state-of-the-art SMAD systems are also provided as a benchmark for future reference.
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
Mar 22, 2021
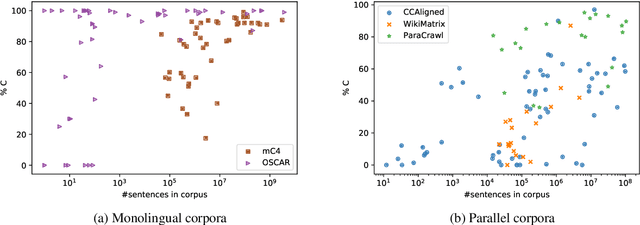

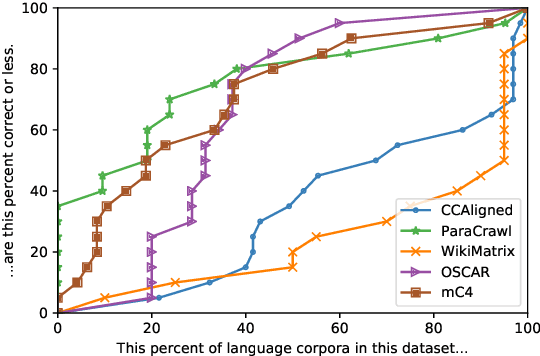
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, web-mined text datasets covering hundreds of languages. However, to date there has been no systematic analysis of the quality of these publicly available datasets, or whether the datasets actually contain content in the languages they claim to represent. In this work, we manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), and audit the correctness of language codes in a sixth (JW300). We find that lower-resource corpora have systematic issues: at least 15 corpora are completely erroneous, and a significant fraction contains less than 50% sentences of acceptable quality. Similarly, we find 82 corpora that are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-speakers of the languages in question, and supplement the human judgements with automatic analyses. Inspired by our analysis, we recommend techniques to evaluate and improve multilingual corpora and discuss the risks that come with low-quality data releases.