 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiscale Video Transformers for Class Agnostic Segmentation in Autonomous Driving
Aug 20, 2025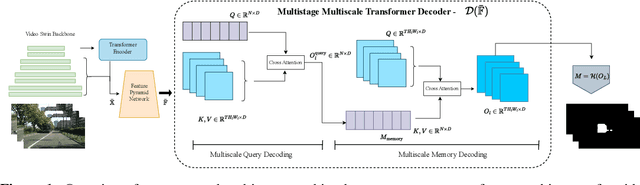

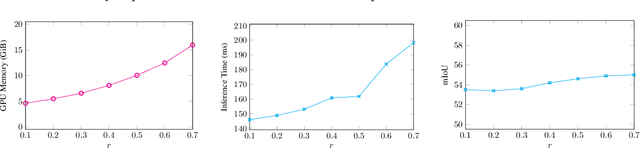
Ensuring safety in autonomous driving is a complex challenge requiring handling unknown objects and unforeseen driving scenarios. We develop multiscale video transformers capable of detecting unknown objects using only motion cues. Video semantic and panoptic segmentation often relies on known classes seen during training, overlooking novel categories. Recent visual grounding with large language models is computationally expensive, especially for pixel-level output. We propose an efficient video transformer trained end-to-end for class-agnostic segmentation without optical flow. Our method uses multi-stage multiscale query-memory decoding and a scale-specific random drop-token to ensure efficiency and accuracy, maintaining detailed spatiotemporal features with a shared, learnable memory module. Unlike conventional decoders that compress features, our memory-centric design preserves high-resolution information at multiple scales. We evaluate on DAVIS'16, KITTI, and Cityscapes. Our method consistently outperforms multiscale baselines while being efficient in GPU memory and run-time, demonstrating a promising direction for real-time, robust dense prediction in safety-critical robotics.
A Vision Centric Remote Sensing Benchmark
Mar 20, 2025Multimodal Large Language Models (MLLMs) have achieved remarkable success in vision-language tasks but their remote sensing (RS) counterpart are relatively under explored. Unlike natural images, RS imagery presents unique challenges that current MLLMs struggle to handle, particularly in visual grounding and spatial reasoning. This study investigates the limitations of CLIP-based MLLMs in RS, highlighting their failure to differentiate visually distinct yet semantically similar RS images. To address this, we introduce a remote sensing multimodal visual patterns (RSMMVP) benchmark. It is designed to evaluate MLLMs in RS tasks by identifying the CLIP-blind pairs, where CLIP-based models incorrectly assign high similarity scores to visually distinct RS images. Through a visual question answering (VQA) evaluation, we analyze the performance of state-of-the-art MLLMs, revealing significant limitations in RS specific representation learning. The results provide valuable insights into the weaknesses of CLIP-based visual encoding and offer a foundation for future research to develop more effective MLLMs tailored for remote sensing applications.
The Power of One: A Single Example is All it Takes for Segmentation in VLMs
Mar 13, 2025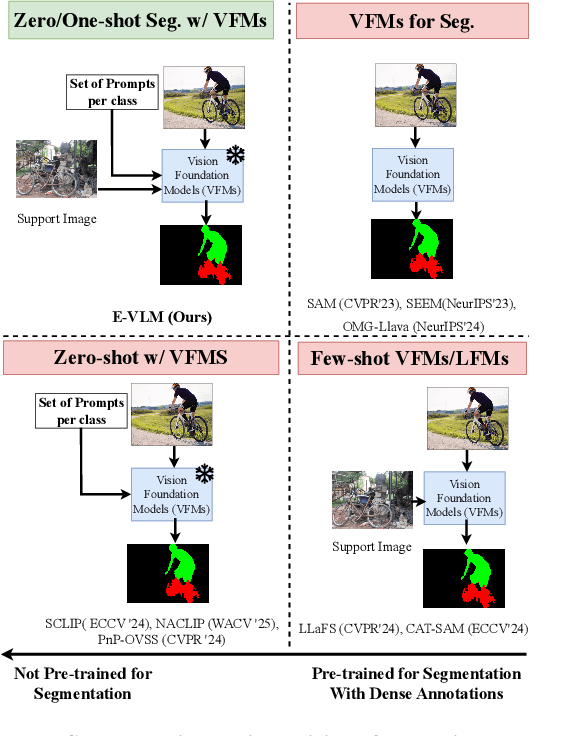
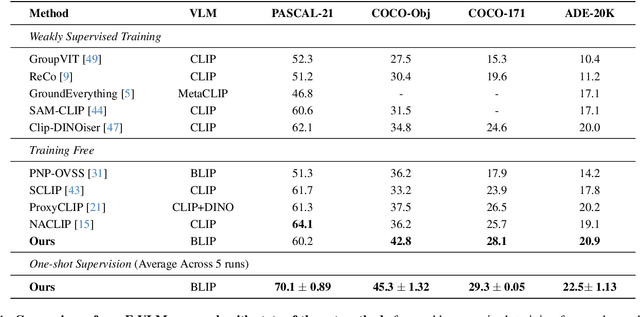
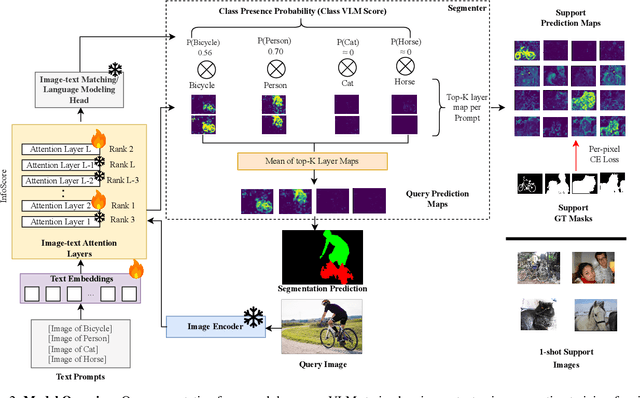
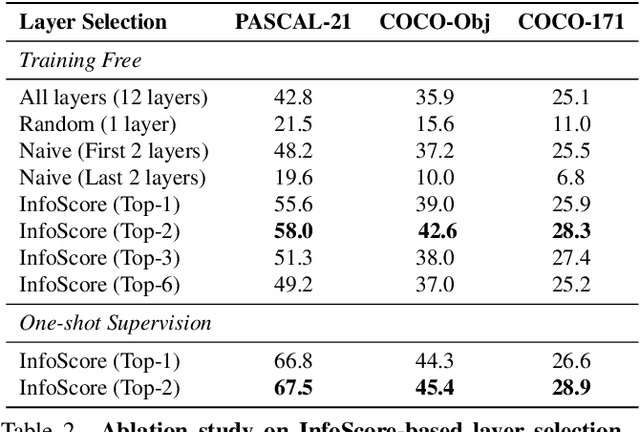
Large-scale vision-language models (VLMs), trained on extensive datasets of image-text pairs, exhibit strong multimodal understanding capabilities by implicitly learning associations between textual descriptions and image regions. This emergent ability enables zero-shot object detection and segmentation, using techniques that rely on text-image attention maps, without necessarily training on abundant labeled segmentation datasets. However, performance of such methods depends heavily on prompt engineering and manually selected layers or head choices for the attention layers. In this work, we demonstrate that, rather than relying solely on textual prompts, providing a single visual example for each category and fine-tuning the text-to-image attention layers and embeddings significantly improves the performance. Additionally, we propose learning an ensemble through few-shot fine-tuning across multiple layers and/or prompts. An entropy-based ranking and selection mechanism for text-to-image attention layers is proposed to identify the top-performing layers without the need for segmentation labels. This eliminates the need for hyper-parameter selection of text-to-image attention layers, providing a more flexible and scalable solution for open-vocabulary segmentation. We show that this approach yields strong zero-shot performance, further enhanced through fine-tuning with a single visual example. Moreover, we demonstrate that our method and findings are general and can be applied across various vision-language models (VLMs).
PixFoundation: Are We Heading in the Right Direction with Pixel-level Vision Foundation Models?
Feb 06, 2025Multiple works have emerged to push the boundaries on multi-modal large language models (MLLMs) towards pixel-level understanding. Such approaches have shown strong performance on benchmarks for referring expression segmentation and grounded conversation generation. The current trend in pixel-level MLLMs is to train with pixel-level grounding supervision on large-scale labelled data. However, we show that such MLLMs when evaluated on recent challenging vision centric benchmarks, exhibit a weak ability in visual question answering. Surprisingly, some of these methods even downgrade the grounding ability of MLLMs that were never trained with such supervision. In this work, we propose two novel challenging benchmarks and show that MLLMs without pixel-level grounding supervision can outperform the state of the art in such tasks when evaluating both the pixel-level grounding and visual question answering. We propose simple baselines to extract the grounding information that can be plugged into any MLLM, which we call as PixFoundation. More importantly, we study the research question of ``When does grounding emerge in MLLMs that are not trained with pixel-level grounding supervision?'' We show that grounding can coincide with object parts or location/appearance information. Code repository is at https://github.com/MSiam/PixFoundation/.
Generalized Few-Shot Semantic Segmentation in Remote Sensing: Challenge and Benchmark
Sep 17, 2024



Learning with limited labelled data is a challenging problem in various applications, including remote sensing. Few-shot semantic segmentation is one approach that can encourage deep learning models to learn from few labelled examples for novel classes not seen during the training. The generalized few-shot segmentation setting has an additional challenge which encourages models not only to adapt to the novel classes but also to maintain strong performance on the training base classes. While previous datasets and benchmarks discussed the few-shot segmentation setting in remote sensing, we are the first to propose a generalized few-shot segmentation benchmark for remote sensing. The generalized setting is more realistic and challenging, which necessitates exploring it within the remote sensing context. We release the dataset augmenting OpenEarthMap with additional classes labelled for the generalized few-shot evaluation setting. The dataset is released during the OpenEarthMap land cover mapping generalized few-shot challenge in the L3D-IVU workshop in conjunction with CVPR 2024. In this work, we summarize the dataset and challenge details in addition to providing the benchmark results on the two phases of the challenge for the validation and test sets.
Visual Prompting for Generalized Few-shot Segmentation: A Multi-scale Approach
Apr 17, 2024The emergence of attention-based transformer models has led to their extensive use in various tasks, due to their superior generalization and transfer properties. Recent research has demonstrated that such models, when prompted appropriately, are excellent for few-shot inference. However, such techniques are under-explored for dense prediction tasks like semantic segmentation. In this work, we examine the effectiveness of prompting a transformer-decoder with learned visual prompts for the generalized few-shot segmentation (GFSS) task. Our goal is to achieve strong performance not only on novel categories with limited examples, but also to retain performance on base categories. We propose an approach to learn visual prompts with limited examples. These learned visual prompts are used to prompt a multiscale transformer decoder to facilitate accurate dense predictions. Additionally, we introduce a unidirectional causal attention mechanism between the novel prompts, learned with limited examples, and the base prompts, learned with abundant data. This mechanism enriches the novel prompts without deteriorating the base class performance. Overall, this form of prompting helps us achieve state-of-the-art performance for GFSS on two different benchmark datasets: COCO-$20^i$ and Pascal-$5^i$, without the need for test-time optimization (or transduction). Furthermore, test-time optimization leveraging unlabelled test data can be used to improve the prompts, which we refer to as transductive prompt tuning.
System Identification of Neural Systems: Going Beyond Images to Modelling Dynamics
Feb 19, 2024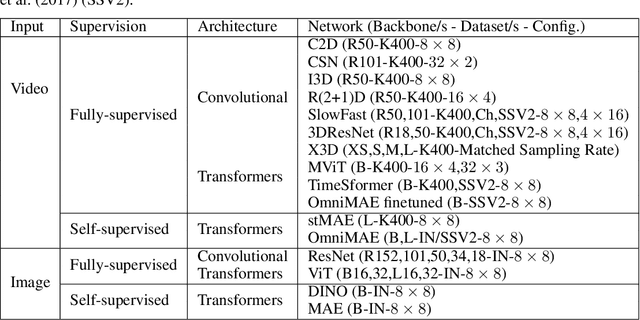
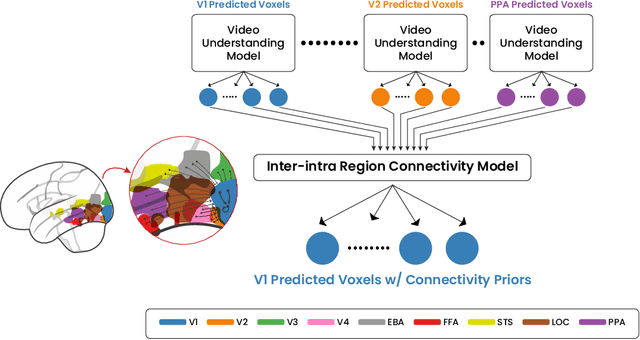
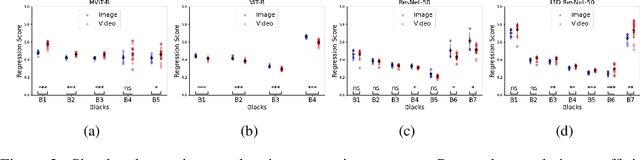

Vast literature has compared the recordings of biological neurons in the brain to deep neural networks. The ultimate goal is to interpret deep networks or to better understand and encode biological neural systems. Recently, there has been a debate on whether system identification is possible and how much it can tell us about the brain computation. System identification recognizes whether one model is more valid to represent the brain computation over another. Nonetheless, previous work did not consider the time aspect and how video and dynamics (e.g., motion) modelling in deep networks relate to these biological neural systems within a large-scale comparison. Towards this end, we propose a system identification study focused on comparing single image vs. video understanding models with respect to the visual cortex recordings. Our study encompasses two sets of experiments; a real environment setup and a simulated environment setup. The study also encompasses more than 30 models and, unlike prior works, we focus on convolutional vs. transformer-based, single vs. two-stream, and fully vs. self-supervised video understanding models. The goal is to capture a greater variety of architectures that model dynamics. As such, this signifies the first large-scale study of video understanding models from a neuroscience perspective. Our results in the simulated experiments, show that system identification can be attained to a certain level in differentiating image vs. video understanding models. Moreover, we provide key insights on how video understanding models predict visual cortex responses; showing video understanding better than image understanding models, convolutional models are better in the early-mid regions than transformer based except for multiscale transformers that are still good in predicting these regions, and that two-stream models are better than single stream.
A Survey on African Computer Vision Datasets, Topics and Researchers
Feb 04, 2024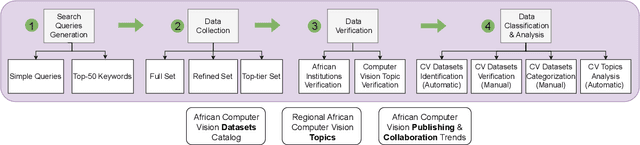


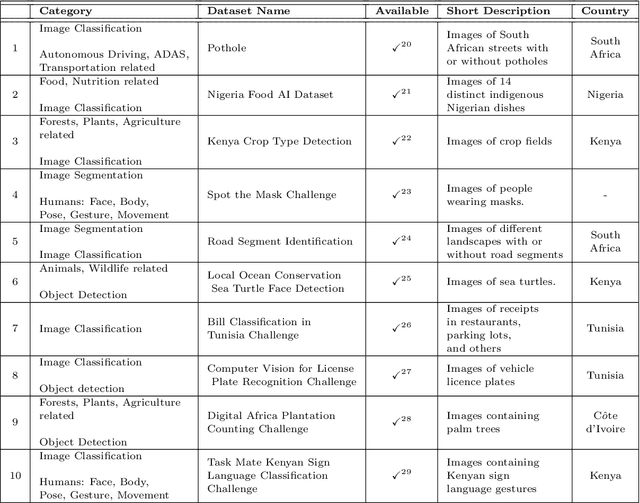
Computer vision encompasses a range of tasks such as object detection, semantic segmentation, and 3D reconstruction. Despite its relevance to African communities, research in this field within Africa represents only 0.06% of top-tier publications over the past decade. This study undertakes a thorough analysis of 63,000 Scopus-indexed computer vision publications from Africa, spanning from 2012 to 2022. The aim is to provide a survey of African computer vision topics, datasets and researchers. A key aspect of our study is the identification and categorization of African Computer Vision datasets using large language models that automatically parse abstracts of these publications. We also provide a compilation of unofficial African Computer Vision datasets distributed through challenges or data hosting platforms, and provide a full taxonomy of dataset categories. Our survey also pinpoints computer vision topics trends specific to different African regions, indicating their unique focus areas. Additionally, we carried out an extensive survey to capture the views of African researchers on the current state of computer vision research in the continent and the structural barriers they believe need urgent attention. In conclusion, this study catalogs and categorizes Computer Vision datasets and topics contributed or initiated by African institutions and identifies barriers to publishing in top-tier Computer Vision venues. This survey underscores the importance of encouraging African researchers and institutions in advancing computer vision research in the continent. It also stresses on the need for research topics to be more aligned with the needs of African communities.
M3T: Multi-Scale Memory Matching for Video Object Segmentation and Tracking
Dec 13, 2023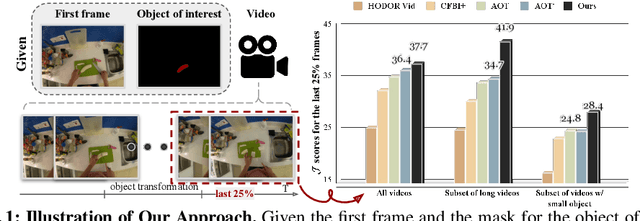

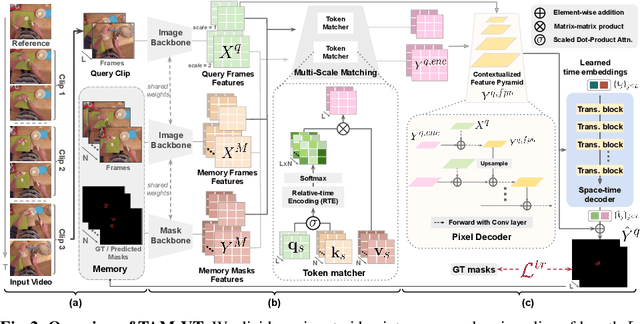
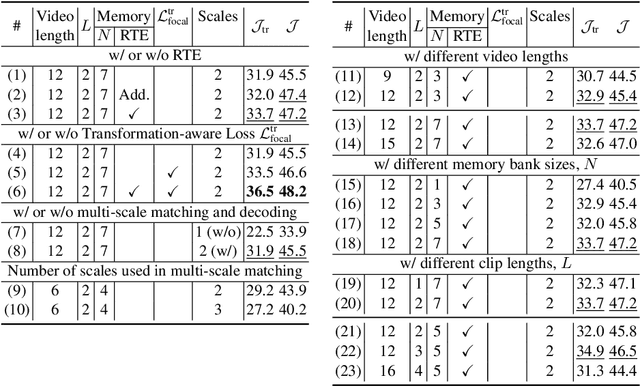
Video Object Segmentation (VOS) has became increasingly important with availability of larger datasets and more complex and realistic settings, which involve long videos with global motion (e.g, in egocentric settings), depicting small objects undergoing both rigid and non-rigid (including state) deformations. While a number of recent approaches have been explored for this task, these data characteristics still present challenges. In this work we propose a novel, DETR-style encoder-decoder architecture, which focuses on systematically analyzing and addressing aforementioned challenges. Specifically, our model enables on-line inference with long videos in a windowed fashion, by breaking the video into clips and propagating context among them using time-coded memory. We illustrate that short clip length and longer memory with learned time-coding are important design choices for achieving state-of-the-art (SoTA) performance. Further, we propose multi-scale matching and decoding to ensure sensitivity and accuracy for small objects. Finally, we propose a novel training strategy that focuses learning on portions of the video where an object undergoes significant deformations -- a form of "soft" hard-negative mining, implemented as loss-reweighting. Collectively, these technical contributions allow our model to achieve SoTA performance on two complex datasets -- VISOR and VOST. A series of detailed ablations validate our design choices as well as provide insights into the importance of parameter choices and their impact on performance.
Two-stage Joint Transductive and Inductive learning for Nuclei Segmentation
Nov 17, 2023AI-assisted nuclei segmentation in histopathological images is a crucial task in the diagnosis and treatment of cancer diseases. It decreases the time required to manually screen microscopic tissue images and can resolve the conflict between pathologists during diagnosis. Deep Learning has proven useful in such a task. However, lack of labeled data is a significant barrier for deep learning-based approaches. In this study, we propose a novel approach to nuclei segmentation that leverages the available labelled and unlabelled data. The proposed method combines the strengths of both transductive and inductive learning, which have been previously attempted separately, into a single framework. Inductive learning aims at approximating the general function and generalizing to unseen test data, while transductive learning has the potential of leveraging the unlabelled test data to improve the classification. To the best of our knowledge, this is the first study to propose such a hybrid approach for medical image segmentation. Moreover, we propose a novel two-stage transductive inference scheme. We evaluate our approach on MoNuSeg benchmark to demonstrate the efficacy and potential of our method.