 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfriSpeech-200: Pan-African Accented Speech Dataset for Clinical and General Domain ASR
Sep 30, 2023Africa has a very low doctor-to-patient ratio. At very busy clinics, doctors could see 30+ patients per day -- a heavy patient burden compared with developed countries -- but productivity tools such as clinical automatic speech recognition (ASR) are lacking for these overworked clinicians. However, clinical ASR is mature, even ubiquitous, in developed nations, and clinician-reported performance of commercial clinical ASR systems is generally satisfactory. Furthermore, the recent performance of general domain ASR is approaching human accuracy. However, several gaps exist. Several publications have highlighted racial bias with speech-to-text algorithms and performance on minority accents lags significantly. To our knowledge, there is no publicly available research or benchmark on accented African clinical ASR, and speech data is non-existent for the majority of African accents. We release AfriSpeech, 200hrs of Pan-African English speech, 67,577 clips from 2,463 unique speakers across 120 indigenous accents from 13 countries for clinical and general domain ASR, a benchmark test set, with publicly available pre-trained models with SOTA performance on the AfriSpeech benchmark.
Learning Nigerian accent embeddings from speech: preliminary results based on SautiDB-Naija corpus
Dec 12, 2021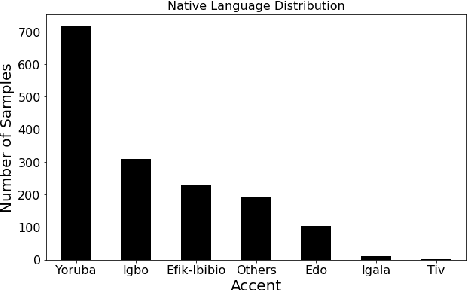
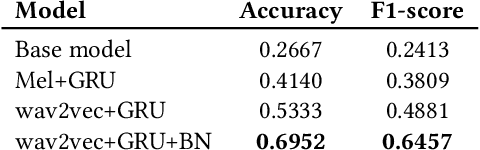
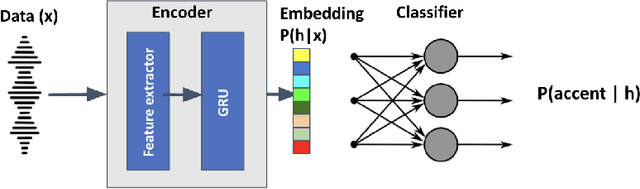
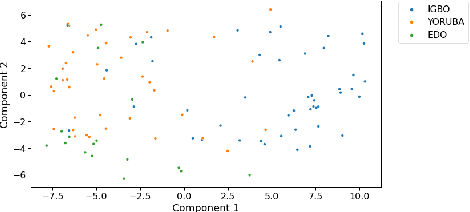
This paper describes foundational efforts with SautiDB-Naija, a novel corpus of non-native (L2) Nigerian English speech. We describe how the corpus was created and curated as well as preliminary experiments with accent classification and learning Nigerian accent embeddings. The initial version of the corpus includes over 900 recordings from L2 English speakers of Nigerian languages, such as Yoruba, Igbo, Edo, Efik-Ibibio, and Igala. We further demonstrate how fine-tuning on a pre-trained model like wav2vec can yield representations suitable for related speech tasks such as accent classification. SautiDB-Naija has been published to Zenodo for general use under a flexible Creative Commons License.