 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformant, Memory Efficient and Scalable Multi-Agent Reinforcement Learning
Oct 02, 2024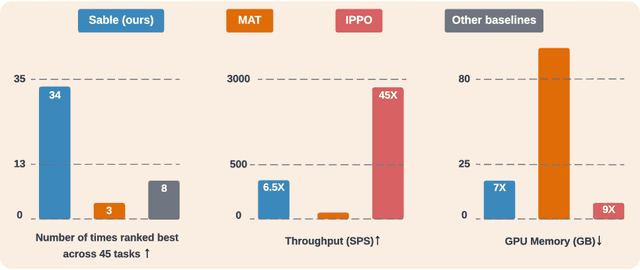
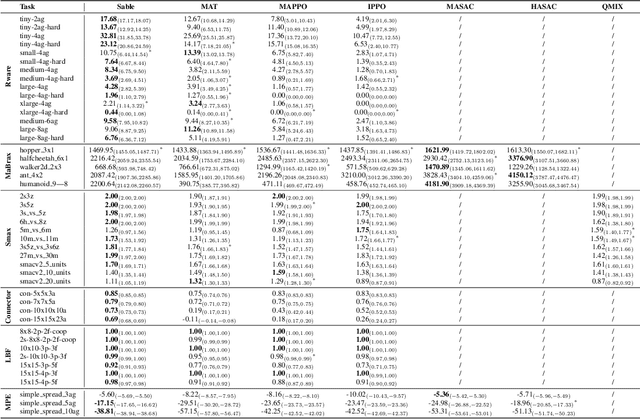

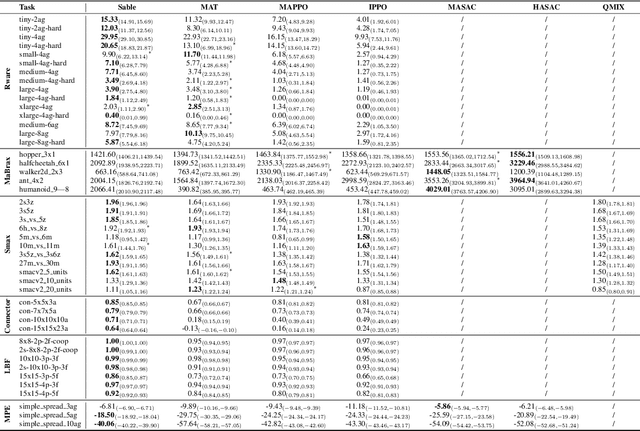
As the field of multi-agent reinforcement learning (MARL) progresses towards larger and more complex environments, achieving strong performance while maintaining memory efficiency and scalability to many agents becomes increasingly important. Although recent research has led to several advanced algorithms, to date, none fully address all of these key properties simultaneously. In this work, we introduce Sable, a novel and theoretically sound algorithm that adapts the retention mechanism from Retentive Networks to MARL. Sable's retention-based sequence modelling architecture allows for computationally efficient scaling to a large number of agents, as well as maintaining a long temporal context, making it well-suited for large-scale partially observable environments. Through extensive evaluations across six diverse environments, we demonstrate how Sable is able to significantly outperform existing state-of-the-art methods in the majority of tasks (34 out of 45, roughly 75\%). Furthermore, Sable demonstrates stable performance as we scale the number of agents, handling environments with more than a thousand agents while exhibiting a linear increase in memory usage. Finally, we conduct ablation studies to isolate the source of Sable's performance gains and confirm its efficient computational memory usage. Our results highlight Sable's performance and efficiency, positioning it as a leading approach to MARL at scale.
Putting Data at the Centre of Offline Multi-Agent Reinforcement Learning
Sep 18, 2024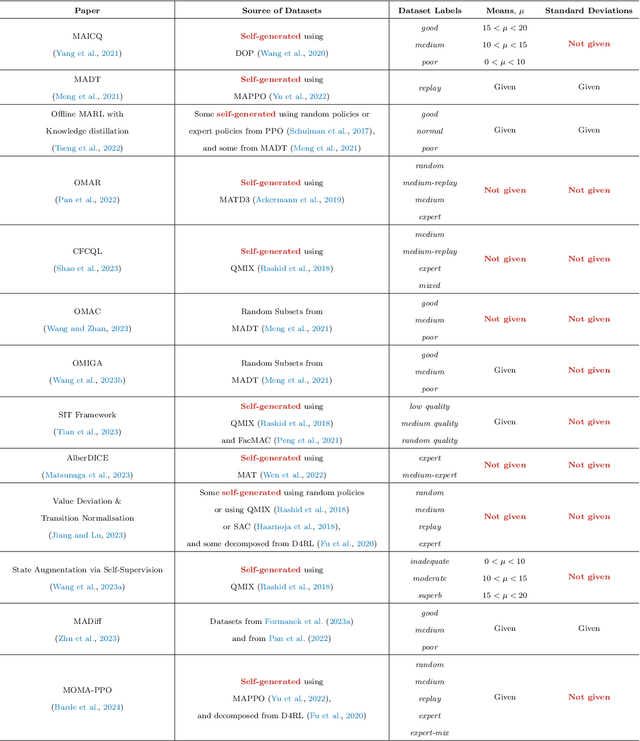
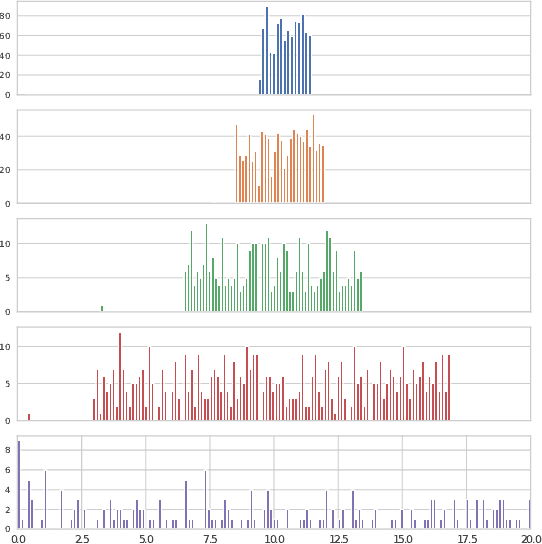

Offline multi-agent reinforcement learning (MARL) is an exciting direction of research that uses static datasets to find optimal control policies for multi-agent systems. Though the field is by definition data-driven, efforts have thus far neglected data in their drive to achieve state-of-the-art results. We first substantiate this claim by surveying the literature, showing how the majority of works generate their own datasets without consistent methodology and provide sparse information about the characteristics of these datasets. We then show why neglecting the nature of the data is problematic, through salient examples of how tightly algorithmic performance is coupled to the dataset used, necessitating a common foundation for experiments in the field. In response, we take a big step towards improving data usage and data awareness in offline MARL, with three key contributions: (1) a clear guideline for generating novel datasets; (2) a standardisation of over 80 existing datasets, hosted in a publicly available repository, using a consistent storage format and easy-to-use API; and (3) a suite of analysis tools that allow us to understand these datasets better, aiding further development.
Coordination Failure in Cooperative Offline MARL
Jul 01, 2024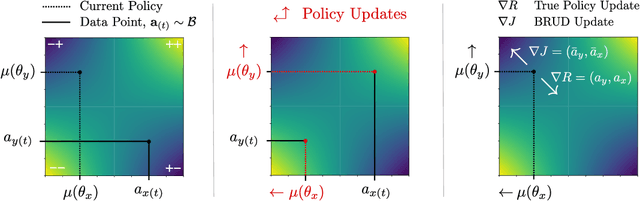
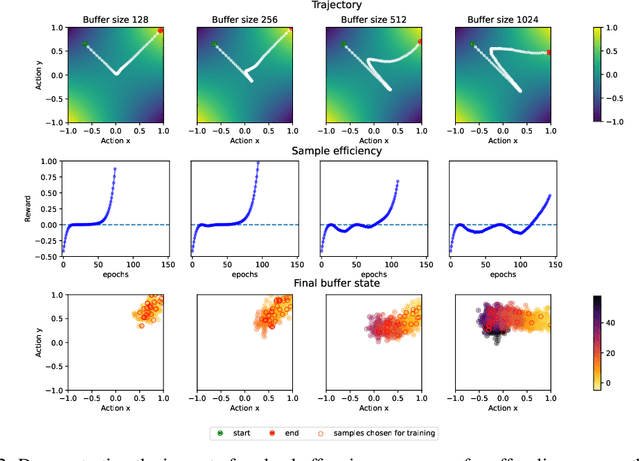
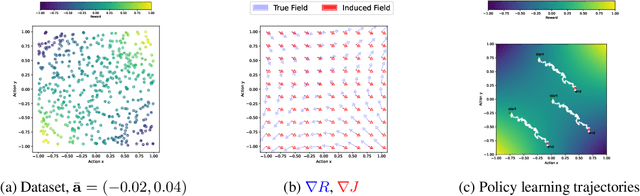
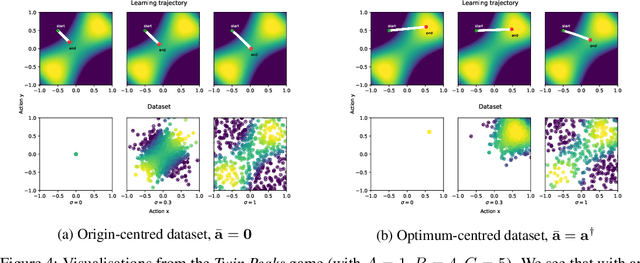
Offline multi-agent reinforcement learning (MARL) leverages static datasets of experience to learn optimal multi-agent control. However, learning from static data presents several unique challenges to overcome. In this paper, we focus on coordination failure and investigate the role of joint actions in multi-agent policy gradients with offline data, focusing on a common setting we refer to as the 'Best Response Under Data' (BRUD) approach. By using two-player polynomial games as an analytical tool, we demonstrate a simple yet overlooked failure mode of BRUD-based algorithms, which can lead to catastrophic coordination failure in the offline setting. Building on these insights, we propose an approach to mitigate such failure, by prioritising samples from the dataset based on joint-action similarity during policy learning and demonstrate its effectiveness in detailed experiments. More generally, however, we argue that prioritised dataset sampling is a promising area for innovation in offline MARL that can be combined with other effective approaches such as critic and policy regularisation. Importantly, our work shows how insights drawn from simplified, tractable games can lead to useful, theoretically grounded insights that transfer to more complex contexts. A core dimension of offering is an interactive notebook, from which almost all of our results can be reproduced, in a browser.
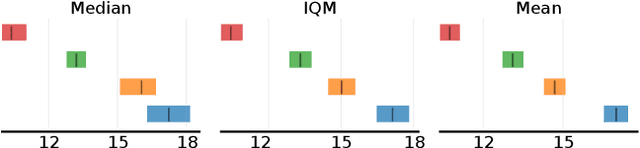
Dispelling the Mirage of Progress in Offline MARL through Standardised Baselines and Evaluation
Jun 13, 2024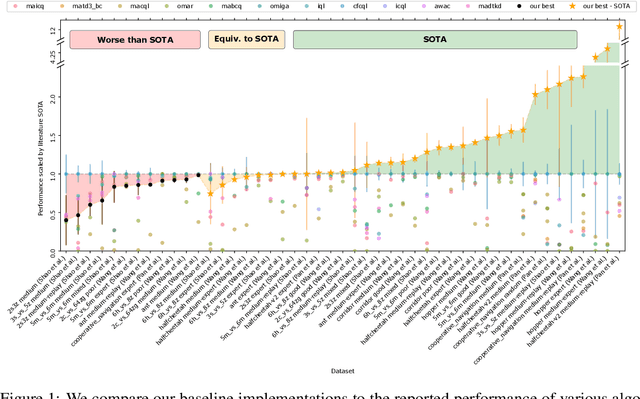


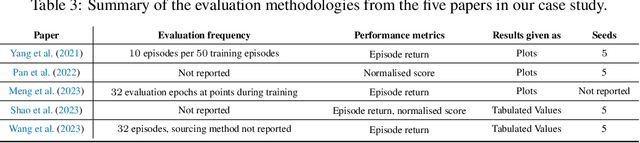
Offline multi-agent reinforcement learning (MARL) is an emerging field with great promise for real-world applications. Unfortunately, the current state of research in offline MARL is plagued by inconsistencies in baselines and evaluation protocols, which ultimately makes it difficult to accurately assess progress, trust newly proposed innovations, and allow researchers to easily build upon prior work. In this paper, we firstly identify significant shortcomings in existing methodologies for measuring the performance of novel algorithms through a representative study of published offline MARL work. Secondly, by directly comparing to this prior work, we demonstrate that simple, well-implemented baselines can achieve state-of-the-art (SOTA) results across a wide range of tasks. Specifically, we show that on 35 out of 47 datasets used in prior work (almost 75% of cases), we match or surpass the performance of the current purported SOTA. Strikingly, our baselines often substantially outperform these more sophisticated algorithms. Finally, we correct for the shortcomings highlighted from this prior work by introducing a straightforward standardised methodology for evaluation and by providing our baseline implementations with statistically robust results across several scenarios, useful for comparisons in future work. Our proposal includes simple and sensible steps that are easy to adopt, which in combination with solid baselines and comparative results, could substantially improve the overall rigour of empirical science in offline MARL moving forward.