 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinted Frames: Question Framing Blinds Vision-Language Models
Mar 19, 2026Vision-Language Models (VLMs) have been shown to be blind, often underutilizing their visual inputs even on tasks that require visual reasoning. In this work, we demonstrate that VLMs are selectively blind. They modulate the amount of attention applied to visual inputs based on linguistic framing even when alternative framings demand identical visual reasoning. Using visual attention as a probe, we quantify how framing alters both the amount and distribution of attention over the image. Constrained framings, such as multiple choice and yes/no, induce substantially lower attention to image context compared to open-ended, reduce focus on task-relevant regions, and shift attention towards uninformative tokens. We further demonstrate that this attention misallocation is the principal cause of degraded accuracy and cross-framing inconsistency. Building on this mechanistic insight, we introduce a lightweight prompt-tuning method using learnable tokens that encourages the robust, visually grounded attention patterns observed in open-ended settings, improving visual grounding and improving performance across framings.
ChartGaze: Enhancing Chart Understanding in LVLMs with Eye-Tracking Guided Attention Refinement
Sep 16, 2025Charts are a crucial visual medium for communicating and representing information. While Large Vision-Language Models (LVLMs) have made progress on chart question answering (CQA), the task remains challenging, particularly when models attend to irrelevant regions of the chart. In this work, we present ChartGaze, a new eye-tracking dataset that captures human gaze patterns during chart reasoning tasks. Through a systematic comparison of human and model attention, we find that LVLMs often diverge from human gaze, leading to reduced interpretability and accuracy. To address this, we propose a gaze-guided attention refinement that aligns image-text attention with human fixations. Our approach improves both answer accuracy and attention alignment, yielding gains of up to 2.56 percentage points across multiple models. These results demonstrate the promise of incorporating human gaze to enhance both the reasoning quality and interpretability of chart-focused LVLMs.
MMFactory: A Universal Solution Search Engine for Vision-Language Tasks
Dec 24, 2024With advances in foundational and vision-language models, and effective fine-tuning techniques, a large number of both general and special-purpose models have been developed for a variety of visual tasks. Despite the flexibility and accessibility of these models, no single model is able to handle all tasks and/or applications that may be envisioned by potential users. Recent approaches, such as visual programming and multimodal LLMs with integrated tools aim to tackle complex visual tasks, by way of program synthesis. However, such approaches overlook user constraints (e.g., performance / computational needs), produce test-time sample-specific solutions that are difficult to deploy, and, sometimes, require low-level instructions that maybe beyond the abilities of a naive user. To address these limitations, we introduce MMFactory, a universal framework that includes model and metrics routing components, acting like a solution search engine across various available models. Based on a task description and few sample input-output pairs and (optionally) resource and/or performance constraints, MMFactory can suggest a diverse pool of programmatic solutions by instantiating and combining visio-lingual tools from its model repository. In addition to synthesizing these solutions, MMFactory also proposes metrics and benchmarks performance / resource characteristics, allowing users to pick a solution that meets their unique design constraints. From the technical perspective, we also introduced a committee-based solution proposer that leverages multi-agent LLM conversation to generate executable, diverse, universal, and robust solutions for the user. Experimental results show that MMFactory outperforms existing methods by delivering state-of-the-art solutions tailored to user problem specifications. Project page is available at https://davidhalladay.github.io/mmfactory_demo.
Response Wide Shut: Surprising Observations in Basic Vision Language Model Capabilities
Aug 13, 2024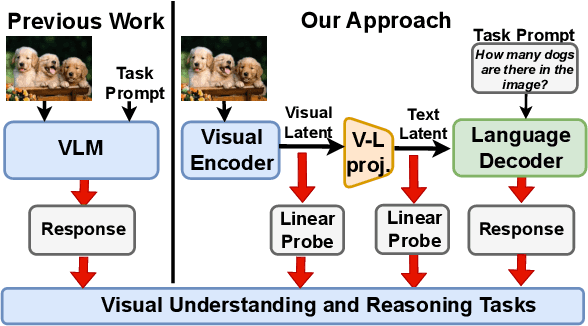



Vision-Language Models (VLMs) have emerged as general purpose tools for addressing a variety of complex computer vision problems. Such models have been shown to be highly capable, but, at the same time, also lacking some basic visual understanding skills. In this paper, we set out to understand the limitations of SoTA VLMs on fundamental visual tasks: object classification, understanding spatial arrangement, and ability to delineate individual object instances (through counting), by constructing a series of tests that probe which components of design, specifically, maybe lacking. Importantly, we go significantly beyond the current benchmarks, that simply measure final performance of VLM, by also comparing and contrasting it to performance of probes trained directly on features obtained from visual encoder (image embeddings), as well as intermediate vision-language projection used to bridge image-encoder and LLM-decoder ouput in many SoTA models (e.g., LLaVA, BLIP, InstructBLIP). In doing so, we uncover nascent shortcomings in VLMs response and make a number of important observations which could help train and develop more effective VLM models in future.
On Pre-training of Multimodal Language Models Customized for Chart Understanding
Jul 19, 2024

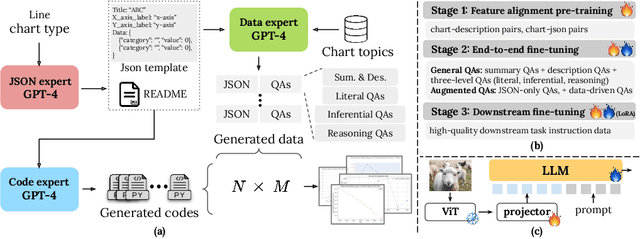

Recent studies customizing Multimodal Large Language Models (MLLMs) for domain-specific tasks have yielded promising results, especially in the field of scientific chart comprehension. These studies generally utilize visual instruction tuning with specialized datasets to enhance question and answer (QA) accuracy within the chart domain. However, they often neglect the fundamental discrepancy between natural image-caption pre-training data and digital chart image-QA data, particularly in the models' capacity to extract underlying numeric values from charts. This paper tackles this oversight by exploring the training processes necessary to improve MLLMs' comprehension of charts. We present three key findings: (1) Incorporating raw data values in alignment pre-training markedly improves comprehension of chart data. (2) Replacing images with their textual representation randomly during end-to-end fine-tuning transfer the language reasoning capability to chart interpretation skills. (3) Requiring the model to first extract the underlying chart data and then answer the question in the fine-tuning can further improve the accuracy. Consequently, we introduce CHOPINLLM, an MLLM tailored for in-depth chart comprehension. CHOPINLLM effectively interprets various types of charts, including unannotated ones, while maintaining robust reasoning abilities. Furthermore, we establish a new benchmark to evaluate MLLMs' understanding of different chart types across various comprehension levels. Experimental results show that CHOPINLLM exhibits strong performance in understanding both annotated and unannotated charts across a wide range of types.
M3T: Multi-Scale Memory Matching for Video Object Segmentation and Tracking
Dec 13, 2023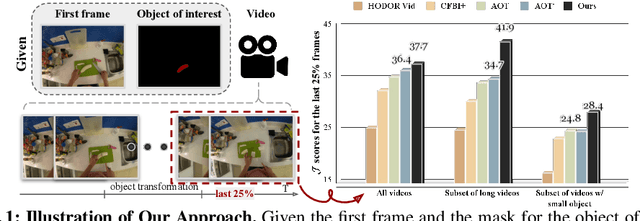

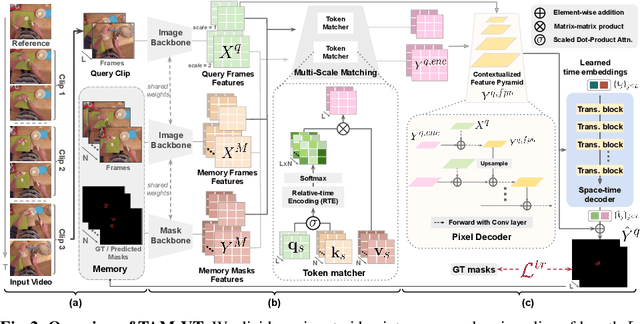
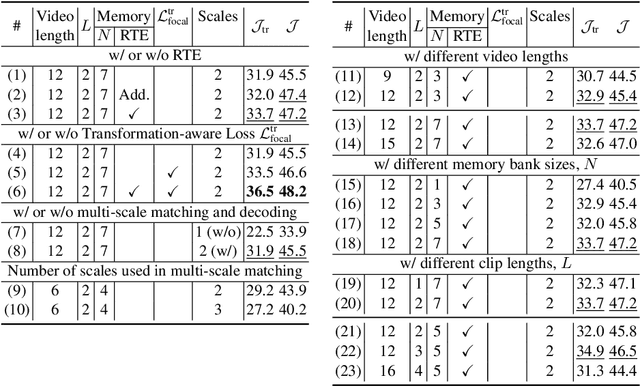
Video Object Segmentation (VOS) has became increasingly important with availability of larger datasets and more complex and realistic settings, which involve long videos with global motion (e.g, in egocentric settings), depicting small objects undergoing both rigid and non-rigid (including state) deformations. While a number of recent approaches have been explored for this task, these data characteristics still present challenges. In this work we propose a novel, DETR-style encoder-decoder architecture, which focuses on systematically analyzing and addressing aforementioned challenges. Specifically, our model enables on-line inference with long videos in a windowed fashion, by breaking the video into clips and propagating context among them using time-coded memory. We illustrate that short clip length and longer memory with learned time-coding are important design choices for achieving state-of-the-art (SoTA) performance. Further, we propose multi-scale matching and decoding to ensure sensitivity and accuracy for small objects. Finally, we propose a novel training strategy that focuses learning on portions of the video where an object undergoes significant deformations -- a form of "soft" hard-negative mining, implemented as loss-reweighting. Collectively, these technical contributions allow our model to achieve SoTA performance on two complex datasets -- VISOR and VOST. A series of detailed ablations validate our design choices as well as provide insights into the importance of parameter choices and their impact on performance.
Target-Free Text-guided Image Manipulation
Dec 01, 2022We tackle the problem of target-free text-guided image manipulation, which requires one to modify the input reference image based on the given text instruction, while no ground truth target image is observed during training. To address this challenging task, we propose a Cyclic-Manipulation GAN (cManiGAN) in this paper, which is able to realize where and how to edit the image regions of interest. Specifically, the image editor in cManiGAN learns to identify and complete the input image, while cross-modal interpreter and reasoner are deployed to verify the semantic correctness of the output image based on the input instruction. While the former utilizes factual/counterfactual description learning for authenticating the image semantics, the latter predicts the "undo" instruction and provides pixel-level supervision for the training of cManiGAN. With such operational cycle-consistency, our cManiGAN can be trained in the above weakly supervised setting. We conduct extensive experiments on the datasets of CLEVR and COCO, and the effectiveness and generalizability of our proposed method can be successfully verified. Project page: https://sites.google.com/view/wancyuanfan/projects/cmanigan.
Paraphrasing Is All You Need for Novel Object Captioning
Sep 25, 2022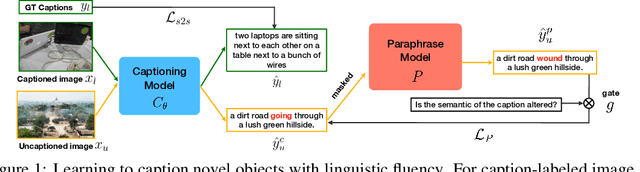
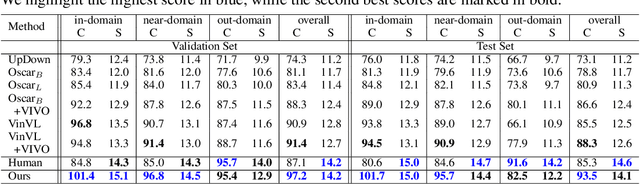
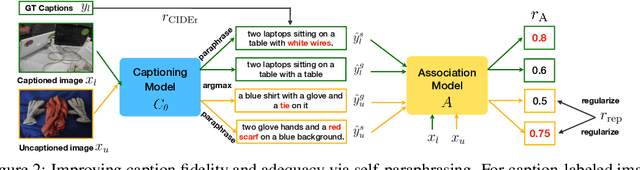
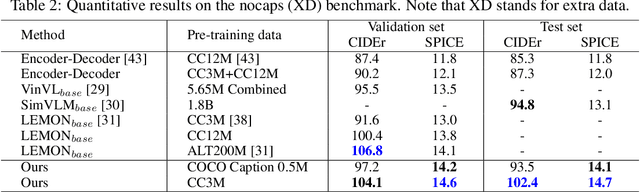
Novel object captioning (NOC) aims to describe images containing objects without observing their ground truth captions during training. Due to the absence of caption annotation, captioning models cannot be directly optimized via sequence-to-sequence training or CIDEr optimization. As a result, we present Paraphrasing-to-Captioning (P2C), a two-stage learning framework for NOC, which would heuristically optimize the output captions via paraphrasing. With P2C, the captioning model first learns paraphrasing from a language model pre-trained on text-only corpus, allowing expansion of the word bank for improving linguistic fluency. To further enforce the output caption sufficiently describing the visual content of the input image, we perform self-paraphrasing for the captioning model with fidelity and adequacy objectives introduced. Since no ground truth captions are available for novel object images during training, our P2C leverages cross-modality (image-text) association modules to ensure the above caption characteristics can be properly preserved. In the experiments, we not only show that our P2C achieves state-of-the-art performances on nocaps and COCO Caption datasets, we also verify the effectiveness and flexibility of our learning framework by replacing language and cross-modality association models for NOC. Implementation details and code are available in the supplementary materials.
Frido: Feature Pyramid Diffusion for Complex Scene Image Synthesis
Aug 29, 2022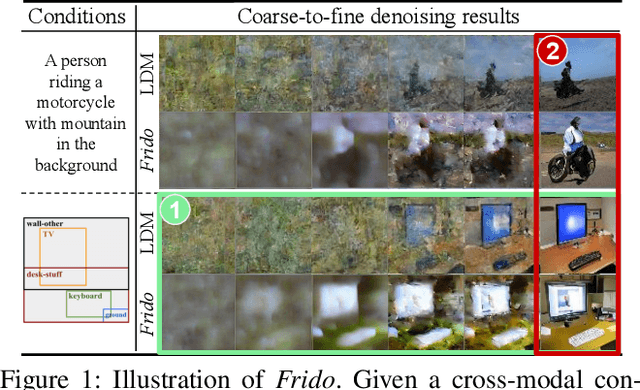
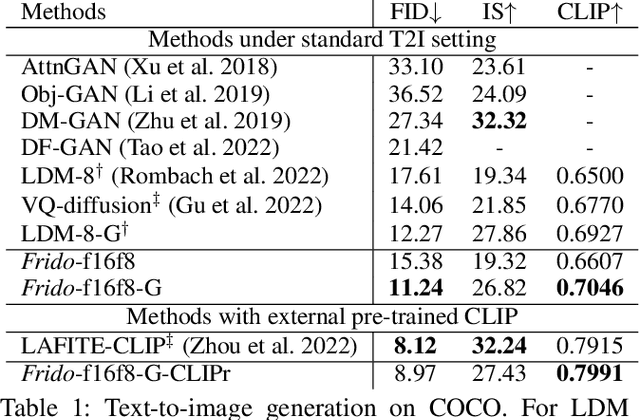
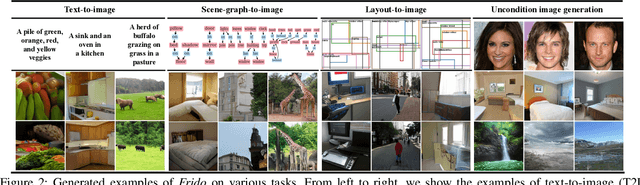
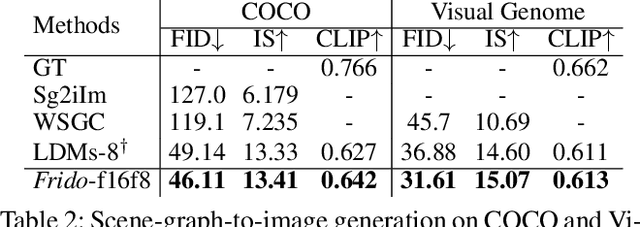
Diffusion models (DMs) have shown great potential for high-quality image synthesis. However, when it comes to producing images with complex scenes, how to properly describe both image global structures and object details remains a challenging task. In this paper, we present Frido, a Feature Pyramid Diffusion model performing a multi-scale coarse-to-fine denoising process for image synthesis. Our model decomposes an input image into scale-dependent vector quantized features, followed by a coarse-to-fine gating for producing image output. During the above multi-scale representation learning stage, additional input conditions like text, scene graph, or image layout can be further exploited. Thus, Frido can be also applied for conditional or cross-modality image synthesis. We conduct extensive experiments over various unconditioned and conditional image generation tasks, ranging from text-to-image synthesis, layout-to-image, scene-graph-to-image, to label-to-image. More specifically, we achieved state-of-the-art FID scores on five benchmarks, namely layout-to-image on COCO and OpenImages, scene-graph-to-image on COCO and Visual Genome, and label-to-image on COCO. Code is available at https://github.com/davidhalladay/Frido.
Scene Graph Expansion for Semantics-Guided Image Outpainting
May 05, 2022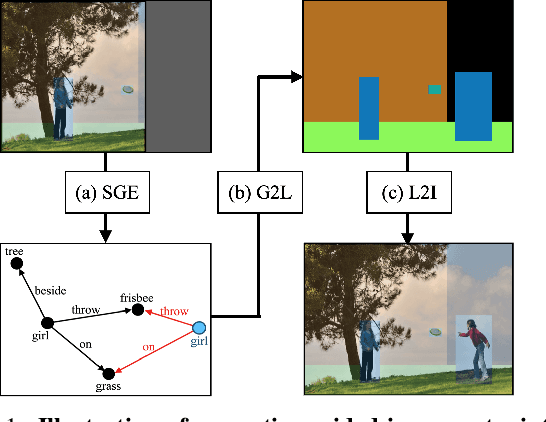
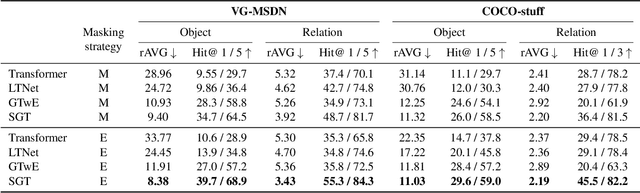
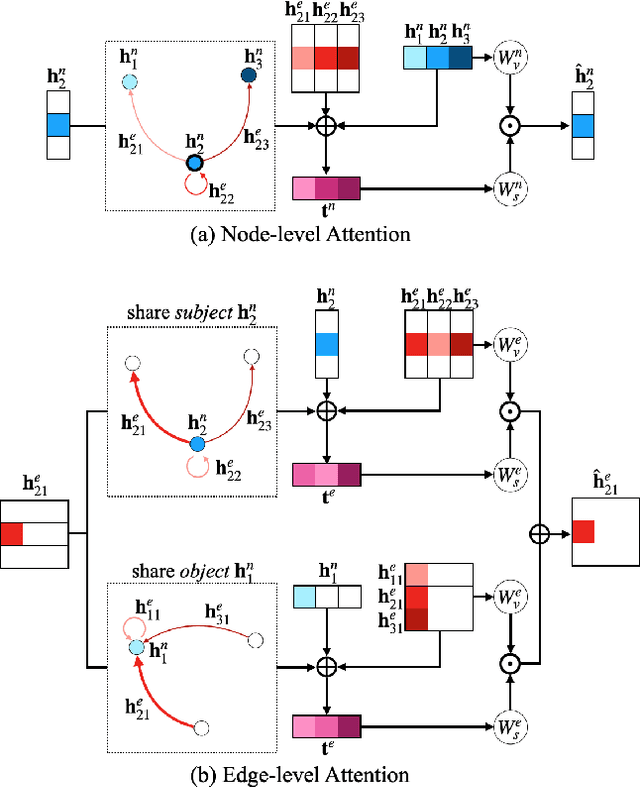

In this paper, we address the task of semantics-guided image outpainting, which is to complete an image by generating semantically practical content. Different from most existing image outpainting works, we approach the above task by understanding and completing image semantics at the scene graph level. In particular, we propose a novel network of Scene Graph Transformer (SGT), which is designed to take node and edge features as inputs for modeling the associated structural information. To better understand and process graph-based inputs, our SGT uniquely performs feature attention at both node and edge levels. While the former views edges as relationship regularization, the latter observes the co-occurrence of nodes for guiding the attention process. We demonstrate that, given a partial input image with its layout and scene graph, our SGT can be applied for scene graph expansion and its conversion to a complete layout. Following state-of-the-art layout-to-image conversions works, the task of image outpainting can be completed with sufficient and practical semantics introduced. Extensive experiments are conducted on the datasets of MS-COCO and Visual Genome, which quantitatively and qualitatively confirm the effectiveness of our proposed SGT and outpainting frameworks.