 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Benefit from User and Item Embeddings in Recommendation Tasks?
Jan 08, 2026Large Language Models (LLMs) have emerged as promising recommendation systems, offering novel ways to model user preferences through generative approaches. However, many existing methods often rely solely on text semantics or incorporate collaborative signals in a limited manner, typically using only user or item embeddings. These methods struggle to handle multiple item embeddings representing user history, reverting to textual semantics and neglecting richer collaborative information. In this work, we propose a simple yet effective solution that projects user and item embeddings, learned from collaborative filtering, into the LLM token space via separate lightweight projector modules. A finetuned LLM then conditions on these projected embeddings alongside textual tokens to generate recommendations. Preliminary results show that this design effectively leverages structured user-item interaction data, improves recommendation performance over text-only LLM baselines, and offers a practical path for bridging traditional recommendation systems with modern LLMs.
ChartGaze: Enhancing Chart Understanding in LVLMs with Eye-Tracking Guided Attention Refinement
Sep 16, 2025Charts are a crucial visual medium for communicating and representing information. While Large Vision-Language Models (LVLMs) have made progress on chart question answering (CQA), the task remains challenging, particularly when models attend to irrelevant regions of the chart. In this work, we present ChartGaze, a new eye-tracking dataset that captures human gaze patterns during chart reasoning tasks. Through a systematic comparison of human and model attention, we find that LVLMs often diverge from human gaze, leading to reduced interpretability and accuracy. To address this, we propose a gaze-guided attention refinement that aligns image-text attention with human fixations. Our approach improves both answer accuracy and attention alignment, yielding gains of up to 2.56 percentage points across multiple models. These results demonstrate the promise of incorporating human gaze to enhance both the reasoning quality and interpretability of chart-focused LVLMs.
The Power of One: A Single Example is All it Takes for Segmentation in VLMs
Mar 13, 2025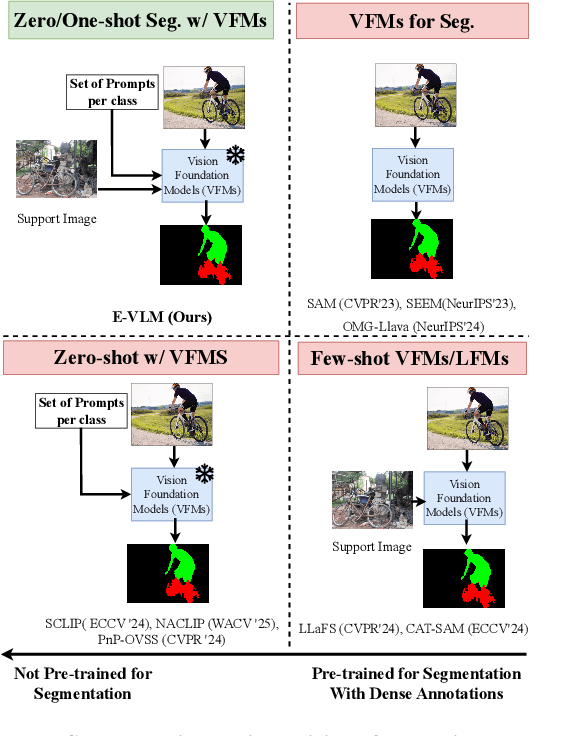
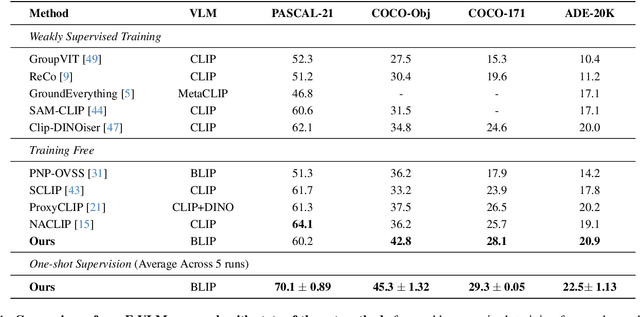
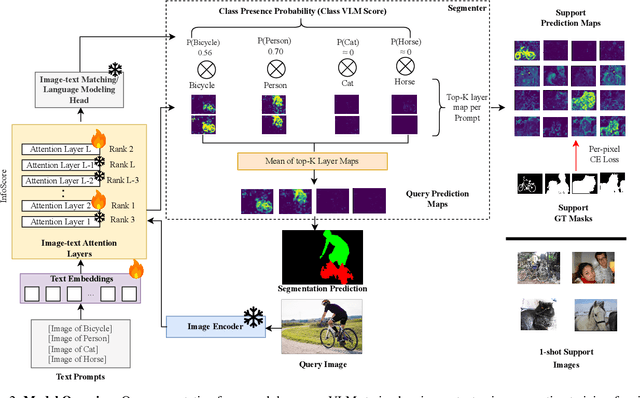
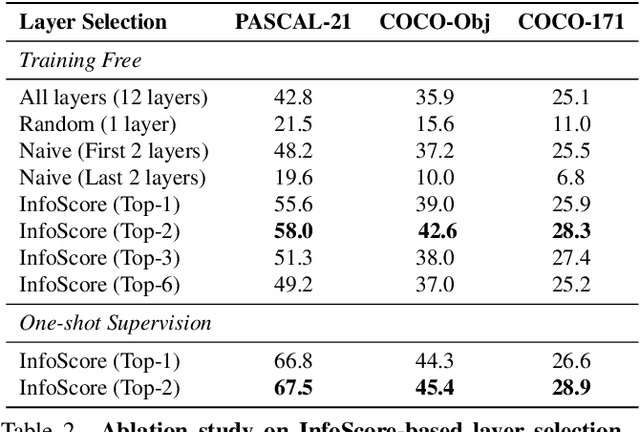
Large-scale vision-language models (VLMs), trained on extensive datasets of image-text pairs, exhibit strong multimodal understanding capabilities by implicitly learning associations between textual descriptions and image regions. This emergent ability enables zero-shot object detection and segmentation, using techniques that rely on text-image attention maps, without necessarily training on abundant labeled segmentation datasets. However, performance of such methods depends heavily on prompt engineering and manually selected layers or head choices for the attention layers. In this work, we demonstrate that, rather than relying solely on textual prompts, providing a single visual example for each category and fine-tuning the text-to-image attention layers and embeddings significantly improves the performance. Additionally, we propose learning an ensemble through few-shot fine-tuning across multiple layers and/or prompts. An entropy-based ranking and selection mechanism for text-to-image attention layers is proposed to identify the top-performing layers without the need for segmentation labels. This eliminates the need for hyper-parameter selection of text-to-image attention layers, providing a more flexible and scalable solution for open-vocabulary segmentation. We show that this approach yields strong zero-shot performance, further enhanced through fine-tuning with a single visual example. Moreover, we demonstrate that our method and findings are general and can be applied across various vision-language models (VLMs).
Barking Up The Syntactic Tree: Enhancing VLM Training with Syntactic Losses
Dec 11, 2024Vision-Language Models (VLMs) achieved strong performance on a variety of tasks (e.g., image-text retrieval, visual question answering). However, most VLMs rely on coarse-grained image-caption pairs for alignment, relying on data volume to resolve ambiguities and ground linguistic concepts in images. The richer semantic and syntactic structure within text is largely overlooked. To address this, we propose HIerarchically STructured Learning (HIST) that enhances VLM training without any additional supervision, by hierarchically decomposing captions into the constituent Subject, Noun Phrases, and Composite Phrases. Entailment between these constituent components allows us to formulate additional regularization constraints on the VLM attention maps. Specifically, we introduce two novel loss functions: (1) Subject Loss, which aligns image content with the subject of corresponding phrase, acting as an entailment of standard contrastive/matching losses at the Phrase level; (2) Addition Loss, to balance attention across multiple objects. HIST is general, and can be applied to any VLM for which attention between vision and language can be computed; we illustrate its efficacy on BLIP and ALBEF. HIST outperforms baseline VLMs, achieving up to +9.8% improvement in visual grounding, +6.3% in multi-object referring segmentation, +1.1% in image-text retrieval, and +0.2% in visual question answering, underscoring the value of structuring learning in VLMs.
Visual Prompting for Generalized Few-shot Segmentation: A Multi-scale Approach
Apr 17, 2024The emergence of attention-based transformer models has led to their extensive use in various tasks, due to their superior generalization and transfer properties. Recent research has demonstrated that such models, when prompted appropriately, are excellent for few-shot inference. However, such techniques are under-explored for dense prediction tasks like semantic segmentation. In this work, we examine the effectiveness of prompting a transformer-decoder with learned visual prompts for the generalized few-shot segmentation (GFSS) task. Our goal is to achieve strong performance not only on novel categories with limited examples, but also to retain performance on base categories. We propose an approach to learn visual prompts with limited examples. These learned visual prompts are used to prompt a multiscale transformer decoder to facilitate accurate dense predictions. Additionally, we introduce a unidirectional causal attention mechanism between the novel prompts, learned with limited examples, and the base prompts, learned with abundant data. This mechanism enriches the novel prompts without deteriorating the base class performance. Overall, this form of prompting helps us achieve state-of-the-art performance for GFSS on two different benchmark datasets: COCO-$20^i$ and Pascal-$5^i$, without the need for test-time optimization (or transduction). Furthermore, test-time optimization leveraging unlabelled test data can be used to improve the prompts, which we refer to as transductive prompt tuning.
Semantically Enhanced Global Reasoning for Semantic Segmentation
Dec 06, 2022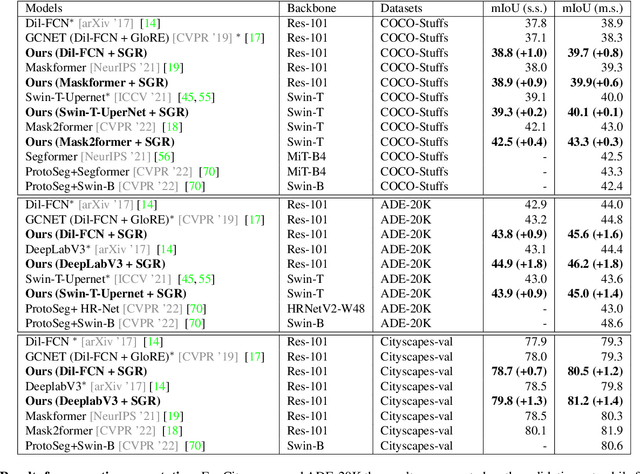
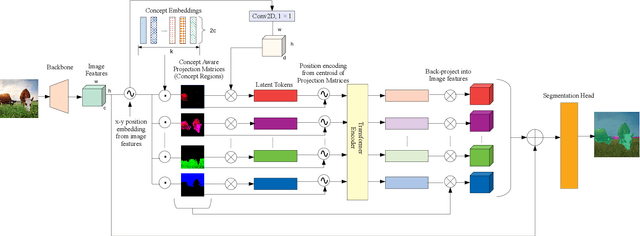
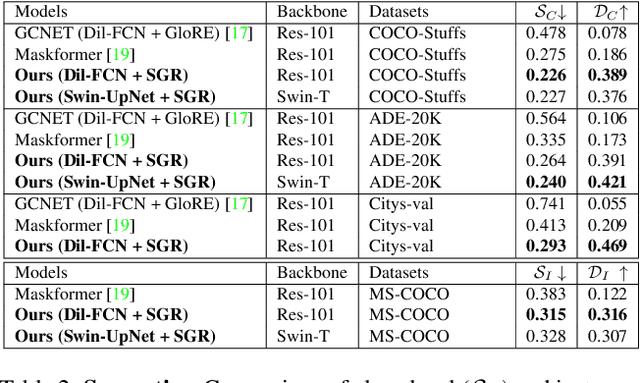

Recent advances in pixel-level tasks (e.g., segmentation) illustrate the benefit of long-range interactions between aggregated region-based representations that can enhance local features. However, such pixel-to-region associations and the resulting representation, which often take the form of attention, cannot model the underlying semantic structure of the scene (e.g., individual objects and, by extension, their interactions). In this work, we take a step toward addressing this limitation. Specifically, we propose an architecture where we learn to project image features into latent region representations and perform global reasoning across them, using a transformer, to produce contextualized and scene-consistent representations that are then fused with original pixel-level features. Our design enables the latent regions to represent semantically meaningful concepts, by ensuring that activated regions are spatially disjoint and unions of such regions correspond to connected object segments. The resulting semantic global reasoning (SGR) is end-to-end trainable and can be combined with any semantic segmentation framework and backbone. Combining SGR with DeepLabV3 results in a semantic segmentation performance that is competitive to the state-of-the-art, while resulting in more semantically interpretable and diverse region representations, which we show can effectively transfer to detection and instance segmentation. Further, we propose a new metric that allows us to measure the semantics of representations at both the object class and instance level.
Exploiting temporal information for 3D pose estimation
Sep 12, 2018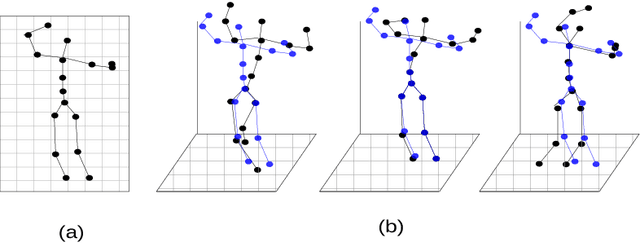
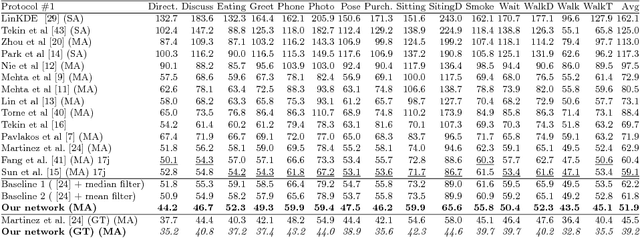
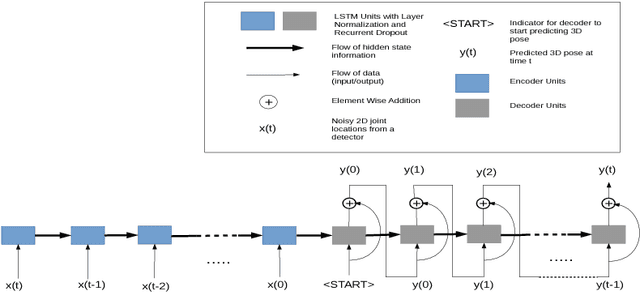

In this work, we address the problem of 3D human pose estimation from a sequence of 2D human poses. Although the recent success of deep networks has led many state-of-the-art methods for 3D pose estimation to train deep networks end-to-end to predict from images directly, the top-performing approaches have shown the effectiveness of dividing the task of 3D pose estimation into two steps: using a state-of-the-art 2D pose estimator to estimate the 2D pose from images and then mapping them into 3D space. They also showed that a low-dimensional representation like 2D locations of a set of joints can be discriminative enough to estimate 3D pose with high accuracy. However, estimation of 3D pose for individual frames leads to temporally incoherent estimates due to independent error in each frame causing jitter. Therefore, in this work we utilize the temporal information across a sequence of 2D joint locations to estimate a sequence of 3D poses. We designed a sequence-to-sequence network composed of layer-normalized LSTM units with shortcut connections connecting the input to the output on the decoder side and imposed temporal smoothness constraint during training. We found that the knowledge of temporal consistency improves the best reported result on Human3.6M dataset by approximately $12.2\%$ and helps our network to recover temporally consistent 3D poses over a sequence of images even when the 2D pose detector fails.