 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe IgboAPI Dataset: Empowering Igbo Language Technologies through Multi-dialectal Enrichment
May 02, 2024

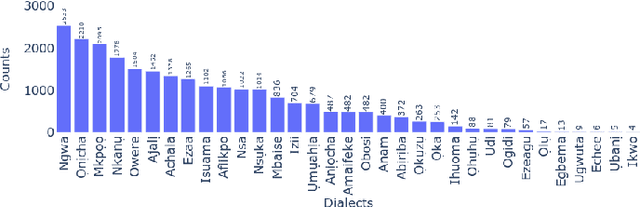
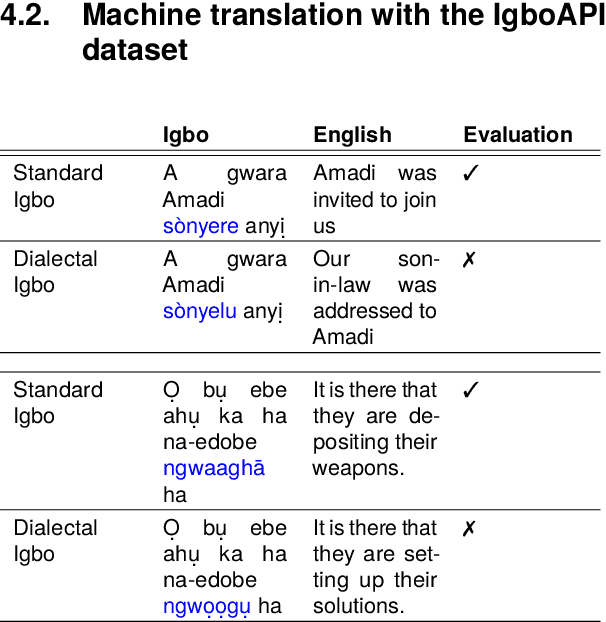
The Igbo language is facing a risk of becoming endangered, as indicated by a 2025 UNESCO study. This highlights the need to develop language technologies for Igbo to foster communication, learning and preservation. To create robust, impactful, and widely adopted language technologies for Igbo, it is essential to incorporate the multi-dialectal nature of the language. The primary obstacle in achieving dialectal-aware language technologies is the lack of comprehensive dialectal datasets. In response, we present the IgboAPI dataset, a multi-dialectal Igbo-English dictionary dataset, developed with the aim of enhancing the representation of Igbo dialects. Furthermore, we illustrate the practicality of the IgboAPI dataset through two distinct studies: one focusing on Igbo semantic lexicon and the other on machine translation. In the semantic lexicon project, we successfully establish an initial Igbo semantic lexicon for the Igbo semantic tagger, while in the machine translation study, we demonstrate that by finetuning existing machine translation systems using the IgboAPI dataset, we significantly improve their ability to handle dialectal variations in sentences.
AccentFold: A Journey through African Accents for Zero-Shot ASR Adaptation to Target Accents
Feb 05, 2024Despite advancements in speech recognition, accented speech remains challenging. While previous approaches have focused on modeling techniques or creating accented speech datasets, gathering sufficient data for the multitude of accents, particularly in the African context, remains impractical due to their sheer diversity and associated budget constraints. To address these challenges, we propose AccentFold, a method that exploits spatial relationships between learned accent embeddings to improve downstream Automatic Speech Recognition (ASR). Our exploratory analysis of speech embeddings representing 100+ African accents reveals interesting spatial accent relationships highlighting geographic and genealogical similarities, capturing consistent phonological, and morphological regularities, all learned empirically from speech. Furthermore, we discover accent relationships previously uncharacterized by the Ethnologue. Through empirical evaluation, we demonstrate the effectiveness of AccentFold by showing that, for out-of-distribution (OOD) accents, sampling accent subsets for training based on AccentFold information outperforms strong baselines a relative WER improvement of 4.6%. AccentFold presents a promising approach for improving ASR performance on accented speech, particularly in the context of African accents, where data scarcity and budget constraints pose significant challenges. Our findings emphasize the potential of leveraging linguistic relationships to improve zero-shot ASR adaptation to target accents.
Text Categorization Can Enhance Domain-Agnostic Stopword Extraction
Jan 24, 2024This paper investigates the role of text categorization in streamlining stopword extraction in natural language processing (NLP), specifically focusing on nine African languages alongside French. By leveraging the MasakhaNEWS, African Stopwords Project, and MasakhaPOS datasets, our findings emphasize that text categorization effectively identifies domain-agnostic stopwords with over 80% detection success rate for most examined languages. Nevertheless, linguistic variances result in lower detection rates for certain languages. Interestingly, we find that while over 40% of stopwords are common across news categories, less than 15% are unique to a single category. Uncommon stopwords add depth to text but their classification as stopwords depends on context. Therefore combining statistical and linguistic approaches creates comprehensive stopword lists, highlighting the value of our hybrid method. This research enhances NLP for African languages and underscores the importance of text categorization in stopword extraction.
AfriSpeech-200: Pan-African Accented Speech Dataset for Clinical and General Domain ASR
Sep 30, 2023Africa has a very low doctor-to-patient ratio. At very busy clinics, doctors could see 30+ patients per day -- a heavy patient burden compared with developed countries -- but productivity tools such as clinical automatic speech recognition (ASR) are lacking for these overworked clinicians. However, clinical ASR is mature, even ubiquitous, in developed nations, and clinician-reported performance of commercial clinical ASR systems is generally satisfactory. Furthermore, the recent performance of general domain ASR is approaching human accuracy. However, several gaps exist. Several publications have highlighted racial bias with speech-to-text algorithms and performance on minority accents lags significantly. To our knowledge, there is no publicly available research or benchmark on accented African clinical ASR, and speech data is non-existent for the majority of African accents. We release AfriSpeech, 200hrs of Pan-African English speech, 67,577 clips from 2,463 unique speakers across 120 indigenous accents from 13 countries for clinical and general domain ASR, a benchmark test set, with publicly available pre-trained models with SOTA performance on the AfriSpeech benchmark.
Benchmarking Bayesian Causal Discovery Methods for Downstream Treatment Effect Estimation
Jul 30, 2023



The practical utility of causality in decision-making is widespread and brought about by the intertwining of causal discovery and causal inference. Nevertheless, a notable gap exists in the evaluation of causal discovery methods, where insufficient emphasis is placed on downstream inference. To address this gap, we evaluate seven established baseline causal discovery methods including a newly proposed method based on GFlowNets, on the downstream task of treatment effect estimation. Through the implementation of a distribution-level evaluation, we offer valuable and unique insights into the efficacy of these causal discovery methods for treatment effect estimation, considering both synthetic and real-world scenarios, as well as low-data scenarios. The results of our study demonstrate that some of the algorithms studied are able to effectively capture a wide range of useful and diverse ATE modes, while some tend to learn many low-probability modes which impacts the (unrelaxed) recall and precision.
Adapting Pretrained ASR Models to Low-resource Clinical Speech using Epistemic Uncertainty-based Data Selection
Jun 03, 2023While there has been significant progress in ASR, African-accented clinical ASR has been understudied due to a lack of training datasets. Building robust ASR systems in this domain requires large amounts of annotated or labeled data, for a wide variety of linguistically and morphologically rich accents, which are expensive to create. Our study aims to address this problem by reducing annotation expenses through informative uncertainty-based data selection. We show that incorporating epistemic uncertainty into our adaptation rounds outperforms several baseline results, established using state-of-the-art (SOTA) ASR models, while reducing the required amount of labeled data, and hence reducing annotation costs. Our approach also improves out-of-distribution generalization for very low-resource accents, demonstrating the viability of our approach for building generalizable ASR models in the context of accented African clinical ASR, where training datasets are predominantly scarce.
AfriNames: Most ASR models "butcher" African Names
Jun 02, 2023



Useful conversational agents must accurately capture named entities to minimize error for downstream tasks, for example, asking a voice assistant to play a track from a certain artist, initiating navigation to a specific location, or documenting a laboratory result for a patient. However, where named entities such as ``Ukachukwu`` (Igbo), ``Lakicia`` (Swahili), or ``Ingabire`` (Rwandan) are spoken, automatic speech recognition (ASR) models' performance degrades significantly, propagating errors to downstream systems. We model this problem as a distribution shift and demonstrate that such model bias can be mitigated through multilingual pre-training, intelligent data augmentation strategies to increase the representation of African-named entities, and fine-tuning multilingual ASR models on multiple African accents. The resulting fine-tuned models show an 81.5\% relative WER improvement compared with the baseline on samples with African-named entities.
MasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages
May 23, 2023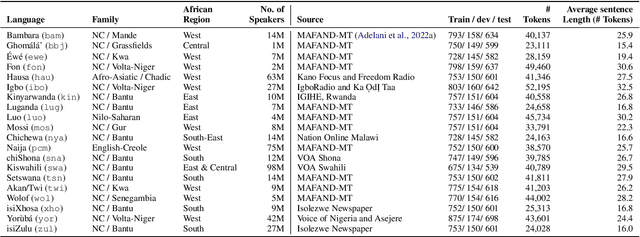
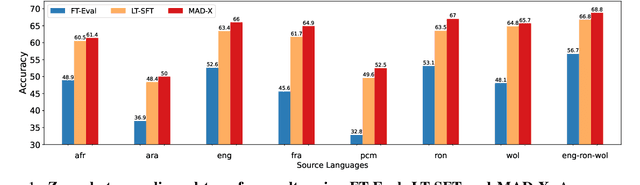
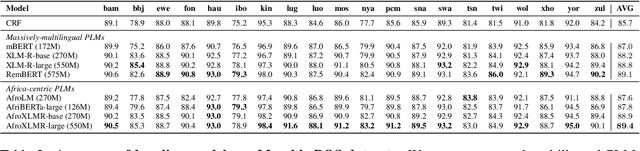
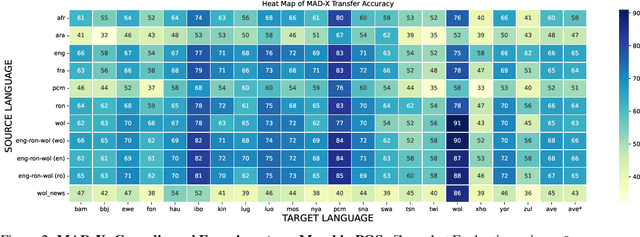
In this paper, we present MasakhaPOS, the largest part-of-speech (POS) dataset for 20 typologically diverse African languages. We discuss the challenges in annotating POS for these languages using the UD (universal dependencies) guidelines. We conducted extensive POS baseline experiments using conditional random field and several multilingual pre-trained language models. We applied various cross-lingual transfer models trained with data available in UD. Evaluating on the MasakhaPOS dataset, we show that choosing the best transfer language(s) in both single-source and multi-source setups greatly improves the POS tagging performance of the target languages, in particular when combined with cross-lingual parameter-efficient fine-tuning methods. Crucially, transferring knowledge from a language that matches the language family and morphosyntactic properties seems more effective for POS tagging in unseen languages.
MasakhaNEWS: News Topic Classification for African languages
Apr 19, 2023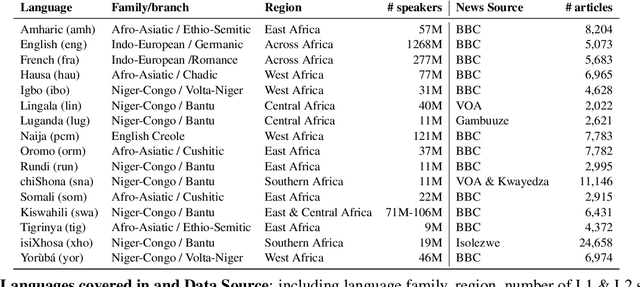
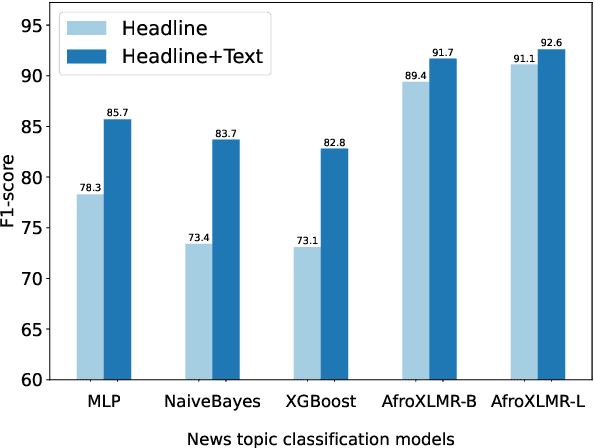
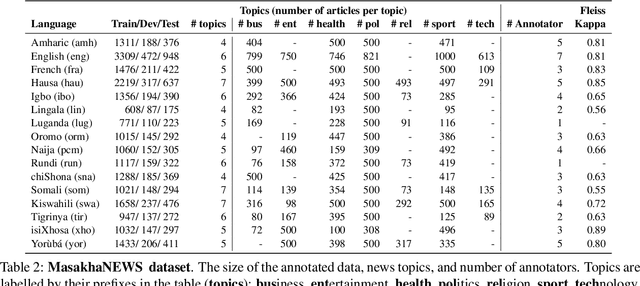
African languages are severely under-represented in NLP research due to lack of datasets covering several NLP tasks. While there are individual language specific datasets that are being expanded to different tasks, only a handful of NLP tasks (e.g. named entity recognition and machine translation) have standardized benchmark datasets covering several geographical and typologically-diverse African languages. In this paper, we develop MasakhaNEWS -- a new benchmark dataset for news topic classification covering 16 languages widely spoken in Africa. We provide an evaluation of baseline models by training classical machine learning models and fine-tuning several language models. Furthermore, we explore several alternatives to full fine-tuning of language models that are better suited for zero-shot and few-shot learning such as cross-lingual parameter-efficient fine-tuning (like MAD-X), pattern exploiting training (PET), prompting language models (like ChatGPT), and prompt-free sentence transformer fine-tuning (SetFit and Cohere Embedding API). Our evaluation in zero-shot setting shows the potential of prompting ChatGPT for news topic classification in low-resource African languages, achieving an average performance of 70 F1 points without leveraging additional supervision like MAD-X. In few-shot setting, we show that with as little as 10 examples per label, we achieved more than 90\% (i.e. 86.0 F1 points) of the performance of full supervised training (92.6 F1 points) leveraging the PET approach.
AfroDigits: A Community-Driven Spoken Digit Dataset for African Languages
Apr 04, 2023The advancement of speech technologies has been remarkable, yet its integration with African languages remains limited due to the scarcity of African speech corpora. To address this issue, we present AfroDigits, a minimalist, community-driven dataset of spoken digits for African languages, currently covering 38 African languages. As a demonstration of the practical applications of AfroDigits, we conduct audio digit classification experiments on six African languages [Igbo (ibo), Yoruba (yor), Rundi (run), Oshiwambo (kua), Shona (sna), and Oromo (gax)] using the Wav2Vec2.0-Large and XLS-R models. Our experiments reveal a useful insight on the effect of mixing African speech corpora during finetuning. AfroDigits is the first published audio digit dataset for African languages and we believe it will, among other things, pave the way for Afro-centric speech applications such as the recognition of telephone numbers, and street numbers. We release the dataset and platform publicly at https://huggingface.co/datasets/chrisjay/crowd-speech-africa and https://huggingface.co/spaces/chrisjay/afro-speech respectively.