 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem Identification of Neural Systems: Going Beyond Images to Modelling Dynamics
Feb 19, 2024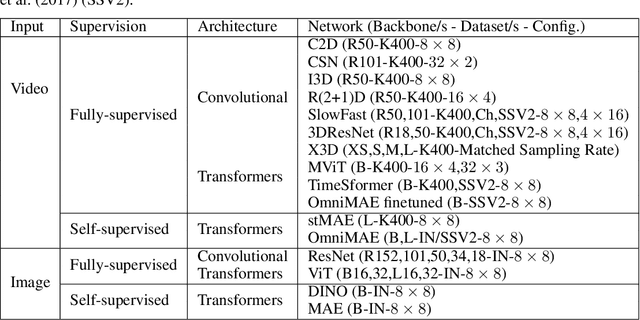
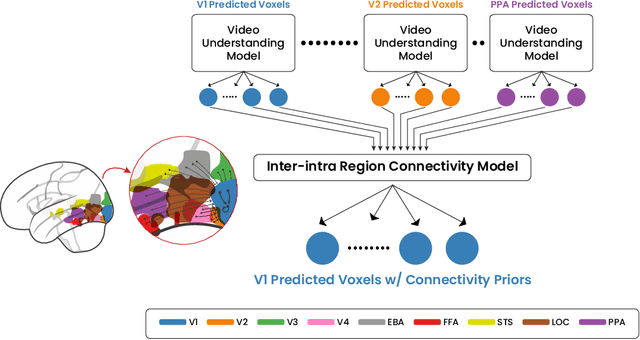
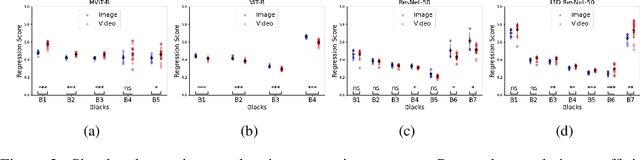

Vast literature has compared the recordings of biological neurons in the brain to deep neural networks. The ultimate goal is to interpret deep networks or to better understand and encode biological neural systems. Recently, there has been a debate on whether system identification is possible and how much it can tell us about the brain computation. System identification recognizes whether one model is more valid to represent the brain computation over another. Nonetheless, previous work did not consider the time aspect and how video and dynamics (e.g., motion) modelling in deep networks relate to these biological neural systems within a large-scale comparison. Towards this end, we propose a system identification study focused on comparing single image vs. video understanding models with respect to the visual cortex recordings. Our study encompasses two sets of experiments; a real environment setup and a simulated environment setup. The study also encompasses more than 30 models and, unlike prior works, we focus on convolutional vs. transformer-based, single vs. two-stream, and fully vs. self-supervised video understanding models. The goal is to capture a greater variety of architectures that model dynamics. As such, this signifies the first large-scale study of video understanding models from a neuroscience perspective. Our results in the simulated experiments, show that system identification can be attained to a certain level in differentiating image vs. video understanding models. Moreover, we provide key insights on how video understanding models predict visual cortex responses; showing video understanding better than image understanding models, convolutional models are better in the early-mid regions than transformer based except for multiscale transformers that are still good in predicting these regions, and that two-stream models are better than single stream.
A Survey on African Computer Vision Datasets, Topics and Researchers
Feb 04, 2024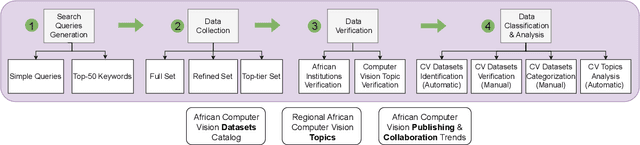


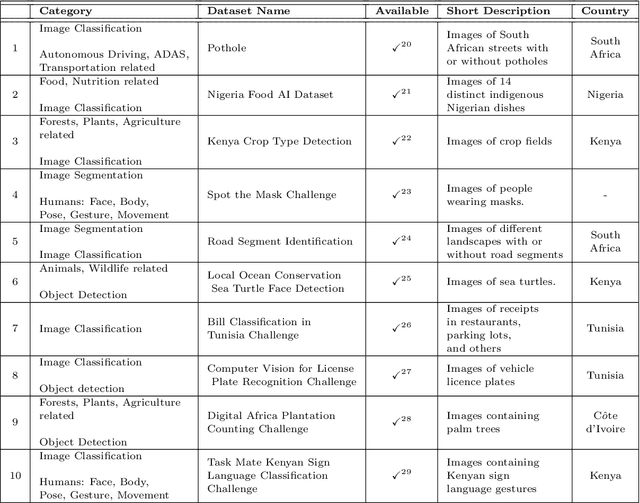
Computer vision encompasses a range of tasks such as object detection, semantic segmentation, and 3D reconstruction. Despite its relevance to African communities, research in this field within Africa represents only 0.06% of top-tier publications over the past decade. This study undertakes a thorough analysis of 63,000 Scopus-indexed computer vision publications from Africa, spanning from 2012 to 2022. The aim is to provide a survey of African computer vision topics, datasets and researchers. A key aspect of our study is the identification and categorization of African Computer Vision datasets using large language models that automatically parse abstracts of these publications. We also provide a compilation of unofficial African Computer Vision datasets distributed through challenges or data hosting platforms, and provide a full taxonomy of dataset categories. Our survey also pinpoints computer vision topics trends specific to different African regions, indicating their unique focus areas. Additionally, we carried out an extensive survey to capture the views of African researchers on the current state of computer vision research in the continent and the structural barriers they believe need urgent attention. In conclusion, this study catalogs and categorizes Computer Vision datasets and topics contributed or initiated by African institutions and identifies barriers to publishing in top-tier Computer Vision venues. This survey underscores the importance of encouraging African researchers and institutions in advancing computer vision research in the continent. It also stresses on the need for research topics to be more aligned with the needs of African communities.
Towards a Better Understanding of the Computer Vision Research Community in Africa
May 11, 2023



Computer vision is a broad field of study that encompasses different tasks (e.g., object detection, semantic segmentation, 3D reconstruction). Although computer vision is relevant to the African communities in various applications, yet computer vision research is under-explored in the continent and constructs only 0.06% of top-tier publications in the last 10 years. In this paper, our goal is to have a better understanding of the computer vision research conducted in Africa and provide pointers on whether there is equity in research or not. We do this through an empirical analysis of the African computer vision publications that are Scopus indexed. We first study the opportunities available for African institutions to publish in top-tier computer vision venues. We show that African publishing trends in top-tier venues over the years do not exhibit consistent growth. We also devise a novel way to retrieve African authors through their affiliation history to have a better understanding of their contributions in top-tier venues. Moreover, we study all computer vision publications beyond top-tier venues in different African regions to find that mainly Northern and Southern Africa are publishing in computer vision with more than 85% of African publications. Finally, we present the most recurring keywords in computer vision publications. In summary, our analysis reveals that African researchers are key contributors to African research, yet there exists multiple barriers to publish in top-tier venues and the current trend of topics published in the continent might not necessarily reflect the communities' needs. This work is part of a community based effort that is focused on improving computer vision research in Africa.