 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyBatchRender: A Python Library for Batched 3D Rendering at Up to One Million FPS
Jan 03, 2026Reinforcement learning from pixels is often bottlenecked by the performance and complexity of 3D rendered environments. Researchers face a trade-off between high-speed, low-level engines and slower, more accessible Python frameworks. To address this, we introduce PyBatchRender, a Python library for high-throughput, batched 3D rendering that achieves over 1 million FPS on simple scenes. Built on the Panda3D game engine, it utilizes its mature ecosystem while enhancing performance through optimized batched rendering for up to 1000X speedups. Designed as a physics-agnostic renderer for reinforcement learning from pixels, PyBatchRender offers greater flexibility than dedicated libraries, simpler setup than typical game-engine wrappers, and speeds rivaling state-of-the-art C++ engines like Madrona. Users can create custom scenes entirely in Python with tens of lines of code, enabling rapid prototyping for scalable AI training. Open-source and easy to integrate, it serves to democratize high-performance 3D simulation for researchers and developers. The library is available at https://github.com/dolphin-in-a-coma/PyBatchRender.
Graph-Based Exploration for ARC-AGI-3 Interactive Reasoning Tasks
Dec 30, 2025We present a training-free graph-based approach for solving interactive reasoning tasks in the ARC-AGI-3 benchmark. ARC-AGI-3 comprises game-like tasks where agents must infer task mechanics through limited interactions, and adapt to increasing complexity as levels progress. Success requires forming hypotheses, testing them, and tracking discovered mechanics. The benchmark has revealed that state-of-the-art LLMs are currently incapable of reliably solving these tasks. Our method combines vision-based frame processing with systematic state-space exploration using graph-structured representations. It segments visual frames into meaningful components, prioritizes actions based on visual salience, and maintains a directed graph of explored states and transitions. By tracking visited states and tested actions, the agent prioritizes actions that provide the shortest path to untested state-action pairs. On the ARC-AGI-3 Preview Challenge, this structured exploration strategy solves a median of 30 out of 52 levels across six games and ranks 3rd on the private leaderboard, substantially outperforming frontier LLM-based agents. These results demonstrate that explicit graph-structured exploration, even without learning, can serve as a strong baseline for interactive reasoning and underscore the importance of systematic state tracking and action prioritization in sparse-feedback environments where current LLMs fail to capture task dynamics. The code is open source and available at https://github.com/dolphin-in-a-coma/arc-agi-3-just-explore.
Dispelling the Mirage of Progress in Offline MARL through Standardised Baselines and Evaluation
Jun 13, 2024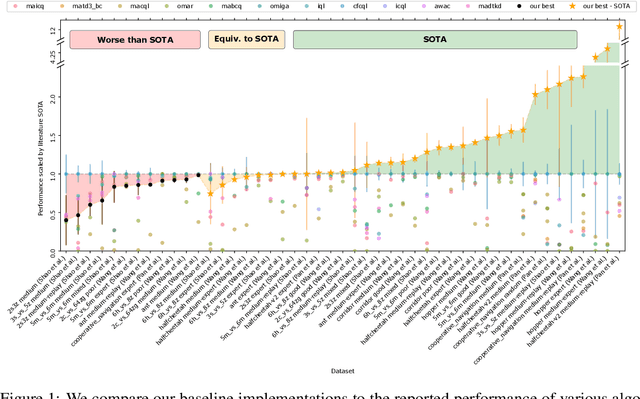


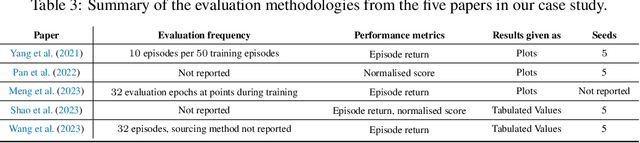
Offline multi-agent reinforcement learning (MARL) is an emerging field with great promise for real-world applications. Unfortunately, the current state of research in offline MARL is plagued by inconsistencies in baselines and evaluation protocols, which ultimately makes it difficult to accurately assess progress, trust newly proposed innovations, and allow researchers to easily build upon prior work. In this paper, we firstly identify significant shortcomings in existing methodologies for measuring the performance of novel algorithms through a representative study of published offline MARL work. Secondly, by directly comparing to this prior work, we demonstrate that simple, well-implemented baselines can achieve state-of-the-art (SOTA) results across a wide range of tasks. Specifically, we show that on 35 out of 47 datasets used in prior work (almost 75% of cases), we match or surpass the performance of the current purported SOTA. Strikingly, our baselines often substantially outperform these more sophisticated algorithms. Finally, we correct for the shortcomings highlighted from this prior work by introducing a straightforward standardised methodology for evaluation and by providing our baseline implementations with statistically robust results across several scenarios, useful for comparisons in future work. Our proposal includes simple and sensible steps that are easy to adopt, which in combination with solid baselines and comparative results, could substantially improve the overall rigour of empirical science in offline MARL moving forward.
Reduce, Reuse, Recycle: Selective Reincarnation in Multi-Agent Reinforcement Learning
Mar 31, 2023'Reincarnation' in reinforcement learning has been proposed as a formalisation of reusing prior computation from past experiments when training an agent in an environment. In this paper, we present a brief foray into the paradigm of reincarnation in the multi-agent (MA) context. We consider the case where only some agents are reincarnated, whereas the others are trained from scratch -- selective reincarnation. In the fully-cooperative MA setting with heterogeneous agents, we demonstrate that selective reincarnation can lead to higher returns than training fully from scratch, and faster convergence than training with full reincarnation. However, the choice of which agents to reincarnate in a heterogeneous system is vitally important to the outcome of the training -- in fact, a poor choice can lead to considerably worse results than the alternatives. We argue that a rich field of work exists here, and we hope that our effort catalyses further energy in bringing the topic of reincarnation to the multi-agent realm.
Off-the-Grid MARL: a Framework for Dataset Generation with Baselines for Cooperative Offline Multi-Agent Reinforcement Learning
Feb 01, 2023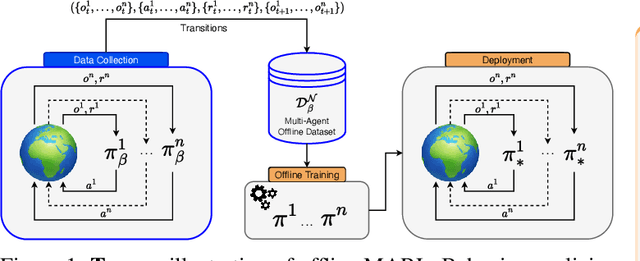
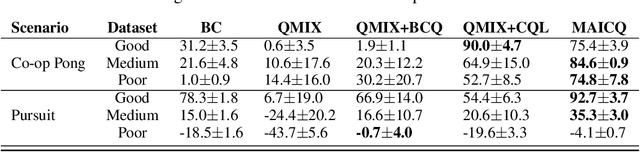
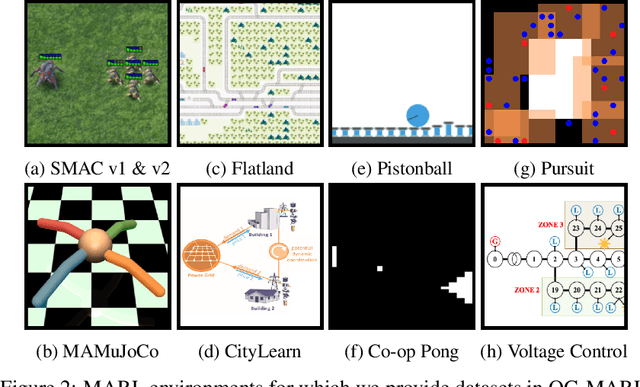
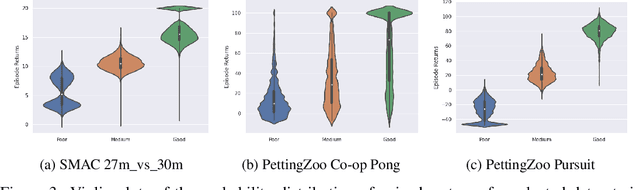
Being able to harness the power of large, static datasets for developing autonomous multi-agent systems could unlock enormous value for real-world applications. Many important industrial systems are multi-agent in nature and are difficult to model using bespoke simulators. However, in industry, distributed system processes can often be recorded during operation, and large quantities of demonstrative data can be stored. Offline multi-agent reinforcement learning (MARL) provides a promising paradigm for building effective online controllers from static datasets. However, offline MARL is still in its infancy, and, therefore, lacks standardised benchmarks, baselines and evaluation protocols typically found in more mature subfields of RL. This deficiency makes it difficult for the community to sensibly measure progress. In this work, we aim to fill this gap by releasing \emph{off-the-grid MARL (OG-MARL)}: a framework for generating offline MARL datasets and algorithms. We release an initial set of datasets and baselines for cooperative offline MARL, created using the framework, along with a standardised evaluation protocol. Our datasets provide settings that are characteristic of real-world systems, including complex dynamics, non-stationarity, partial observability, suboptimality and sparse rewards, and are generated from popular online MARL benchmarks. We hope that OG-MARL will serve the community and help steer progress in offline MARL, while also providing an easy entry point for researchers new to the field.
Causal Multi-Agent Reinforcement Learning: Review and Open Problems
Dec 01, 2021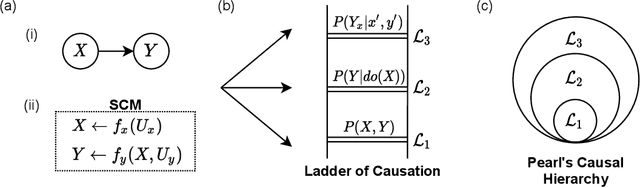
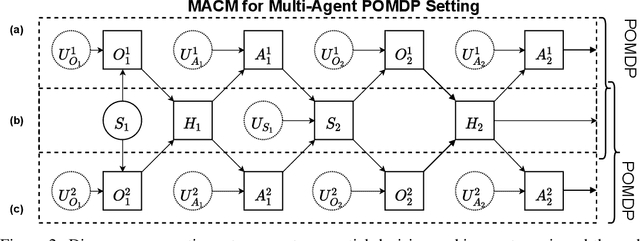
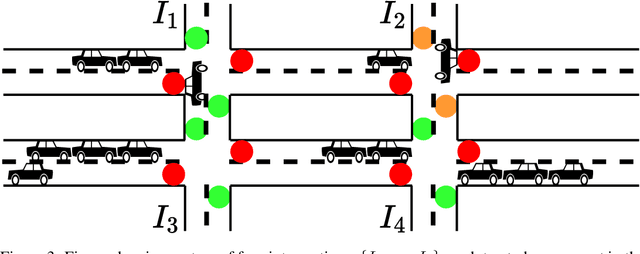
This paper serves to introduce the reader to the field of multi-agent reinforcement learning (MARL) and its intersection with methods from the study of causality. We highlight key challenges in MARL and discuss these in the context of how causal methods may assist in tackling them. We promote moving toward a 'causality first' perspective on MARL. Specifically, we argue that causality can offer improved safety, interpretability, and robustness, while also providing strong theoretical guarantees for emergent behaviour. We discuss potential solutions for common challenges, and use this context to motivate future research directions.
Mava: a research framework for distributed multi-agent reinforcement learning
Jul 03, 2021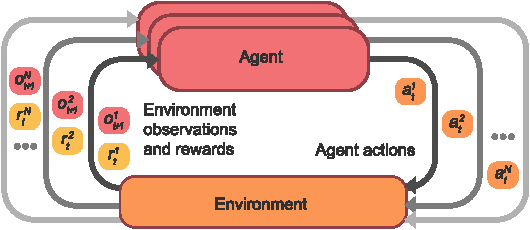
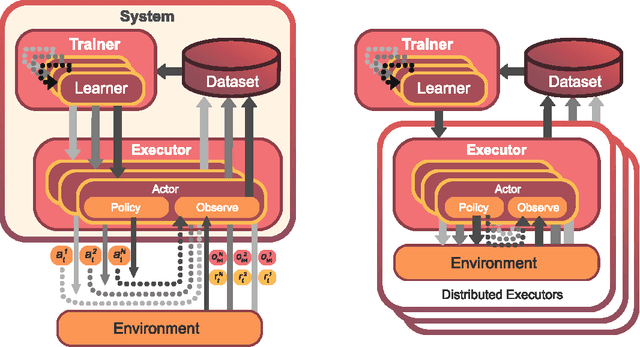
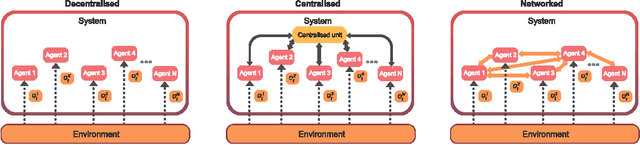

Breakthrough advances in reinforcement learning (RL) research have led to a surge in the development and application of RL. To support the field and its rapid growth, several frameworks have emerged that aim to help the community more easily build effective and scalable agents. However, very few of these frameworks exclusively support multi-agent RL (MARL), an increasingly active field in itself, concerned with decentralised decision-making problems. In this work, we attempt to fill this gap by presenting Mava: a research framework specifically designed for building scalable MARL systems. Mava provides useful components, abstractions, utilities and tools for MARL and allows for simple scaling for multi-process system training and execution, while providing a high level of flexibility and composability. Mava is built on top of DeepMind's Acme \citep{hoffman2020acme}, and therefore integrates with, and greatly benefits from, a wide range of already existing single-agent RL components made available in Acme. Several MARL baseline systems have already been implemented in Mava. These implementations serve as examples showcasing Mava's reusable features, such as interchangeable system architectures, communication and mixing modules. Furthermore, these implementations allow existing MARL algorithms to be easily reproduced and extended. We provide experimental results for these implementations on a wide range of multi-agent environments and highlight the benefits of distributed system training.
A game-theoretic analysis of networked system control for common-pool resource management using multi-agent reinforcement learning
Oct 15, 2020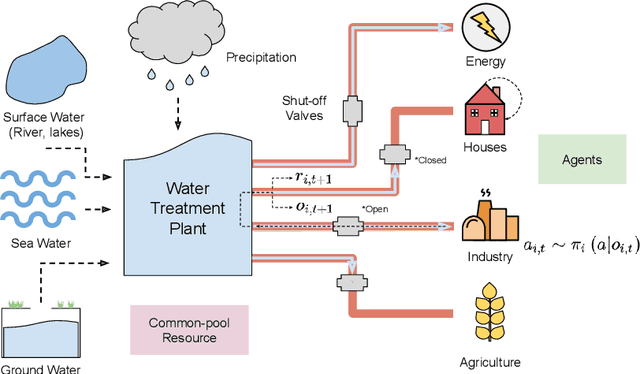
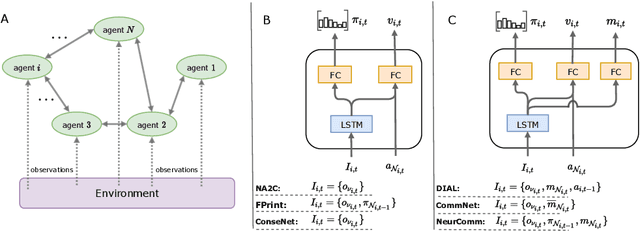
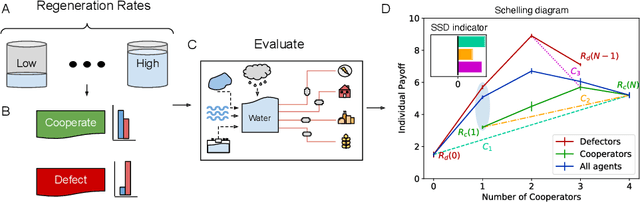
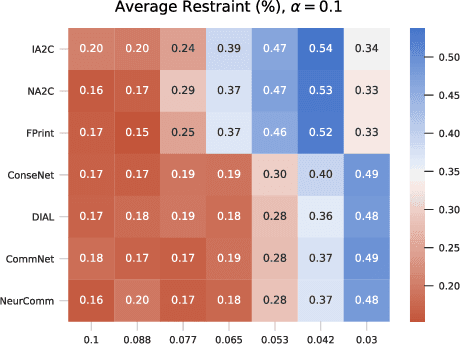
Multi-agent reinforcement learning has recently shown great promise as an approach to networked system control. Arguably, one of the most difficult and important tasks for which large scale networked system control is applicable is common-pool resource management. Crucial common-pool resources include arable land, fresh water, wetlands, wildlife, fish stock, forests and the atmosphere, of which proper management is related to some of society's greatest challenges such as food security, inequality and climate change. Here we take inspiration from a recent research program investigating the game-theoretic incentives of humans in social dilemma situations such as the well-known tragedy of the commons. However, instead of focusing on biologically evolved human-like agents, our concern is rather to better understand the learning and operating behaviour of engineered networked systems comprising general-purpose reinforcement learning agents, subject only to nonbiological constraints such as memory, computation and communication bandwidth. Harnessing tools from empirical game-theoretic analysis, we analyse the differences in resulting solution concepts that stem from employing different information structures in the design of networked multi-agent systems. These information structures pertain to the type of information shared between agents as well as the employed communication protocol and network topology. Our analysis contributes new insights into the consequences associated with certain design choices and provides an additional dimension of comparison between systems beyond efficiency, robustness, scalability and mean control performance.