 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCephRes-MHNet: A Multi-Head Residual Network for Accurate and Robust Cephalometric Landmark Detection
Nov 13, 2025Accurate localization of cephalometric landmarks from 2D lateral skull X-rays is vital for orthodontic diagnosis and treatment. Manual annotation is time-consuming and error-prone, whereas automated approaches often struggle with low contrast and anatomical complexity. This paper introduces CephRes-MHNet, a multi-head residual convolutional network for robust and efficient cephalometric landmark detection. The architecture integrates residual encoding, dual-attention mechanisms, and multi-head decoders to enhance contextual reasoning and anatomical precision. Trained on the Aariz Cephalometric dataset of 1,000 radiographs, CephRes-MHNet achieved a mean radial error (MRE) of 1.23 mm and a success detection rate (SDR) @ 2.0 mm of 85.5%, outperforming all evaluated models. In particular, it exceeded the strongest baseline, the attention-driven AFPF-Net (MRE = 1.25 mm, SDR @ 2.0 mm = 84.1%), while using less than 25% of its parameters. These results demonstrate that CephRes-MHNet attains state-of-the-art accuracy through architectural efficiency, providing a practical solution for real-world orthodontic analysis.
TFOC-Net: A Short-time Fourier Transform-based Deep Learning Approach for Enhancing Cross-Subject Motor Imagery Classification
Jul 03, 2025Cross-subject motor imagery (CS-MI) classification in brain-computer interfaces (BCIs) is a challenging task due to the significant variability in Electroencephalography (EEG) patterns across different individuals. This variability often results in lower classification accuracy compared to subject-specific models, presenting a major barrier to developing calibration-free BCIs suitable for real-world applications. In this paper, we introduce a novel approach that significantly enhances cross-subject MI classification performance through optimized preprocessing and deep learning techniques. Our approach involves direct classification of Short-Time Fourier Transform (STFT)-transformed EEG data, optimized STFT parameters, and a balanced batching strategy during training of a Convolutional Neural Network (CNN). This approach is uniquely validated across four different datasets, including three widely-used benchmark datasets leading to substantial improvements in cross-subject classification, achieving 67.60% on the BCI Competition IV Dataset 1 (IV-1), 65.96% on Dataset 2A (IV-2A), and 80.22% on Dataset 2B (IV-2B), outperforming state-of-the-art techniques. Additionally, we systematically investigate the classification performance using MI windows ranging from the full 4-second window to 1-second windows. These results establish a new benchmark for generalizable, calibration-free MI classification in addition to contributing a robust open-access dataset to advance research in this domain.
System Identification of Neural Systems: Going Beyond Images to Modelling Dynamics
Feb 19, 2024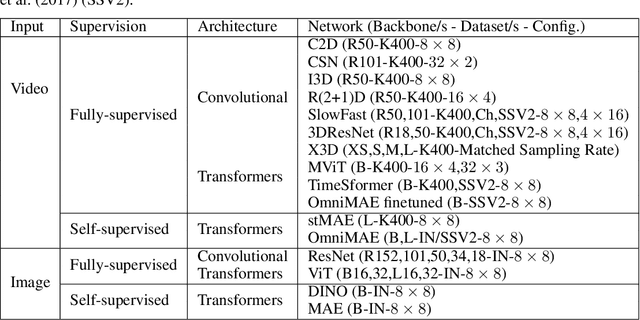
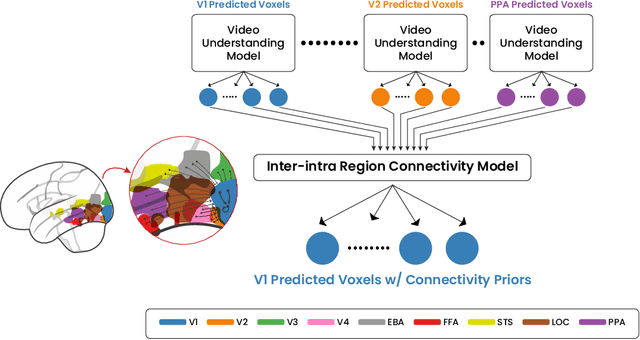
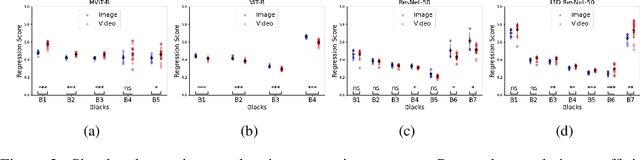

Vast literature has compared the recordings of biological neurons in the brain to deep neural networks. The ultimate goal is to interpret deep networks or to better understand and encode biological neural systems. Recently, there has been a debate on whether system identification is possible and how much it can tell us about the brain computation. System identification recognizes whether one model is more valid to represent the brain computation over another. Nonetheless, previous work did not consider the time aspect and how video and dynamics (e.g., motion) modelling in deep networks relate to these biological neural systems within a large-scale comparison. Towards this end, we propose a system identification study focused on comparing single image vs. video understanding models with respect to the visual cortex recordings. Our study encompasses two sets of experiments; a real environment setup and a simulated environment setup. The study also encompasses more than 30 models and, unlike prior works, we focus on convolutional vs. transformer-based, single vs. two-stream, and fully vs. self-supervised video understanding models. The goal is to capture a greater variety of architectures that model dynamics. As such, this signifies the first large-scale study of video understanding models from a neuroscience perspective. Our results in the simulated experiments, show that system identification can be attained to a certain level in differentiating image vs. video understanding models. Moreover, we provide key insights on how video understanding models predict visual cortex responses; showing video understanding better than image understanding models, convolutional models are better in the early-mid regions than transformer based except for multiscale transformers that are still good in predicting these regions, and that two-stream models are better than single stream.
A Brain-Computer Interface Augmented Reality Framework with Auto-Adaptive SSVEP Recognition
Aug 11, 2023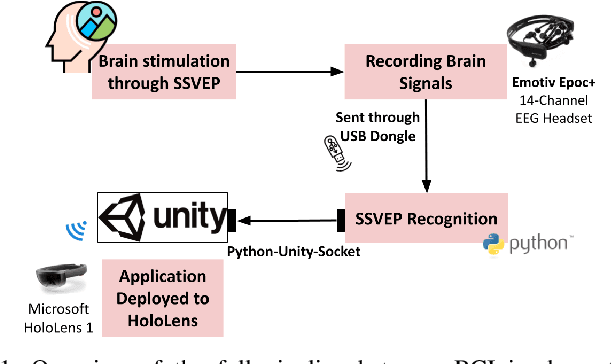
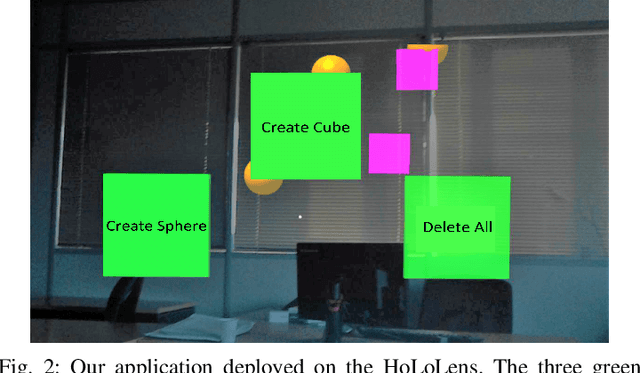

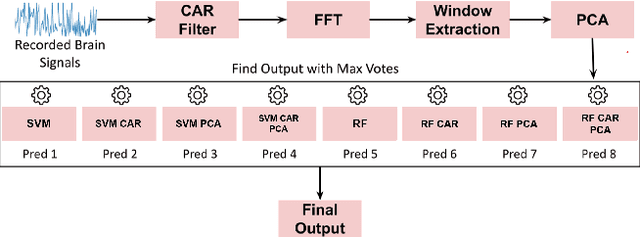
Brain-Computer Interface (BCI) initially gained attention for developing applications that aid physically impaired individuals. Recently, the idea of integrating BCI with Augmented Reality (AR) emerged, which uses BCI not only to enhance the quality of life for individuals with disabilities but also to develop mainstream applications for healthy users. One commonly used BCI signal pattern is the Steady-state Visually-evoked Potential (SSVEP), which captures the brain's response to flickering visual stimuli. SSVEP-based BCI-AR applications enable users to express their needs/wants by simply looking at corresponding command options. However, individuals are different in brain signals and thus require per-subject SSVEP recognition. Moreover, muscle movements and eye blinks interfere with brain signals, and thus subjects are required to remain still during BCI experiments, which limits AR engagement. In this paper, we (1) propose a simple adaptive ensemble classification system that handles the inter-subject variability, (2) present a simple BCI-AR framework that supports the development of a wide range of SSVEP-based BCI-AR applications, and (3) evaluate the performance of our ensemble algorithm in an SSVEP-based BCI-AR application with head rotations which has demonstrated robustness to the movement interference. Our testing on multiple subjects achieved a mean accuracy of 80\% on a PC and 77\% using the HoloLens AR headset, both of which surpass previous studies that incorporate individual classifiers and head movements. In addition, our visual stimulation time is 5 seconds which is relatively short. The statistically significant results show that our ensemble classification approach outperforms individual classifiers in SSVEP-based BCIs.