 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning What Can Be Picked: Active Reachability Estimation for Efficient Robotic Fruit Harvesting
Mar 24, 2026Agriculture remains a cornerstone of global health and economic sustainability, yet labor-intensive tasks such as harvesting high-value crops continue to face growing workforce shortages. Robotic harvesting systems offer a promising solution; however, their deployment in unstructured orchard environments is constrained by inefficient perception-to-action pipelines. In particular, existing approaches often rely on exhaustive inverse kinematics or motion planning to determine whether a target fruit is reachable, leading to unnecessary computation and delayed decision-making. Our approach combines RGB-D perception with active learning to directly learn reachability as a binary decision problem. We then leverage active learning to selectively query the most informative samples for reachability labeling, significantly reducing annotation effort while maintaining high predictive accuracy. Extensive experiments demonstrate that the proposed framework achieves accurate reachability prediction with substantially fewer labeled samples, yielding approximately 6--8% higher accuracy than random sampling and enabling label-efficient adaptation to new orchard configurations. Among the evaluated strategies, entropy- and margin-based sampling outperform Query-by-Committee and standard uncertainty sampling in low-label regimes, while all strategies converge to comparable performance as the labeled set grows. These results highlight the effectiveness of active learning for task-level perception in agricultural robotics and position our approach as a scalable alternative to computation-heavy kinematic reachability analysis. Our code is available through https://github.com/wsu-cyber-security-lab-ai/active-learning.
Prototype Fusion: A Training-Free Multi-Layer Approach to OOD Detection
Mar 24, 2026Deep learning models are increasingly deployed in safety-critical applications, where reliable out-of-distribution (OOD) detection is essential to ensure robustness. Existing methods predominantly rely on the penultimate-layer activations of neural networks, assuming they encapsulate the most informative in-distribution (ID) representations. In this work, we revisit this assumption to show that intermediate layers encode equally rich and discriminative information for OOD detection. Based on this observation, we propose a simple yet effective model-agnostic approach that leverages internal representations across multiple layers. Our scheme aggregates features from successive convolutional blocks, computes class-wise mean embeddings, and applies L_2 normalization to form compact ID prototypes capturing class semantics. During inference, cosine similarity between test features and these prototypes serves as an OOD score--ID samples exhibit strong affinity to at least one prototype, whereas OOD samples remain uniformly distant. Extensive experiments on state-of-the-art OOD benchmarks across diverse architectures demonstrate that our approach delivers robust, architecture-agnostic performance and strong generalization for image classification. Notably, it improves AUROC by up to 4.41% and reduces FPR by 13.58%, highlighting multi-layer feature aggregation as a powerful yet underexplored signal for OOD detection, challenging the dominance of penultimate-layer-based methods. Our code is available at: https://github.com/sgchr273/cosine-layers.git.
SecureGate: Learning When to Reveal PII Safely via Token-Gated Dual-Adapters for Federated LLMs
Feb 13, 2026Federated learning (FL) enables collaborative training across organizational silos without sharing raw data, making it attractive for privacy-sensitive applications. With the rapid adoption of large language models (LLMs), federated fine-tuning of generative LLMs has gained attention as a way to leverage distributed data while preserving confidentiality. However, this setting introduces fundamental challenges: (i) privacy leakage of personally identifiable information (PII) due to LLM memorization, and (ii) a persistent tension between global generalization and local utility under heterogeneous data. Existing defenses, such as data sanitization and differential privacy, reduce leakage but often degrade downstream performance. We propose SecureGate, a privacy-aware federated fine-tuning framework for LLMs that provides fine-grained privacy control without sacrificing utility. SecureGate employs a dual-adapter LoRA architecture: a secure adapter that learns sanitized, globally shareable representations, and a revealing adapter that captures sensitive, organization-specific knowledge. A token-controlled gating module selectively activates these adapters at inference time, enabling controlled information disclosure without retraining. Extensive experiments across multiple LLMs and real-world datasets show that SecureGate improves task utility while substantially reducing PII leakage, achieving up to a 31.66X reduction in inference attack accuracy and a 17.07X reduction in extraction recall for unauthorized requests. Additionally, it maintains 100% routing reliability to the correct adapter and incurs only minimal computational and communication overhead.
Explaining the Unseen: Multimodal Vision-Language Reasoning for Situational Awareness in Underground Mining Disasters
Dec 09, 2025
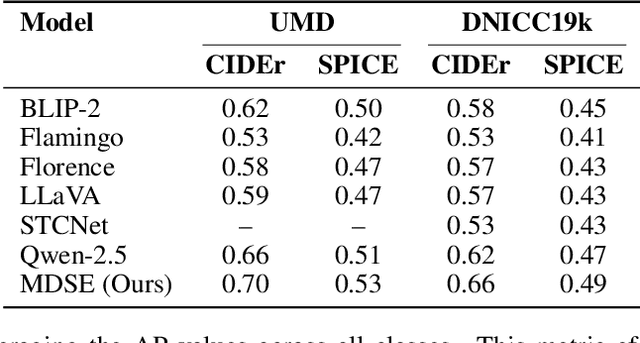
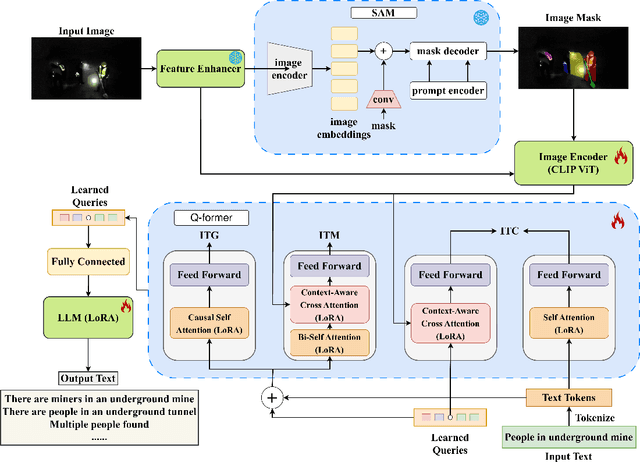

Underground mining disasters produce pervasive darkness, dust, and collapses that obscure vision and make situational awareness difficult for humans and conventional systems. To address this, we propose MDSE, Multimodal Disaster Situation Explainer, a novel vision-language framework that automatically generates detailed textual explanations of post-disaster underground scenes. MDSE has three-fold innovations: (i) Context-Aware Cross-Attention for robust alignment of visual and textual features even under severe degradation; (ii) Segmentation-aware dual pathway visual encoding that fuses global and region-specific embeddings; and (iii) Resource-Efficient Transformer-Based Language Model for expressive caption generation with minimal compute cost. To support this task, we present the Underground Mine Disaster (UMD) dataset--the first image-caption corpus of real underground disaster scenes--enabling rigorous training and evaluation. Extensive experiments on UMD and related benchmarks show that MDSE substantially outperforms state-of-the-art captioning models, producing more accurate and contextually relevant descriptions that capture crucial details in obscured environments, improving situational awareness for underground emergency response. The code is at https://github.com/mizanJewel/Multimodal-Disaster-Situation-Explainer.
Decentralized Trust for Space AI: Blockchain-Based Federated Learning Across Multi-Vendor LEO Satellite Networks
Dec 09, 2025The rise of space AI is reshaping government and industry through applications such as disaster detection, border surveillance, and climate monitoring, powered by massive data from commercial and governmental low Earth orbit (LEO) satellites. Federated satellite learning (FSL) enables joint model training without sharing raw data, but suffers from slow convergence due to intermittent connectivity and introduces critical trust challenges--where biased or falsified updates can arise across satellite constellations, including those injected through cyberattacks on inter-satellite or satellite-ground communication links. We propose OrbitChain, a blockchain-backed framework that empowers trustworthy multi-vendor collaboration in LEO networks. OrbitChain (i) offloads consensus to high-altitude platforms (HAPs) with greater computational capacity, (ii) ensures transparent, auditable provenance of model updates from different orbits owned by different vendors, and (iii) prevents manipulated or incomplete contributions from affecting global FSL model aggregation. Extensive simulations show that OrbitChain reduces computational and communication overhead while improving privacy, security, and global model accuracy. Its permissioned proof-of-authority ledger finalizes over 1000 blocks with sub-second latency (0.16,s, 0.26,s, 0.35,s for 1-of-5, 3-of-5, and 5-of-5 quorums). Moreover, OrbitChain reduces convergence time by up to 30 hours on real satellite datasets compared to single-vendor, demonstrating its effectiveness for real-time, multi-vendor learning. Our code is available at https://github.com/wsu-cyber-security-lab-ai/OrbitChain.git
Unlocking Neural Transparency: Jacobian Maps for Explainable AI in Alzheimer's Detection
Apr 04, 2025Alzheimer's disease (AD) leads to progressive cognitive decline, making early detection crucial for effective intervention. While deep learning models have shown high accuracy in AD diagnosis, their lack of interpretability limits clinical trust and adoption. This paper introduces a novel pre-model approach leveraging Jacobian Maps (JMs) within a multi-modal framework to enhance explainability and trustworthiness in AD detection. By capturing localized brain volume changes, JMs establish meaningful correlations between model predictions and well-known neuroanatomical biomarkers of AD. We validate JMs through experiments comparing a 3D CNN trained on JMs versus on traditional preprocessed data, which demonstrates superior accuracy. We also employ 3D Grad-CAM analysis to provide both visual and quantitative insights, further showcasing improved interpretability and diagnostic reliability.
DIS-Mine: Instance Segmentation for Disaster-Awareness in Poor-Light Condition in Underground Mines
Nov 20, 2024Detecting disasters in underground mining, such as explosions and structural damage, has been a persistent challenge over the years. This problem is compounded for first responders, who often have no clear information about the extent or nature of the damage within the mine. The poor-light or even total darkness inside the mines makes rescue efforts incredibly difficult, leading to a tragic loss of life. In this paper, we propose a novel instance segmentation method called DIS-Mine, specifically designed to identify disaster-affected areas within underground mines under low-light or poor visibility conditions, aiding first responders in rescue efforts. DIS-Mine is capable of detecting objects in images, even in complete darkness, by addressing challenges such as high noise, color distortions, and reduced contrast. The key innovations of DIS-Mine are built upon four core components: i) Image brightness improvement, ii) Instance segmentation with SAM integration, iii) Mask R-CNN-based segmentation, and iv) Mask alignment with feature matching. On top of that, we have collected real-world images from an experimental underground mine, introducing a new dataset named ImageMine, specifically gathered in low-visibility conditions. This dataset serves to validate the performance of DIS-Mine in realistic, challenging environments. Our comprehensive experiments on the ImageMine dataset, as well as on various other datasets demonstrate that DIS-Mine achieves a superior F1 score of 86.0% and mIoU of 72.0%, outperforming state-of-the-art instance segmentation methods, with at least 15x improvement and up to 80% higher precision in object detection.
LPLgrad: Optimizing Active Learning Through Gradient Norm Sample Selection and Auxiliary Model Training
Nov 20, 2024



Machine learning models are increasingly being utilized across various fields and tasks due to their outstanding performance and strong generalization capabilities. Nonetheless, their success hinges on the availability of large volumes of annotated data, the creation of which is often labor-intensive, time-consuming, and expensive. Many active learning (AL) approaches have been proposed to address these challenges, but they often fail to fully leverage the information from the core phases of AL, such as training on the labeled set and querying new unlabeled samples. To bridge this gap, we propose a novel AL approach, Loss Prediction Loss with Gradient Norm (LPLgrad), designed to quantify model uncertainty effectively and improve the accuracy of image classification tasks. LPLgrad operates in two distinct phases: (i) {\em Training Phase} aims to predict the loss for input features by jointly training a main model and an auxiliary model. Both models are trained on the labeled data to maximize the efficiency of the learning process, an aspect often overlooked in previous AL methods. This dual-model approach enhances the ability to extract complex input features and learn intrinsic patterns from the data effectively; (ii) {\em Querying Phase} that quantifies the uncertainty of the main model to guide sample selection. This is achieved by calculating the gradient norm of the entropy values for samples in the unlabeled dataset. Samples with the highest gradient norms are prioritized for labeling and subsequently added to the labeled set, improving the model's performance with minimal labeling effort. Extensive evaluations on real-world datasets demonstrate that the LPLgrad approach outperforms state-of-the-art methods by order of magnitude in terms of accuracy on a small number of labeled images, yet achieving comparable training and querying times in multiple image classification tasks.
Efficient Brain Imaging Analysis for Alzheimer's and Dementia Detection Using Convolution-Derivative Operations
Nov 20, 2024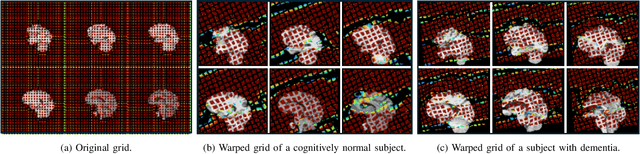
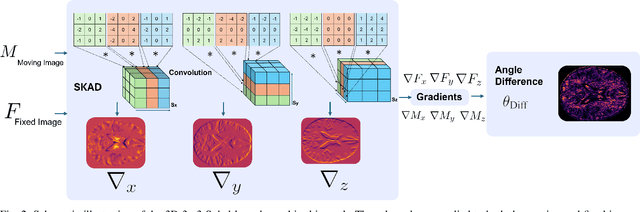
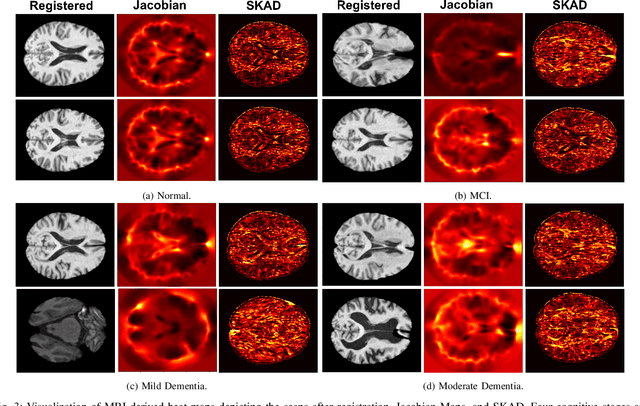
Alzheimer's disease (AD) is characterized by progressive neurodegeneration and results in detrimental structural changes in human brains. Detecting these changes is crucial for early diagnosis and timely intervention of disease progression. Jacobian maps, derived from spatial normalization in voxel-based morphometry (VBM), have been instrumental in interpreting volume alterations associated with AD. However, the computational cost of generating Jacobian maps limits its clinical adoption. In this study, we explore alternative methods and propose Sobel kernel angle difference (SKAD) as a computationally efficient alternative. SKAD is a derivative operation that offers an optimized approach to quantifying volumetric alterations through localized analysis of the gradients. By efficiently extracting gradient amplitude changes at critical spatial regions, this derivative operation captures regional volume variations Evaluation of SKAD over various medical datasets demonstrates that it is 6.3x faster than Jacobian maps while still maintaining comparable accuracy. This makes it an efficient and competitive approach in neuroimaging research and clinical practice.
FisherMask: Enhancing Neural Network Labeling Efficiency in Image Classification Using Fisher Information
Nov 08, 2024



Deep learning (DL) models are popular across various domains due to their remarkable performance and efficiency. However, their effectiveness relies heavily on large amounts of labeled data, which are often time-consuming and labor-intensive to generate manually. To overcome this challenge, it is essential to develop strategies that reduce reliance on extensive labeled data while preserving model performance. In this paper, we propose FisherMask, a Fisher information-based active learning (AL) approach that identifies key network parameters by masking them based on their Fisher information values. FisherMask enhances batch AL by using Fisher information to select the most critical parameters, allowing the identification of the most impactful samples during AL training. Moreover, Fisher information possesses favorable statistical properties, offering valuable insights into model behavior and providing a better understanding of the performance characteristics within the AL pipeline. Our extensive experiments demonstrate that FisherMask significantly outperforms state-of-the-art methods on diverse datasets, including CIFAR-10 and FashionMNIST, especially under imbalanced settings. These improvements lead to substantial gains in labeling efficiency. Hence serving as an effective tool to measure the sensitivity of model parameters to data samples. Our code is available on \url{https://github.com/sgchr273/FisherMask}.