 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of One: A Single Example is All it Takes for Segmentation in VLMs
Paper and Code
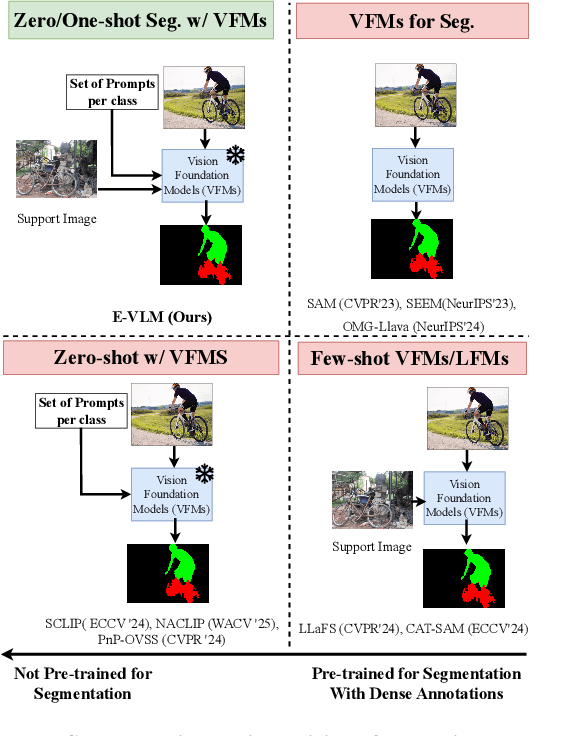
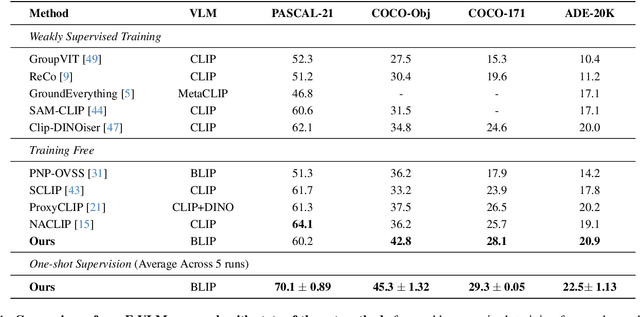
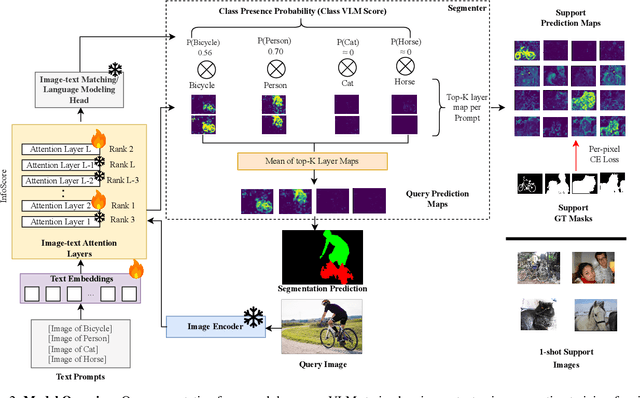
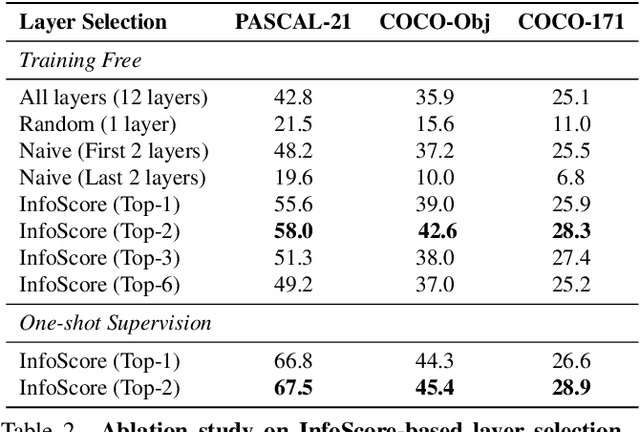
Large-scale vision-language models (VLMs), trained on extensive datasets of image-text pairs, exhibit strong multimodal understanding capabilities by implicitly learning associations between textual descriptions and image regions. This emergent ability enables zero-shot object detection and segmentation, using techniques that rely on text-image attention maps, without necessarily training on abundant labeled segmentation datasets. However, performance of such methods depends heavily on prompt engineering and manually selected layers or head choices for the attention layers. In this work, we demonstrate that, rather than relying solely on textual prompts, providing a single visual example for each category and fine-tuning the text-to-image attention layers and embeddings significantly improves the performance. Additionally, we propose learning an ensemble through few-shot fine-tuning across multiple layers and/or prompts. An entropy-based ranking and selection mechanism for text-to-image attention layers is proposed to identify the top-performing layers without the need for segmentation labels. This eliminates the need for hyper-parameter selection of text-to-image attention layers, providing a more flexible and scalable solution for open-vocabulary segmentation. We show that this approach yields strong zero-shot performance, further enhanced through fine-tuning with a single visual example. Moreover, we demonstrate that our method and findings are general and can be applied across various vision-language models (VLMs).