 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multilingual Math Reasoning for African Languages
May 26, 2025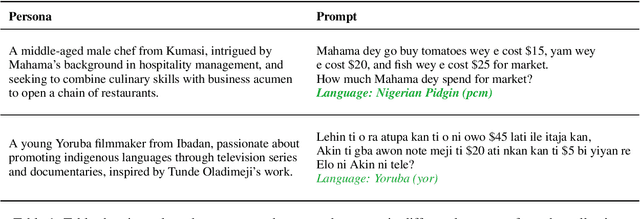
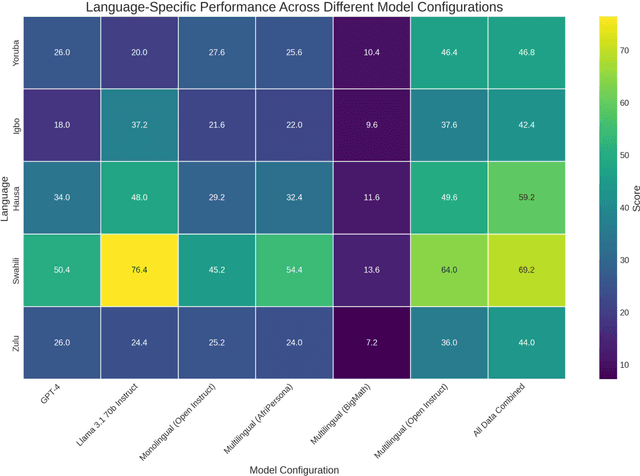
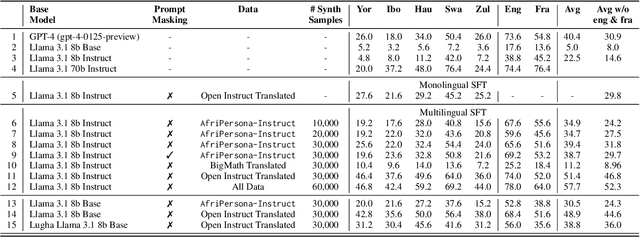

Researchers working on low-resource languages face persistent challenges due to limited data availability and restricted access to computational resources. Although most large language models (LLMs) are predominantly trained in high-resource languages, adapting them to low-resource contexts, particularly African languages, requires specialized techniques. Several strategies have emerged for adapting models to low-resource languages in todays LLM landscape, defined by multi-stage pre-training and post-training paradigms. However, the most effective approaches remain uncertain. This work systematically investigates which adaptation strategies yield the best performance when extending existing LLMs to African languages. We conduct extensive experiments and ablation studies to evaluate different combinations of data types (translated versus synthetically generated), training stages (pre-training versus post-training), and other model adaptation configurations. Our experiments focuses on mathematical reasoning tasks, using the Llama 3.1 model family as our base model.
CURE: A dataset for Clinical Understanding & Retrieval Evaluation
Dec 11, 2024Given the dominance of dense retrievers that do not generalize well beyond their training dataset distributions, domain-specific test sets are essential in evaluating retrieval. There are few test datasets for retrieval systems intended for use by healthcare providers in a point-of-care setting. To fill this gap we have collaborated with medical professionals to create CURE, an ad-hoc retrieval test dataset for passage ranking with 2000 queries spanning 10 medical domains with a monolingual (English) and two cross-lingual (French/Spanish -> English) conditions. In this paper, we describe how CURE was constructed and provide baseline results to showcase its effectiveness as an evaluation tool. CURE is published with a Creative Commons Attribution Non Commercial 4.0 license and can be accessed on Hugging Face.
CURE: Clinical Understanding & Retrieval Evaluation
Dec 09, 2024Given the dominance of dense retrievers that do not generalize well beyond their training dataset distributions, domain-specific test sets are essential in evaluating retrieval. There are few test datasets for retrieval systems intended for use by healthcare providers in a point-of-care setting. To fill this gap we have collaborated with medical professionals to create CURE, an ad-hoc retrieval test dataset for passage ranking with 2000 queries spanning 10 medical domains with a monolingual (English) and two cross-lingual (French/Spanish -> English) conditions. In this paper, we describe how CURE was constructed and provide baseline results to showcase its effectiveness as an evaluation tool. CURE is published with a Creative Commons Attribution Non Commercial 4.0 license and can be accessed on Hugging Face.
Zero-Shot Cross-Lingual Reranking with Large Language Models for Low-Resource Languages
Dec 26, 2023Large language models (LLMs) have shown impressive zero-shot capabilities in various document reranking tasks. Despite their successful implementations, there is still a gap in existing literature on their effectiveness in low-resource languages. To address this gap, we investigate how LLMs function as rerankers in cross-lingual information retrieval (CLIR) systems for African languages. Our implementation covers English and four African languages (Hausa, Somali, Swahili, and Yoruba) and we examine cross-lingual reranking with queries in English and passages in the African languages. Additionally, we analyze and compare the effectiveness of monolingual reranking using both query and document translations. We also evaluate the effectiveness of LLMs when leveraging their own generated translations. To get a grasp of the effectiveness of multiple LLMs, our study focuses on the proprietary models RankGPT-4 and RankGPT-3.5, along with the open-source model, RankZephyr. While reranking remains most effective in English, our results reveal that cross-lingual reranking may be competitive with reranking in African languages depending on the multilingual capability of the LLM.
GAIA Search: Hugging Face and Pyserini Interoperability for NLP Training Data Exploration
Jun 02, 2023Noticing the urgent need to provide tools for fast and user-friendly qualitative analysis of large-scale textual corpora of the modern NLP, we propose to turn to the mature and well-tested methods from the domain of Information Retrieval (IR) - a research field with a long history of tackling TB-scale document collections. We discuss how Pyserini - a widely used toolkit for reproducible IR research can be integrated with the Hugging Face ecosystem of open-source AI libraries and artifacts. We leverage the existing functionalities of both platforms while proposing novel features further facilitating their integration. Our goal is to give NLP researchers tools that will allow them to develop retrieval-based instrumentation for their data analytics needs with ease and agility. We include a Jupyter Notebook-based walk through the core interoperability features, available on GitHub at https://github.com/huggingface/gaia. We then demonstrate how the ideas we present can be operationalized to create a powerful tool for qualitative data analysis in NLP. We present GAIA Search - a search engine built following previously laid out principles, giving access to four popular large-scale text collections. GAIA serves a dual purpose of illustrating the potential of methodologies we discuss but also as a standalone qualitative analysis tool that can be leveraged by NLP researchers aiming to understand datasets prior to using them in training. GAIA is hosted live on Hugging Face Spaces - https://huggingface.co/spaces/spacerini/gaia.
AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages
May 11, 2023



African languages have far less in-language content available digitally, making it challenging for question answering systems to satisfy the information needs of users. Cross-lingual open-retrieval question answering (XOR QA) systems -- those that retrieve answer content from other languages while serving people in their native language -- offer a means of filling this gap. To this end, we create AfriQA, the first cross-lingual QA dataset with a focus on African languages. AfriQA includes 12,000+ XOR QA examples across 10 African languages. While previous datasets have focused primarily on languages where cross-lingual QA augments coverage from the target language, AfriQA focuses on languages where cross-lingual answer content is the only high-coverage source of answer content. Because of this, we argue that African languages are one of the most important and realistic use cases for XOR QA. Our experiments demonstrate the poor performance of automatic translation and multilingual retrieval methods. Overall, AfriQA proves challenging for state-of-the-art QA models. We hope that the dataset enables the development of more equitable QA technology.
MasakhaNEWS: News Topic Classification for African languages
Apr 19, 2023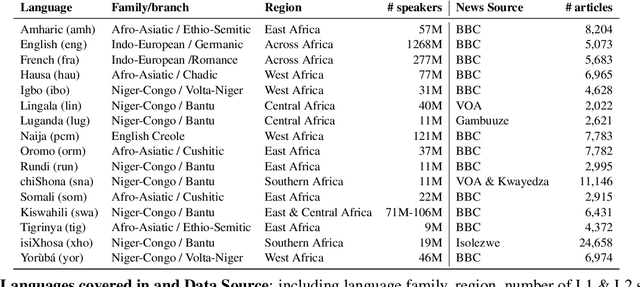
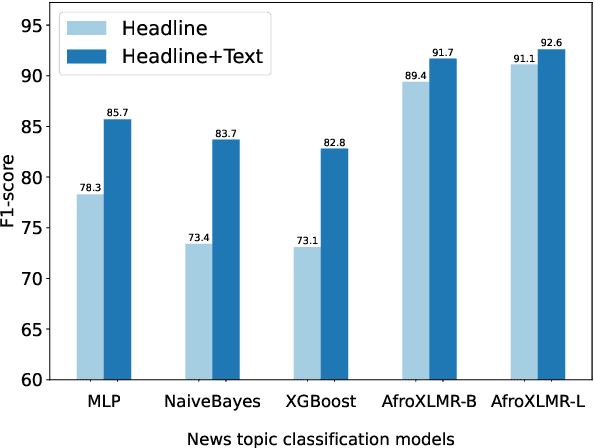
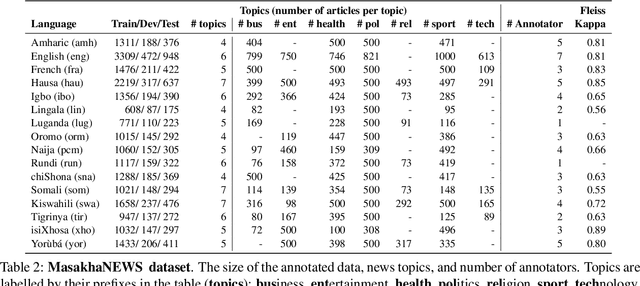
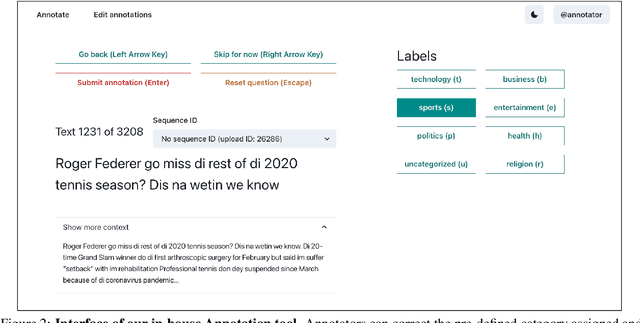
African languages are severely under-represented in NLP research due to lack of datasets covering several NLP tasks. While there are individual language specific datasets that are being expanded to different tasks, only a handful of NLP tasks (e.g. named entity recognition and machine translation) have standardized benchmark datasets covering several geographical and typologically-diverse African languages. In this paper, we develop MasakhaNEWS -- a new benchmark dataset for news topic classification covering 16 languages widely spoken in Africa. We provide an evaluation of baseline models by training classical machine learning models and fine-tuning several language models. Furthermore, we explore several alternatives to full fine-tuning of language models that are better suited for zero-shot and few-shot learning such as cross-lingual parameter-efficient fine-tuning (like MAD-X), pattern exploiting training (PET), prompting language models (like ChatGPT), and prompt-free sentence transformer fine-tuning (SetFit and Cohere Embedding API). Our evaluation in zero-shot setting shows the potential of prompting ChatGPT for news topic classification in low-resource African languages, achieving an average performance of 70 F1 points without leveraging additional supervision like MAD-X. In few-shot setting, we show that with as little as 10 examples per label, we achieved more than 90\% (i.e. 86.0 F1 points) of the performance of full supervised training (92.6 F1 points) leveraging the PET approach.
Spacerini: Plug-and-play Search Engines with Pyserini and Hugging Face
Feb 28, 2023We present Spacerini, a modular framework for seamless building and deployment of interactive search applications, designed to facilitate the qualitative analysis of large scale research datasets. Spacerini integrates features from both the Pyserini toolkit and the Hugging Face ecosystem to ease the indexing text collections and deploy them as search engines for ad-hoc exploration and to make the retrieval of relevant data points quick and efficient. The user-friendly interface enables searching through massive datasets in a no-code fashion, making Spacerini broadly accessible to anyone looking to qualitatively audit their text collections. This is useful both to IR~researchers aiming to demonstrate the capabilities of their indexes in a simple and interactive way, and to NLP~researchers looking to better understand and audit the failure modes of large language models. The framework is open source and available on GitHub: https://github.com/castorini/hf-spacerini, and includes utilities to load, pre-process, index, and deploy local and web search applications. A portfolio of applications created with Spacerini for a multitude of use cases can be found by visiting https://hf.co/spacerini.