 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalized Orthography for Tunisian Arabic
Feb 20, 2024
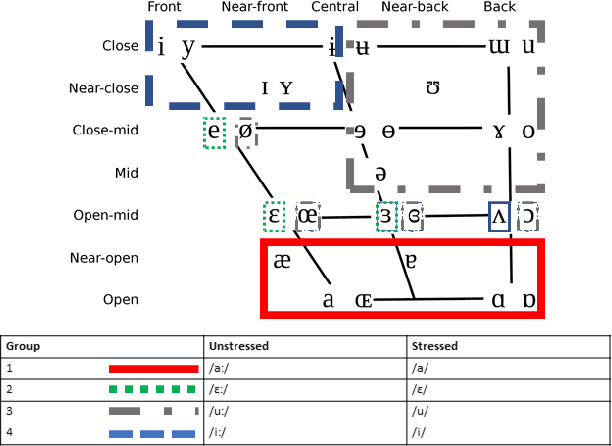


Tunisian Arabic (ISO 693-3: aeb) is a distinct linguistic variety native to Tunisia, initially stemmed from the Arabic language and enriched by a multitude of historical influences. This research introduces the "Normalized Orthography for Tunisian Arabic" (NOTA), an adaptation of CODA* guidelines tailored for transcribing Tunisian Arabic using the Arabic script for language resource development purposes, with an emphasis on user-friendliness and consistency. The updated standard seeks to address challenges related to accurately representing the unique characteristics of Tunisian phonology and morphology. This will be achieved by rectifying problems arising from transcriptions based on resemblances to Modern Standard Arabic.
A Survey on African Computer Vision Datasets, Topics and Researchers
Feb 04, 2024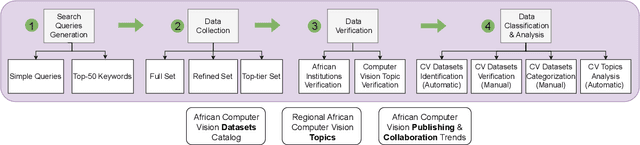


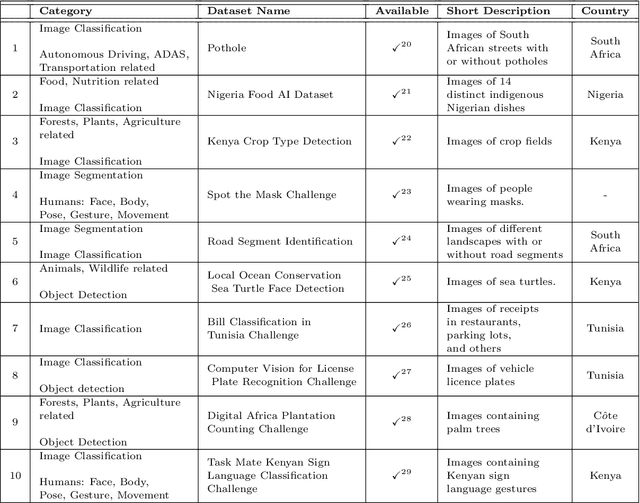
Computer vision encompasses a range of tasks such as object detection, semantic segmentation, and 3D reconstruction. Despite its relevance to African communities, research in this field within Africa represents only 0.06% of top-tier publications over the past decade. This study undertakes a thorough analysis of 63,000 Scopus-indexed computer vision publications from Africa, spanning from 2012 to 2022. The aim is to provide a survey of African computer vision topics, datasets and researchers. A key aspect of our study is the identification and categorization of African Computer Vision datasets using large language models that automatically parse abstracts of these publications. We also provide a compilation of unofficial African Computer Vision datasets distributed through challenges or data hosting platforms, and provide a full taxonomy of dataset categories. Our survey also pinpoints computer vision topics trends specific to different African regions, indicating their unique focus areas. Additionally, we carried out an extensive survey to capture the views of African researchers on the current state of computer vision research in the continent and the structural barriers they believe need urgent attention. In conclusion, this study catalogs and categorizes Computer Vision datasets and topics contributed or initiated by African institutions and identifies barriers to publishing in top-tier Computer Vision venues. This survey underscores the importance of encouraging African researchers and institutions in advancing computer vision research in the continent. It also stresses on the need for research topics to be more aligned with the needs of African communities.
Text Categorization Can Enhance Domain-Agnostic Stopword Extraction
Jan 24, 2024This paper investigates the role of text categorization in streamlining stopword extraction in natural language processing (NLP), specifically focusing on nine African languages alongside French. By leveraging the MasakhaNEWS, African Stopwords Project, and MasakhaPOS datasets, our findings emphasize that text categorization effectively identifies domain-agnostic stopwords with over 80% detection success rate for most examined languages. Nevertheless, linguistic variances result in lower detection rates for certain languages. Interestingly, we find that while over 40% of stopwords are common across news categories, less than 15% are unique to a single category. Uncommon stopwords add depth to text but their classification as stopwords depends on context. Therefore combining statistical and linguistic approaches creates comprehensive stopword lists, highlighting the value of our hybrid method. This research enhances NLP for African languages and underscores the importance of text categorization in stopword extraction.
A Decade of Scholarly Research on Open Knowledge Graphs
Jun 22, 2023The proliferation of open knowledge graphs has led to a surge in scholarly research on the topic over the past decade. This paper presents a bibliometric analysis of the scholarly literature on open knowledge graphs published between 2013 and 2023. The study aims to identify the trends, patterns, and impact of research in this field, as well as the key topics and research questions that have emerged. The work uses bibliometric techniques to analyze a sample of 4445 scholarly articles retrieved from Scopus. The findings reveal an ever-increasing number of publications on open knowledge graphs published every year, particularly in developed countries (+50 per year). These outputs are published in highly-referred scholarly journals and conferences. The study identifies three main research themes: (1) knowledge graph construction and enrichment, (2) evaluation and reuse, and (3) fusion of knowledge graphs into NLP systems. Within these themes, the study identifies specific tasks that have received considerable attention, including entity linking, knowledge graph embedding, and graph neural networks.
Towards a Better Understanding of the Computer Vision Research Community in Africa
May 11, 2023



Computer vision is a broad field of study that encompasses different tasks (e.g., object detection, semantic segmentation, 3D reconstruction). Although computer vision is relevant to the African communities in various applications, yet computer vision research is under-explored in the continent and constructs only 0.06% of top-tier publications in the last 10 years. In this paper, our goal is to have a better understanding of the computer vision research conducted in Africa and provide pointers on whether there is equity in research or not. We do this through an empirical analysis of the African computer vision publications that are Scopus indexed. We first study the opportunities available for African institutions to publish in top-tier computer vision venues. We show that African publishing trends in top-tier venues over the years do not exhibit consistent growth. We also devise a novel way to retrieve African authors through their affiliation history to have a better understanding of their contributions in top-tier venues. Moreover, we study all computer vision publications beyond top-tier venues in different African regions to find that mainly Northern and Southern Africa are publishing in computer vision with more than 85% of African publications. Finally, we present the most recurring keywords in computer vision publications. In summary, our analysis reveals that African researchers are key contributors to African research, yet there exists multiple barriers to publish in top-tier venues and the current trend of topics published in the continent might not necessarily reflect the communities' needs. This work is part of a community based effort that is focused on improving computer vision research in Africa.
Semantic similarity-based approach to enhance supervised classification learning accuracy
Oct 30, 2020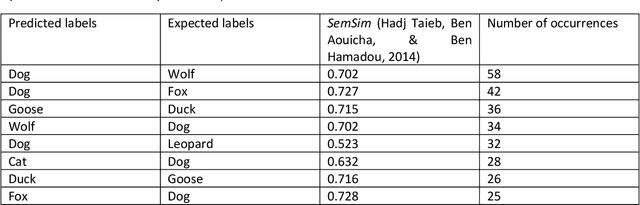
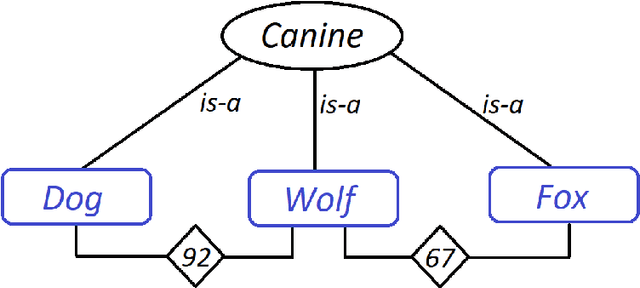
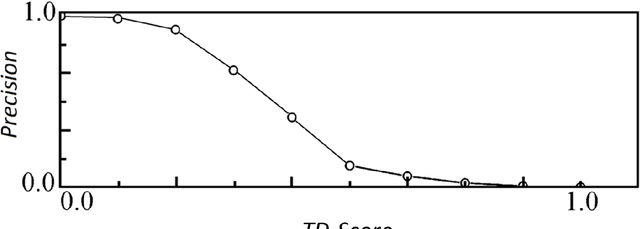
This brief communication discusses the usefulness of semantic similarity measures for the evaluation and amelioration of the accuracy of supervised classification learning. It proposes a semantic similarity-based method to enhance the choice of adequate labels for the classification algorithm as well as two metrics (SS-Score and TD-Score) and a curve (SA-Curve) that can be coupled to statistical evaluation measures of supervised classification learning to take into consideration the impact of the semantic aspect of the labels on the classification accuracy.