Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Nigerian accent embeddings from speech: preliminary results based on SautiDB-Naija corpus
Dec 12, 2021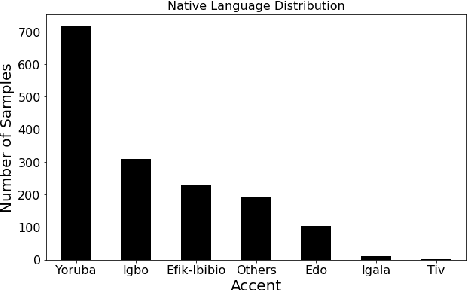
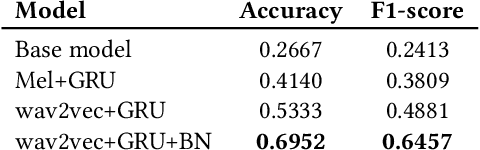
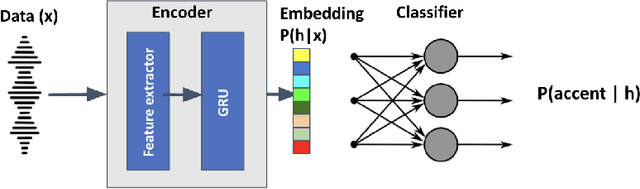
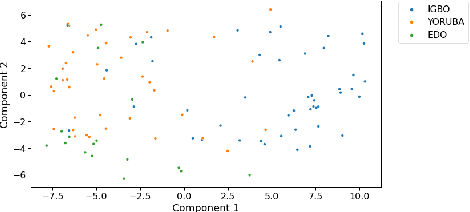
This paper describes foundational efforts with SautiDB-Naija, a novel corpus of non-native (L2) Nigerian English speech. We describe how the corpus was created and curated as well as preliminary experiments with accent classification and learning Nigerian accent embeddings. The initial version of the corpus includes over 900 recordings from L2 English speakers of Nigerian languages, such as Yoruba, Igbo, Edo, Efik-Ibibio, and Igala. We further demonstrate how fine-tuning on a pre-trained model like wav2vec can yield representations suitable for related speech tasks such as accent classification. SautiDB-Naija has been published to Zenodo for general use under a flexible Creative Commons License.
Via