 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccentFold: A Journey through African Accents for Zero-Shot ASR Adaptation to Target Accents
Feb 05, 2024Despite advancements in speech recognition, accented speech remains challenging. While previous approaches have focused on modeling techniques or creating accented speech datasets, gathering sufficient data for the multitude of accents, particularly in the African context, remains impractical due to their sheer diversity and associated budget constraints. To address these challenges, we propose AccentFold, a method that exploits spatial relationships between learned accent embeddings to improve downstream Automatic Speech Recognition (ASR). Our exploratory analysis of speech embeddings representing 100+ African accents reveals interesting spatial accent relationships highlighting geographic and genealogical similarities, capturing consistent phonological, and morphological regularities, all learned empirically from speech. Furthermore, we discover accent relationships previously uncharacterized by the Ethnologue. Through empirical evaluation, we demonstrate the effectiveness of AccentFold by showing that, for out-of-distribution (OOD) accents, sampling accent subsets for training based on AccentFold information outperforms strong baselines a relative WER improvement of 4.6%. AccentFold presents a promising approach for improving ASR performance on accented speech, particularly in the context of African accents, where data scarcity and budget constraints pose significant challenges. Our findings emphasize the potential of leveraging linguistic relationships to improve zero-shot ASR adaptation to target accents.
A Decade of Scholarly Research on Open Knowledge Graphs
Jun 22, 2023The proliferation of open knowledge graphs has led to a surge in scholarly research on the topic over the past decade. This paper presents a bibliometric analysis of the scholarly literature on open knowledge graphs published between 2013 and 2023. The study aims to identify the trends, patterns, and impact of research in this field, as well as the key topics and research questions that have emerged. The work uses bibliometric techniques to analyze a sample of 4445 scholarly articles retrieved from Scopus. The findings reveal an ever-increasing number of publications on open knowledge graphs published every year, particularly in developed countries (+50 per year). These outputs are published in highly-referred scholarly journals and conferences. The study identifies three main research themes: (1) knowledge graph construction and enrichment, (2) evaluation and reuse, and (3) fusion of knowledge graphs into NLP systems. Within these themes, the study identifies specific tasks that have received considerable attention, including entity linking, knowledge graph embedding, and graph neural networks.
AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages
May 11, 2023



African languages have far less in-language content available digitally, making it challenging for question answering systems to satisfy the information needs of users. Cross-lingual open-retrieval question answering (XOR QA) systems -- those that retrieve answer content from other languages while serving people in their native language -- offer a means of filling this gap. To this end, we create AfriQA, the first cross-lingual QA dataset with a focus on African languages. AfriQA includes 12,000+ XOR QA examples across 10 African languages. While previous datasets have focused primarily on languages where cross-lingual QA augments coverage from the target language, AfriQA focuses on languages where cross-lingual answer content is the only high-coverage source of answer content. Because of this, we argue that African languages are one of the most important and realistic use cases for XOR QA. Our experiments demonstrate the poor performance of automatic translation and multilingual retrieval methods. Overall, AfriQA proves challenging for state-of-the-art QA models. We hope that the dataset enables the development of more equitable QA technology.
MasakhaNEWS: News Topic Classification for African languages
Apr 19, 2023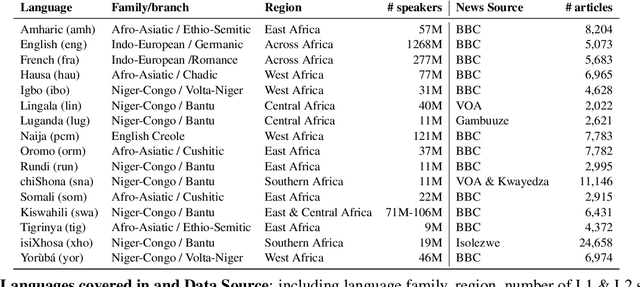
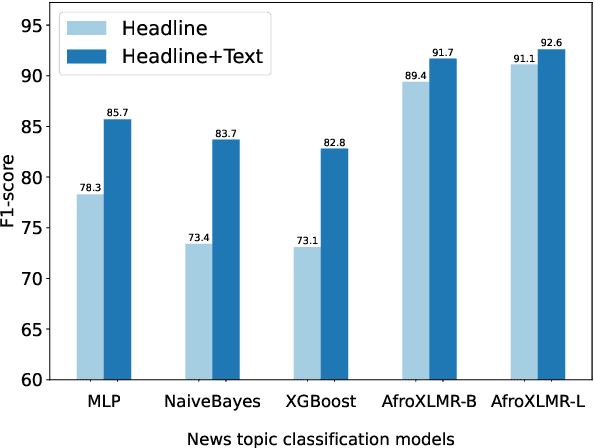
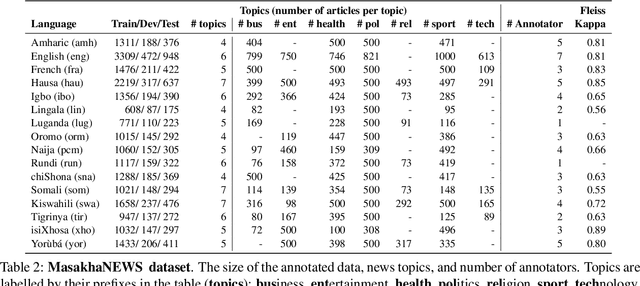
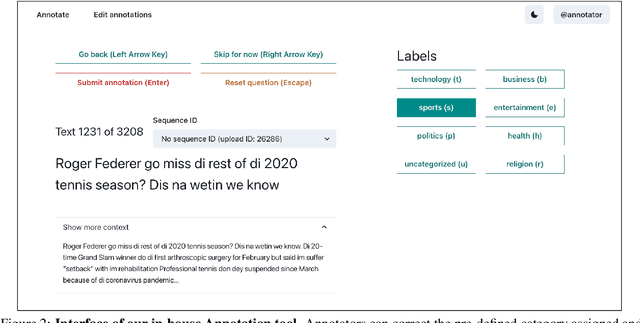
African languages are severely under-represented in NLP research due to lack of datasets covering several NLP tasks. While there are individual language specific datasets that are being expanded to different tasks, only a handful of NLP tasks (e.g. named entity recognition and machine translation) have standardized benchmark datasets covering several geographical and typologically-diverse African languages. In this paper, we develop MasakhaNEWS -- a new benchmark dataset for news topic classification covering 16 languages widely spoken in Africa. We provide an evaluation of baseline models by training classical machine learning models and fine-tuning several language models. Furthermore, we explore several alternatives to full fine-tuning of language models that are better suited for zero-shot and few-shot learning such as cross-lingual parameter-efficient fine-tuning (like MAD-X), pattern exploiting training (PET), prompting language models (like ChatGPT), and prompt-free sentence transformer fine-tuning (SetFit and Cohere Embedding API). Our evaluation in zero-shot setting shows the potential of prompting ChatGPT for news topic classification in low-resource African languages, achieving an average performance of 70 F1 points without leveraging additional supervision like MAD-X. In few-shot setting, we show that with as little as 10 examples per label, we achieved more than 90\% (i.e. 86.0 F1 points) of the performance of full supervised training (92.6 F1 points) leveraging the PET approach.