 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem Identification of Neural Systems: Going Beyond Images to Modelling Dynamics
Paper and Code
Feb 19, 2024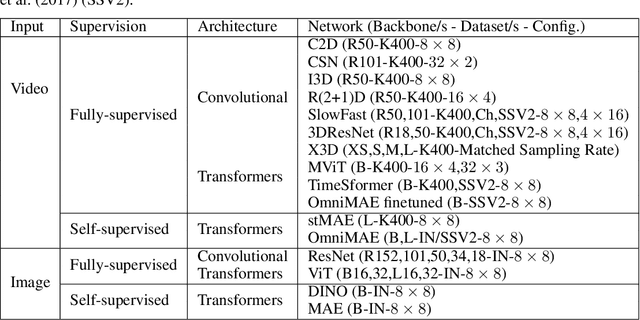
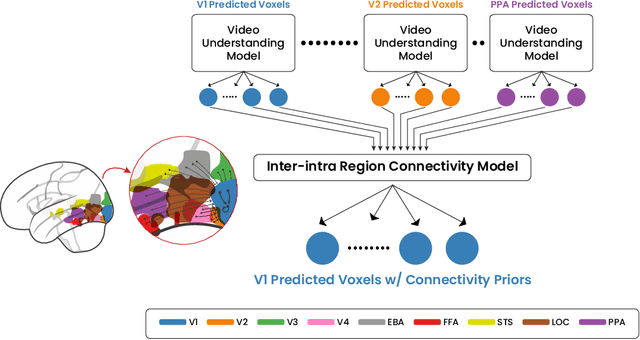
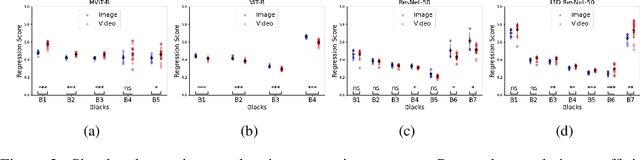

Vast literature has compared the recordings of biological neurons in the brain to deep neural networks. The ultimate goal is to interpret deep networks or to better understand and encode biological neural systems. Recently, there has been a debate on whether system identification is possible and how much it can tell us about the brain computation. System identification recognizes whether one model is more valid to represent the brain computation over another. Nonetheless, previous work did not consider the time aspect and how video and dynamics (e.g., motion) modelling in deep networks relate to these biological neural systems within a large-scale comparison. Towards this end, we propose a system identification study focused on comparing single image vs. video understanding models with respect to the visual cortex recordings. Our study encompasses two sets of experiments; a real environment setup and a simulated environment setup. The study also encompasses more than 30 models and, unlike prior works, we focus on convolutional vs. transformer-based, single vs. two-stream, and fully vs. self-supervised video understanding models. The goal is to capture a greater variety of architectures that model dynamics. As such, this signifies the first large-scale study of video understanding models from a neuroscience perspective. Our results in the simulated experiments, show that system identification can be attained to a certain level in differentiating image vs. video understanding models. Moreover, we provide key insights on how video understanding models predict visual cortex responses; showing video understanding better than image understanding models, convolutional models are better in the early-mid regions than transformer based except for multiscale transformers that are still good in predicting these regions, and that two-stream models are better than single stream.