 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototype Fusion: A Training-Free Multi-Layer Approach to OOD Detection
Mar 24, 2026Deep learning models are increasingly deployed in safety-critical applications, where reliable out-of-distribution (OOD) detection is essential to ensure robustness. Existing methods predominantly rely on the penultimate-layer activations of neural networks, assuming they encapsulate the most informative in-distribution (ID) representations. In this work, we revisit this assumption to show that intermediate layers encode equally rich and discriminative information for OOD detection. Based on this observation, we propose a simple yet effective model-agnostic approach that leverages internal representations across multiple layers. Our scheme aggregates features from successive convolutional blocks, computes class-wise mean embeddings, and applies L_2 normalization to form compact ID prototypes capturing class semantics. During inference, cosine similarity between test features and these prototypes serves as an OOD score--ID samples exhibit strong affinity to at least one prototype, whereas OOD samples remain uniformly distant. Extensive experiments on state-of-the-art OOD benchmarks across diverse architectures demonstrate that our approach delivers robust, architecture-agnostic performance and strong generalization for image classification. Notably, it improves AUROC by up to 4.41% and reduces FPR by 13.58%, highlighting multi-layer feature aggregation as a powerful yet underexplored signal for OOD detection, challenging the dominance of penultimate-layer-based methods. Our code is available at: https://github.com/sgchr273/cosine-layers.git.
Explaining the Unseen: Multimodal Vision-Language Reasoning for Situational Awareness in Underground Mining Disasters
Dec 09, 2025
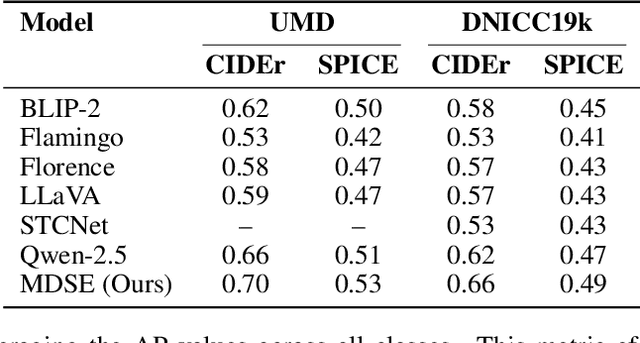
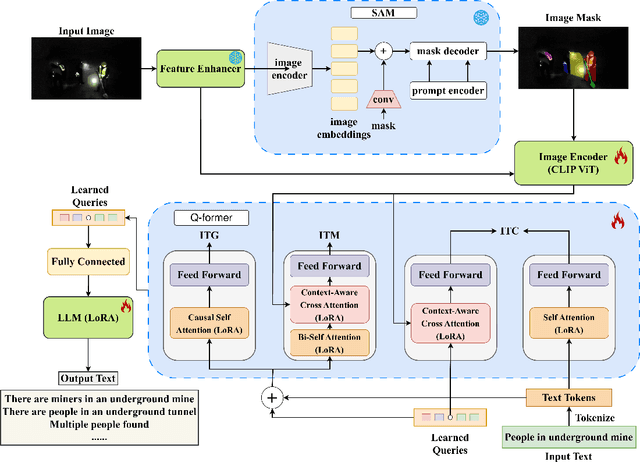

Underground mining disasters produce pervasive darkness, dust, and collapses that obscure vision and make situational awareness difficult for humans and conventional systems. To address this, we propose MDSE, Multimodal Disaster Situation Explainer, a novel vision-language framework that automatically generates detailed textual explanations of post-disaster underground scenes. MDSE has three-fold innovations: (i) Context-Aware Cross-Attention for robust alignment of visual and textual features even under severe degradation; (ii) Segmentation-aware dual pathway visual encoding that fuses global and region-specific embeddings; and (iii) Resource-Efficient Transformer-Based Language Model for expressive caption generation with minimal compute cost. To support this task, we present the Underground Mine Disaster (UMD) dataset--the first image-caption corpus of real underground disaster scenes--enabling rigorous training and evaluation. Extensive experiments on UMD and related benchmarks show that MDSE substantially outperforms state-of-the-art captioning models, producing more accurate and contextually relevant descriptions that capture crucial details in obscured environments, improving situational awareness for underground emergency response. The code is at https://github.com/mizanJewel/Multimodal-Disaster-Situation-Explainer.
SafeNav: Safe Path Navigation using Landmark Based Localization in a GPS-denied Environment
May 04, 2025



In battlefield environments, adversaries frequently disrupt GPS signals, requiring alternative localization and navigation methods. Traditional vision-based approaches like Simultaneous Localization and Mapping (SLAM) and Visual Odometry (VO) involve complex sensor fusion and high computational demand, whereas range-free methods like DV-HOP face accuracy and stability challenges in sparse, dynamic networks. This paper proposes LanBLoc-BMM, a navigation approach using landmark-based localization (LanBLoc) combined with a battlefield-specific motion model (BMM) and Extended Kalman Filter (EKF). Its performance is benchmarked against three state-of-the-art visual localization algorithms integrated with BMM and Bayesian filters, evaluated on synthetic and real-imitated trajectory datasets using metrics including Average Displacement Error (ADE), Final Displacement Error (FDE), and a newly introduced Average Weighted Risk Score (AWRS). LanBLoc-BMM (with EKF) demonstrates superior performance in ADE, FDE, and AWRS on real-imitated datasets. Additionally, two safe navigation methods, SafeNav-CHull and SafeNav-Centroid, are introduced by integrating LanBLoc-BMM(EKF) with a novel Risk-Aware RRT* (RAw-RRT*) algorithm for obstacle avoidance and risk exposure minimization. Simulation results in battlefield scenarios indicate SafeNav-Centroid excels in accuracy, risk exposure, and trajectory efficiency, while SafeNav-CHull provides superior computational speed.
LPLgrad: Optimizing Active Learning Through Gradient Norm Sample Selection and Auxiliary Model Training
Nov 20, 2024



Machine learning models are increasingly being utilized across various fields and tasks due to their outstanding performance and strong generalization capabilities. Nonetheless, their success hinges on the availability of large volumes of annotated data, the creation of which is often labor-intensive, time-consuming, and expensive. Many active learning (AL) approaches have been proposed to address these challenges, but they often fail to fully leverage the information from the core phases of AL, such as training on the labeled set and querying new unlabeled samples. To bridge this gap, we propose a novel AL approach, Loss Prediction Loss with Gradient Norm (LPLgrad), designed to quantify model uncertainty effectively and improve the accuracy of image classification tasks. LPLgrad operates in two distinct phases: (i) {\em Training Phase} aims to predict the loss for input features by jointly training a main model and an auxiliary model. Both models are trained on the labeled data to maximize the efficiency of the learning process, an aspect often overlooked in previous AL methods. This dual-model approach enhances the ability to extract complex input features and learn intrinsic patterns from the data effectively; (ii) {\em Querying Phase} that quantifies the uncertainty of the main model to guide sample selection. This is achieved by calculating the gradient norm of the entropy values for samples in the unlabeled dataset. Samples with the highest gradient norms are prioritized for labeling and subsequently added to the labeled set, improving the model's performance with minimal labeling effort. Extensive evaluations on real-world datasets demonstrate that the LPLgrad approach outperforms state-of-the-art methods by order of magnitude in terms of accuracy on a small number of labeled images, yet achieving comparable training and querying times in multiple image classification tasks.
DIS-Mine: Instance Segmentation for Disaster-Awareness in Poor-Light Condition in Underground Mines
Nov 20, 2024Detecting disasters in underground mining, such as explosions and structural damage, has been a persistent challenge over the years. This problem is compounded for first responders, who often have no clear information about the extent or nature of the damage within the mine. The poor-light or even total darkness inside the mines makes rescue efforts incredibly difficult, leading to a tragic loss of life. In this paper, we propose a novel instance segmentation method called DIS-Mine, specifically designed to identify disaster-affected areas within underground mines under low-light or poor visibility conditions, aiding first responders in rescue efforts. DIS-Mine is capable of detecting objects in images, even in complete darkness, by addressing challenges such as high noise, color distortions, and reduced contrast. The key innovations of DIS-Mine are built upon four core components: i) Image brightness improvement, ii) Instance segmentation with SAM integration, iii) Mask R-CNN-based segmentation, and iv) Mask alignment with feature matching. On top of that, we have collected real-world images from an experimental underground mine, introducing a new dataset named ImageMine, specifically gathered in low-visibility conditions. This dataset serves to validate the performance of DIS-Mine in realistic, challenging environments. Our comprehensive experiments on the ImageMine dataset, as well as on various other datasets demonstrate that DIS-Mine achieves a superior F1 score of 86.0% and mIoU of 72.0%, outperforming state-of-the-art instance segmentation methods, with at least 15x improvement and up to 80% higher precision in object detection.
FisherMask: Enhancing Neural Network Labeling Efficiency in Image Classification Using Fisher Information
Nov 08, 2024



Deep learning (DL) models are popular across various domains due to their remarkable performance and efficiency. However, their effectiveness relies heavily on large amounts of labeled data, which are often time-consuming and labor-intensive to generate manually. To overcome this challenge, it is essential to develop strategies that reduce reliance on extensive labeled data while preserving model performance. In this paper, we propose FisherMask, a Fisher information-based active learning (AL) approach that identifies key network parameters by masking them based on their Fisher information values. FisherMask enhances batch AL by using Fisher information to select the most critical parameters, allowing the identification of the most impactful samples during AL training. Moreover, Fisher information possesses favorable statistical properties, offering valuable insights into model behavior and providing a better understanding of the performance characteristics within the AL pipeline. Our extensive experiments demonstrate that FisherMask significantly outperforms state-of-the-art methods on diverse datasets, including CIFAR-10 and FashionMNIST, especially under imbalanced settings. These improvements lead to substantial gains in labeling efficiency. Hence serving as an effective tool to measure the sensitivity of model parameters to data samples. Our code is available on \url{https://github.com/sgchr273/FisherMask}.
CAV-AD: A Robust Framework for Detection of Anomalous Data and Malicious Sensors in CAV Networks
Jul 07, 2024The adoption of connected and automated vehicles (CAVs) has sparked considerable interest across diverse industries, including public transportation, underground mining, and agriculture sectors. However, CAVs' reliance on sensor readings makes them vulnerable to significant threats. Manipulating these readings can compromise CAV network security, posing serious risks for malicious activities. Although several anomaly detection (AD) approaches for CAV networks are proposed, they often fail to: i) detect multiple anomalies in specific sensor(s) with high accuracy or F1 score, and ii) identify the specific sensor being attacked. In response, this paper proposes a novel framework tailored to CAV networks, called CAV-AD, for distinguishing abnormal readings amidst multiple anomaly data while identifying malicious sensors. Specifically, CAV-AD comprises two main components: i) A novel CNN model architecture called optimized omni-scale CNN (O-OS-CNN), which optimally selects the time scale by generating all possible kernel sizes for input time series data; ii) An amplification block to increase the values of anomaly readings, enhancing sensitivity for detecting anomalies. Not only that, but CAV-AD integrates the proposed O-OS-CNN with a Kalman filter to instantly identify the malicious sensors. We extensively train CAV-AD using real-world datasets containing both instant and constant attacks, evaluating its performance in detecting intrusions from multiple anomalies, which presents a more challenging scenario. Our results demonstrate that CAV-AD outperforms state-of-the-art methods, achieving an average accuracy of 98% and an average F1 score of 89\%, while accurately identifying the malicious sensors.
Secure Navigation using Landmark-based Localization in a GPS-denied Environment
Feb 22, 2024



In modern battlefield scenarios, the reliance on GPS for navigation can be a critical vulnerability. Adversaries often employ tactics to deny or deceive GPS signals, necessitating alternative methods for the localization and navigation of mobile troops. Range-free localization methods such as DV-HOP rely on radio-based anchors and their average hop distance which suffers from accuracy and stability in a dynamic and sparse network topology. Vision-based approaches like SLAM and Visual Odometry use sensor fusion techniques for map generation and pose estimation that are more sophisticated and computationally expensive. This paper proposes a novel framework that integrates landmark-based localization (LanBLoc) with an Extended Kalman Filter (EKF) to predict the future state of moving entities along the battlefield. Our framework utilizes safe trajectory information generated by the troop control center by considering identifiable landmarks and pre-defined hazard maps. It performs point inclusion tests on the convex hull of the trajectory segments to ensure the safety and survivability of a moving entity and determines the next point forward decisions. We present a simulated battlefield scenario for two different approaches (with EKF and without EKF) that guide a moving entity through an obstacle and hazard-free path. Using the proposed method, we observed a percent error of 6.51% lengthwise in safe trajectory estimation with an Average Displacement Error (ADE) of 2.97m and a Final Displacement Error (FDE) of 3.27m. The results demonstrate that our approach not only ensures the safety of the mobile units by keeping them within the secure trajectory but also enhances operational effectiveness by adapting to the evolving threat landscape.
Landmark-based Localization using Stereo Vision and Deep Learning in GPS-Denied Battlefield Environment
Feb 19, 2024Localization in a battlefield environment is increasingly challenging as GPS connectivity is often denied or unreliable, and physical deployment of anchor nodes across wireless networks for localization can be difficult in hostile battlefield terrain. Existing range-free localization methods rely on radio-based anchors and their average hop distance which suffers from accuracy and stability in dynamic and sparse wireless network topology. Vision-based methods like SLAM and Visual Odometry use expensive sensor fusion techniques for map generation and pose estimation. This paper proposes a novel framework for localization in non-GPS battlefield environments using only the passive camera sensors and considering naturally existing or artificial landmarks as anchors. The proposed method utilizes a customcalibrated stereo vision camera for distance estimation and the YOLOv8s model, which is trained and fine-tuned with our real-world dataset for landmark recognition. The depth images are generated using an efficient stereomatching algorithm, and distances to landmarks are determined by extracting the landmark depth feature utilizing a bounding box predicted by the landmark recognition model. The position of the unknown node is then obtained using the efficient least square algorithm and then optimized using the L-BFGS-B (limited-memory quasi-Newton code for bound-constrained optimization) method. Experimental results demonstrate that our proposed framework performs better than existing anchorbased DV-Hop algorithms and competes with the most efficient vision-based algorithms in terms of localization error (RMSE).
Landmark Stereo Dataset for Landmark Recognition and Moving Node Localization in a Non-GPS Battlefield Environment
Feb 19, 2024In this paper, we have proposed a new strategy of using the landmark anchor node instead of a radio-based anchor node to obtain the virtual coordinates (landmarkID, DISTANCE) of moving troops or defense forces that will help in tracking and maneuvering the troops along a safe path within a GPS-denied battlefield environment. The proposed strategy implements landmark recognition using the Yolov5 model and landmark distance estimation using an efficient Stereo Matching Algorithm. We consider that a moving node carrying a low-power mobile device facilitated with a calibrated stereo vision camera that captures stereo images of a scene containing landmarks within the battlefield region whose locations are stored in an offline server residing within the device itself. We created a custom landmark image dataset called MSTLandmarkv1 with 34 landmark classes and another landmark stereo dataset of those 34 landmark instances called MSTLandmarkStereov1. We trained the YOLOv5 model with MSTLandmarkv1 dataset and achieved 0.95 mAP @ 0.5 IoU and 0.767 mAP @ [0.5: 0.95] IoU. We calculated the distance from a node to the landmark utilizing the bounding box coordinates and the depth map generated by the improved SGM algorithm using MSTLandmarkStereov1. The tuple of landmark IDs obtained from the detection result and the distances calculated by the SGM algorithm are stored as the virtual coordinates of a node. In future work, we will use these virtual coordinates to obtain the location of a node using an efficient trilateration algorithm and optimize the node position using the appropriate optimization method.