 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic-Nougat: Fine-Tuning Vision Transformers for Arabic OCR and Markdown Extraction
Nov 19, 2024We present Arabic-Nougat, a suite of OCR models for converting Arabic book pages into structured Markdown text. Based on Meta's Nougat architecture, Arabic-Nougat includes three specialized models: arabic-small-nougat, arabic-base-nougat, and arabic-large-nougat. These models are fine-tuned on a synthetic dataset, arabic-img2md, comprising 13.7k pairs of Arabic book pages and their Markdown representations. Key contributions include the Aranizer-PBE-86k tokenizer, designed for efficient tokenization, and the use of torch.bfloat16 precision with Flash Attention 2 for optimized training and inference. Our models achieve state-of-the-art performance, with arabic-large-nougat delivering the highest Markdown Structure Accuracy and the lowest Character Error Rate. Additionally, we release a large-scale dataset containing 1.1 billion Arabic tokens extracted from over 8,500 books using our best-performing model, providing a valuable resource for Arabic OCR research. All models, datasets, and code are open-sourced and available at https://github.com/MohamedAliRashad/arabic-nougat.
TabVFL: Improving Latent Representation in Vertical Federated Learning
Apr 27, 2024Autoencoders are popular neural networks that are able to compress high dimensional data to extract relevant latent information. TabNet is a state-of-the-art neural network model designed for tabular data that utilizes an autoencoder architecture for training. Vertical Federated Learning (VFL) is an emerging distributed machine learning paradigm that allows multiple parties to train a model collaboratively on vertically partitioned data while maintaining data privacy. The existing design of training autoencoders in VFL is to train a separate autoencoder in each participant and aggregate the latent representation later. This design could potentially break important correlations between feature data of participating parties, as each autoencoder is trained on locally available features while disregarding the features of others. In addition, traditional autoencoders are not specifically designed for tabular data, which is ubiquitous in VFL settings. Moreover, the impact of client failures during training on the model robustness is under-researched in the VFL scene. In this paper, we propose TabVFL, a distributed framework designed to improve latent representation learning using the joint features of participants. The framework (i) preserves privacy by mitigating potential data leakage with the addition of a fully-connected layer, (ii) conserves feature correlations by learning one latent representation vector, and (iii) provides enhanced robustness against client failures during training phase. Extensive experiments on five classification datasets show that TabVFL can outperform the prior work design, with 26.12% of improvement on f1-score.
System Identification of Neural Systems: Going Beyond Images to Modelling Dynamics
Feb 19, 2024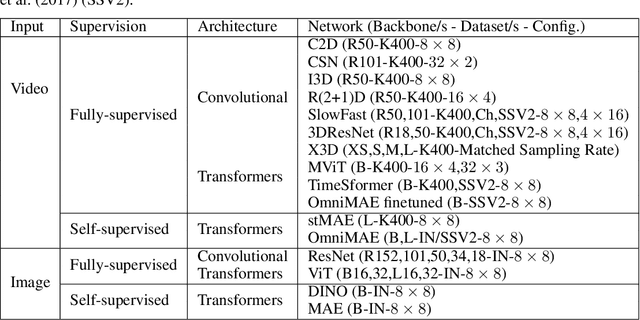
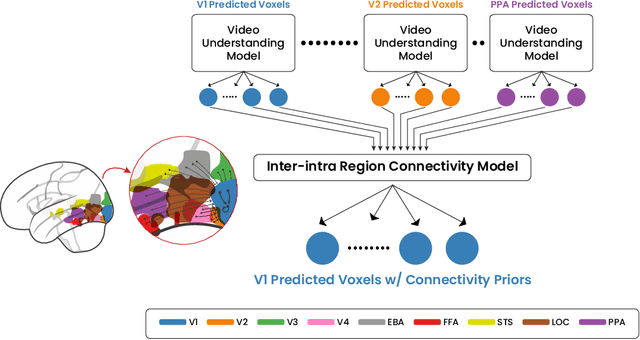
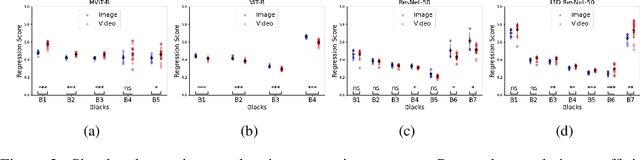

Vast literature has compared the recordings of biological neurons in the brain to deep neural networks. The ultimate goal is to interpret deep networks or to better understand and encode biological neural systems. Recently, there has been a debate on whether system identification is possible and how much it can tell us about the brain computation. System identification recognizes whether one model is more valid to represent the brain computation over another. Nonetheless, previous work did not consider the time aspect and how video and dynamics (e.g., motion) modelling in deep networks relate to these biological neural systems within a large-scale comparison. Towards this end, we propose a system identification study focused on comparing single image vs. video understanding models with respect to the visual cortex recordings. Our study encompasses two sets of experiments; a real environment setup and a simulated environment setup. The study also encompasses more than 30 models and, unlike prior works, we focus on convolutional vs. transformer-based, single vs. two-stream, and fully vs. self-supervised video understanding models. The goal is to capture a greater variety of architectures that model dynamics. As such, this signifies the first large-scale study of video understanding models from a neuroscience perspective. Our results in the simulated experiments, show that system identification can be attained to a certain level in differentiating image vs. video understanding models. Moreover, we provide key insights on how video understanding models predict visual cortex responses; showing video understanding better than image understanding models, convolutional models are better in the early-mid regions than transformer based except for multiscale transformers that are still good in predicting these regions, and that two-stream models are better than single stream.