 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Traffic Signal Control using High-Dimensional State Representation and Efficient Deep Reinforcement Learning
Nov 12, 2024



In reinforcement learning-based (RL-based) traffic signal control (TSC), decisions on the signal timing are made based on the available information on vehicles at a road intersection. This forms the state representation for the RL environment which can either be high-dimensional containing several variables or a low-dimensional vector. Current studies suggest that using high dimensional state representations does not lead to improved performance on TSC. However, we argue, with experimental results, that the use of high dimensional state representations can, in fact, lead to improved TSC performance with improvements up to 17.9% of the average waiting time. This high-dimensional representation is obtainable using the cost-effective vehicle-to-infrastructure (V2I) communication, encouraging its adoption for TSC. Additionally, given the large size of the state, we identified the need to have computational efficient models and explored model compression via pruning.
QMOS: Enhancing LLMs for Telecommunication with Question Masked loss and Option Shuffling
Sep 21, 2024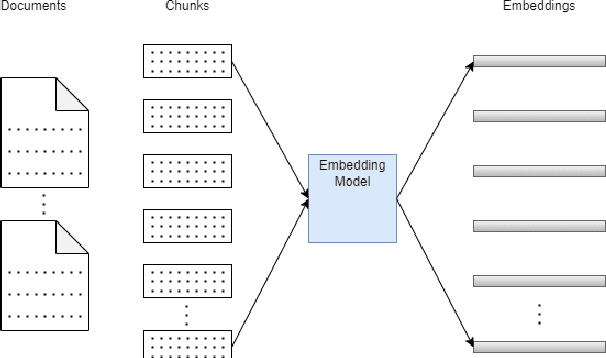
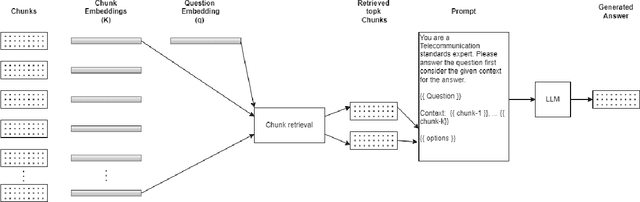
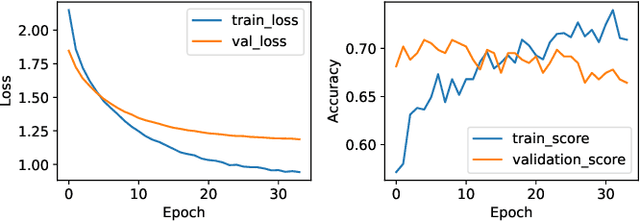
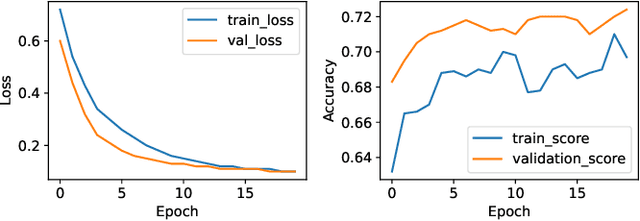
Large Language models (LLMs) have brought about substantial advancements in the field of Question Answering (QA) systems. These models do remarkably well in addressing intricate inquiries in a variety of disciplines. However, because of domain-specific vocabulary, complex technological concepts, and the requirement for exact responses applying LLMs to specialized sectors like telecommunications presents additional obstacles. GPT-3.5 has been used in recent work, to obtain noteworthy accuracy for telecom-related questions in a Retrieval Augmented Generation (RAG) framework. Notwithstanding these developments, the practical use of models such as GPT-3.5 is restricted by their proprietary nature and high computing demands. This paper introduces QMOS, an innovative approach which uses a Question-Masked loss and Option Shuffling trick to enhance the performance of LLMs in answering Multiple-Choice Questions in the telecommunications domain. Our focus was on using opensource, smaller language models (Phi-2 and Falcon-7B) within an enhanced RAG framework. Our multi-faceted approach involves several enhancements to the whole LLM-RAG pipeline of finetuning, retrieval, prompt engineering and inference. Our approaches significantly outperform existing results, achieving accuracy improvements from baselines of 24.70% to 49.30% with Falcon-7B and from 42.07% to 84.65% with Phi-2.
Learning Nigerian accent embeddings from speech: preliminary results based on SautiDB-Naija corpus
Dec 12, 2021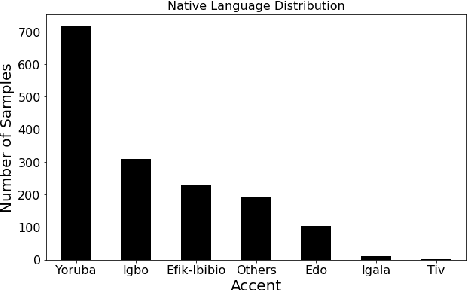
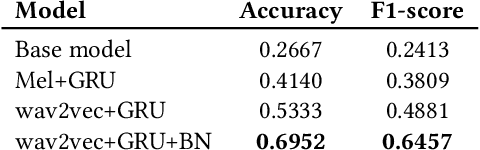
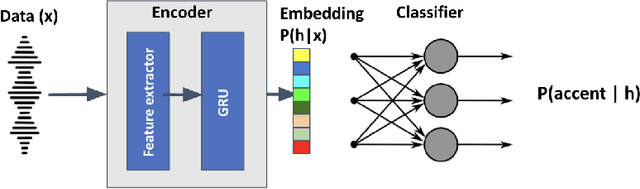
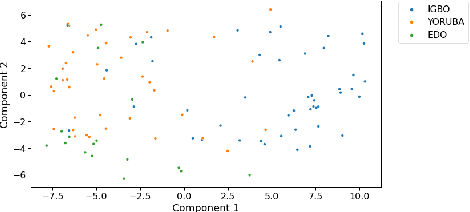
This paper describes foundational efforts with SautiDB-Naija, a novel corpus of non-native (L2) Nigerian English speech. We describe how the corpus was created and curated as well as preliminary experiments with accent classification and learning Nigerian accent embeddings. The initial version of the corpus includes over 900 recordings from L2 English speakers of Nigerian languages, such as Yoruba, Igbo, Edo, Efik-Ibibio, and Igala. We further demonstrate how fine-tuning on a pre-trained model like wav2vec can yield representations suitable for related speech tasks such as accent classification. SautiDB-Naija has been published to Zenodo for general use under a flexible Creative Commons License.
Mava: a research framework for distributed multi-agent reinforcement learning
Jul 03, 2021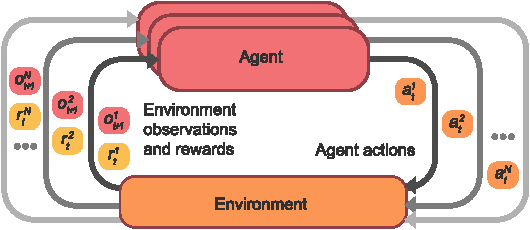
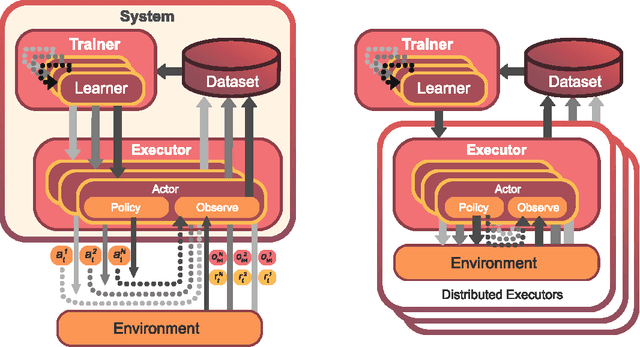
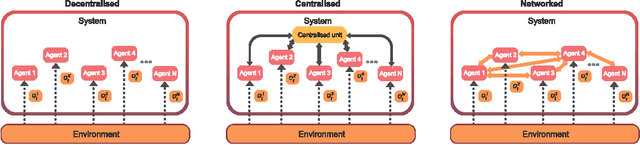

Breakthrough advances in reinforcement learning (RL) research have led to a surge in the development and application of RL. To support the field and its rapid growth, several frameworks have emerged that aim to help the community more easily build effective and scalable agents. However, very few of these frameworks exclusively support multi-agent RL (MARL), an increasingly active field in itself, concerned with decentralised decision-making problems. In this work, we attempt to fill this gap by presenting Mava: a research framework specifically designed for building scalable MARL systems. Mava provides useful components, abstractions, utilities and tools for MARL and allows for simple scaling for multi-process system training and execution, while providing a high level of flexibility and composability. Mava is built on top of DeepMind's Acme \citep{hoffman2020acme}, and therefore integrates with, and greatly benefits from, a wide range of already existing single-agent RL components made available in Acme. Several MARL baseline systems have already been implemented in Mava. These implementations serve as examples showcasing Mava's reusable features, such as interchangeable system architectures, communication and mixing modules. Furthermore, these implementations allow existing MARL algorithms to be easily reproduced and extended. We provide experimental results for these implementations on a wide range of multi-agent environments and highlight the benefits of distributed system training.