 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D-RGPT: Toward Region-level 4D Understanding via Perceptual Distillation
Dec 22, 2025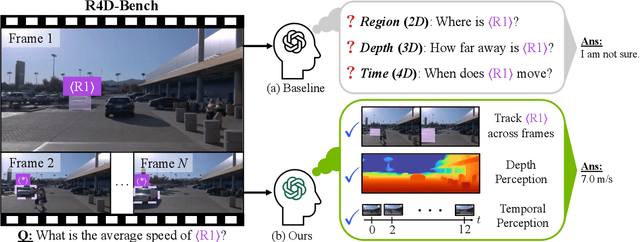

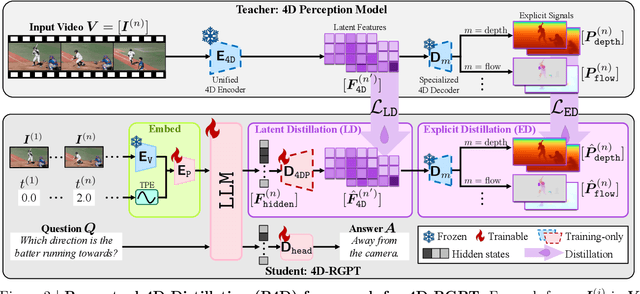
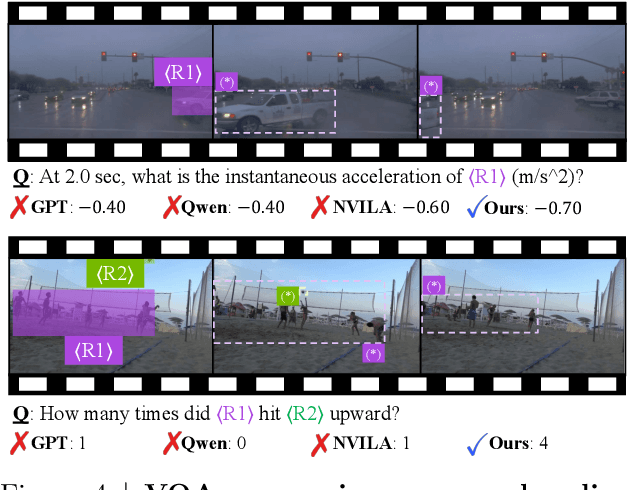
Despite advances in Multimodal LLMs (MLLMs), their ability to reason over 3D structures and temporal dynamics remains limited, constrained by weak 4D perception and temporal understanding. Existing 3D and 4D Video Question Answering (VQA) benchmarks also emphasize static scenes and lack region-level prompting. We tackle these issues by introducing: (a) 4D-RGPT, a specialized MLLM designed to capture 4D representations from video inputs with enhanced temporal perception; (b) Perceptual 4D Distillation (P4D), a training framework that transfers 4D representations from a frozen expert model into 4D-RGPT for comprehensive 4D perception; and (c) R4D-Bench, a benchmark for depth-aware dynamic scenes with region-level prompting, built via a hybrid automated and human-verified pipeline. Our 4D-RGPT achieves notable improvements on both existing 4D VQA benchmarks and the proposed R4D-Bench benchmark.
Heatmap Regression without Soft-Argmax for Facial Landmark Detection
Aug 19, 2025



Facial landmark detection is an important task in computer vision with numerous applications, such as head pose estimation, expression analysis, face swapping, etc. Heatmap regression-based methods have been widely used to achieve state-of-the-art results in this task. These methods involve computing the argmax over the heatmaps to predict a landmark. Since argmax is not differentiable, these methods use a differentiable approximation, Soft-argmax, to enable end-to-end training on deep-nets. In this work, we revisit this long-standing choice of using Soft-argmax and demonstrate that it is not the only way to achieve strong performance. Instead, we propose an alternative training objective based on the classic structured prediction framework. Empirically, our method achieves state-of-the-art performance on three facial landmark benchmarks (WFLW, COFW, and 300W), converging 2.2x faster during training while maintaining better/competitive accuracy. Our code is available here: https://github.com/ca-joe-yang/regression-without-softarg.
Local Scale Equivariance with Latent Deep Equilibrium Canonicalizer
Aug 19, 2025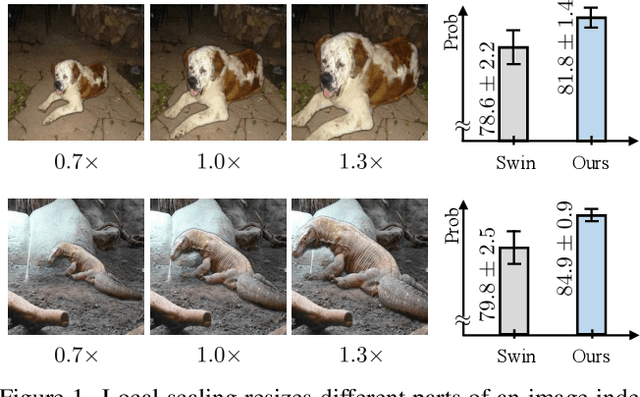
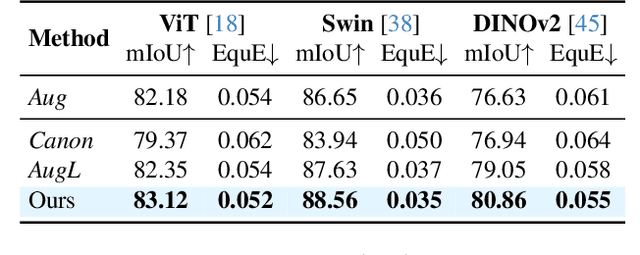
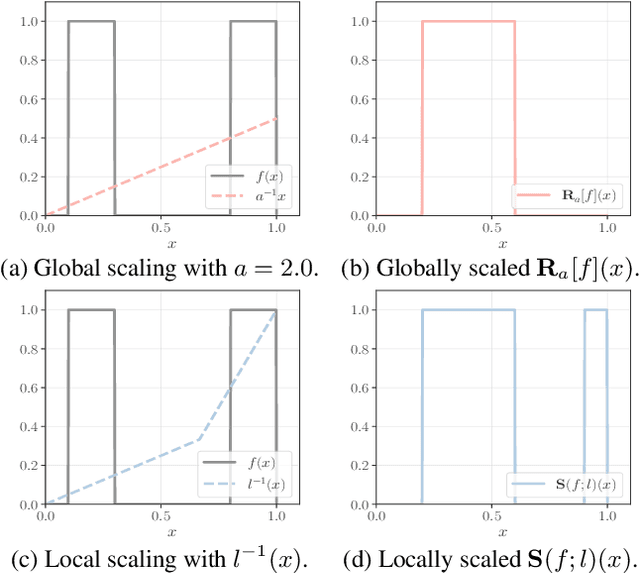

Scale variation is a fundamental challenge in computer vision. Objects of the same class can have different sizes, and their perceived size is further affected by the distance from the camera. These variations are local to the objects, i.e., different object sizes may change differently within the same image. To effectively handle scale variations, we present a deep equilibrium canonicalizer (DEC) to improve the local scale equivariance of a model. DEC can be easily incorporated into existing network architectures and can be adapted to a pre-trained model. Notably, we show that on the competitive ImageNet benchmark, DEC improves both model performance and local scale consistency across four popular pre-trained deep-nets, e.g., ViT, DeiT, Swin, and BEiT. Our code is available at https://github.com/ashiq24/local-scale-equivariance.
Toward Long-Tailed Online Anomaly Detection through Class-Agnostic Concepts
Jul 22, 2025Anomaly detection (AD) identifies the defect regions of a given image. Recent works have studied AD, focusing on learning AD without abnormal images, with long-tailed distributed training data, and using a unified model for all classes. In addition, online AD learning has also been explored. In this work, we expand in both directions to a realistic setting by considering the novel task of long-tailed online AD (LTOAD). We first identified that the offline state-of-the-art LTAD methods cannot be directly applied to the online setting. Specifically, LTAD is class-aware, requiring class labels that are not available in the online setting. To address this challenge, we propose a class-agnostic framework for LTAD and then adapt it to our online learning setting. Our method outperforms the SOTA baselines in most offline LTAD settings, including both the industrial manufacturing and the medical domain. In particular, we observe +4.63% image-AUROC on MVTec even compared to methods that have access to class labels and the number of classes. In the most challenging long-tailed online setting, we achieve +0.53% image-AUROC compared to baselines. Our LTOAD benchmark is released here: https://doi.org/10.5281/zenodo.16283852 .
Multi-Object 3D Grounding with Dynamic Modules and Language-Informed Spatial Attention
Oct 29, 2024



Multi-object 3D Grounding involves locating 3D boxes based on a given query phrase from a point cloud. It is a challenging and significant task with numerous applications in visual understanding, human-computer interaction, and robotics. To tackle this challenge, we introduce D-LISA, a two-stage approach incorporating three innovations. First, a dynamic vision module that enables a variable and learnable number of box proposals. Second, a dynamic camera positioning that extracts features for each proposal. Third, a language-informed spatial attention module that better reasons over the proposals to output the final prediction. Empirically, experiments show that our method outperforms the state-of-the-art methods on multi-object 3D grounding by 12.8% (absolute) and is competitive in single-object 3D grounding.
Deep Nets with Subsampling Layers Unwittingly Discard Useful Activations at Test-Time
Oct 01, 2024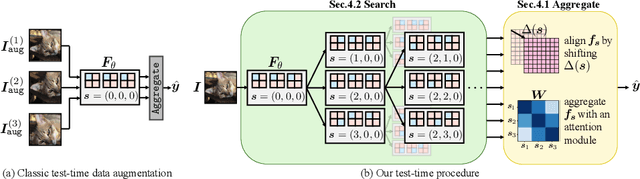
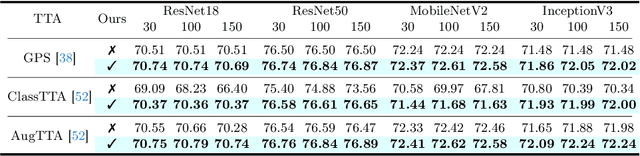
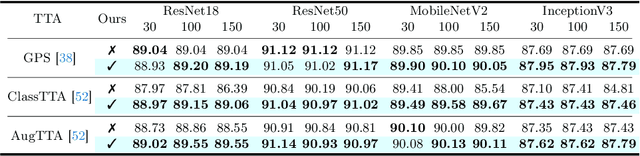
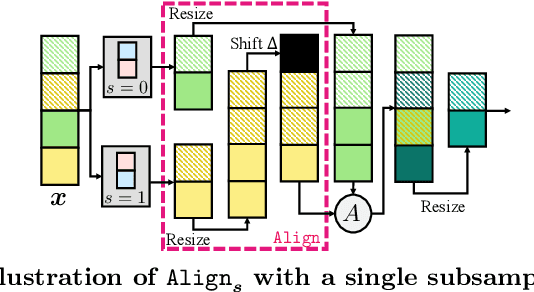
Subsampling layers play a crucial role in deep nets by discarding a portion of an activation map to reduce its spatial dimensions. This encourages the deep net to learn higher-level representations. Contrary to this motivation, we hypothesize that the discarded activations are useful and can be incorporated on the fly to improve models' prediction. To validate our hypothesis, we propose a search and aggregate method to find useful activation maps to be used at test time. We applied our approach to the task of image classification and semantic segmentation. Extensive experiments over nine different architectures on multiple datasets show that our method consistently improves model test-time performance, complementing existing test-time augmentation techniques. Our code is available at https://github.com/ca-joe-yang/discard-in-subsampling.
Learning to Obstruct Few-Shot Image Classification over Restricted Classes
Sep 28, 2024Advancements in open-source pre-trained backbones make it relatively easy to fine-tune a model for new tasks. However, this lowered entry barrier poses potential risks, e.g., bad actors developing models for harmful applications. A question arises: Is possible to develop a pre-trained model that is difficult to fine-tune for certain downstream tasks? To begin studying this, we focus on few-shot classification (FSC). Specifically, we investigate methods to make FSC more challenging for a set of restricted classes while maintaining the performance of other classes. We propose to meta-learn over the pre-trained backbone in a manner that renders it a ''poor initialization''. Our proposed Learning to Obstruct (LTO) algorithm successfully obstructs four FSC methods across three datasets, including ImageNet and CIFAR100 for image classification, as well as CelebA for attribute classification.
Target-Free Text-guided Image Manipulation
Dec 01, 2022We tackle the problem of target-free text-guided image manipulation, which requires one to modify the input reference image based on the given text instruction, while no ground truth target image is observed during training. To address this challenging task, we propose a Cyclic-Manipulation GAN (cManiGAN) in this paper, which is able to realize where and how to edit the image regions of interest. Specifically, the image editor in cManiGAN learns to identify and complete the input image, while cross-modal interpreter and reasoner are deployed to verify the semantic correctness of the output image based on the input instruction. While the former utilizes factual/counterfactual description learning for authenticating the image semantics, the latter predicts the "undo" instruction and provides pixel-level supervision for the training of cManiGAN. With such operational cycle-consistency, our cManiGAN can be trained in the above weakly supervised setting. We conduct extensive experiments on the datasets of CLEVR and COCO, and the effectiveness and generalizability of our proposed method can be successfully verified. Project page: https://sites.google.com/view/wancyuanfan/projects/cmanigan.
Scene Graph Expansion for Semantics-Guided Image Outpainting
May 05, 2022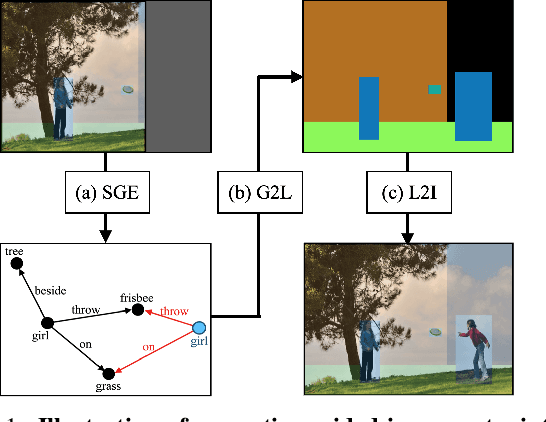
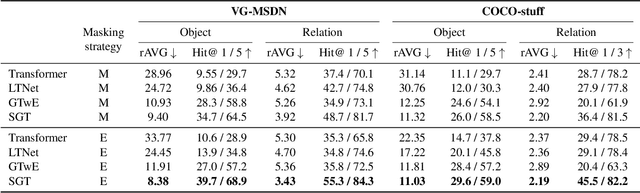
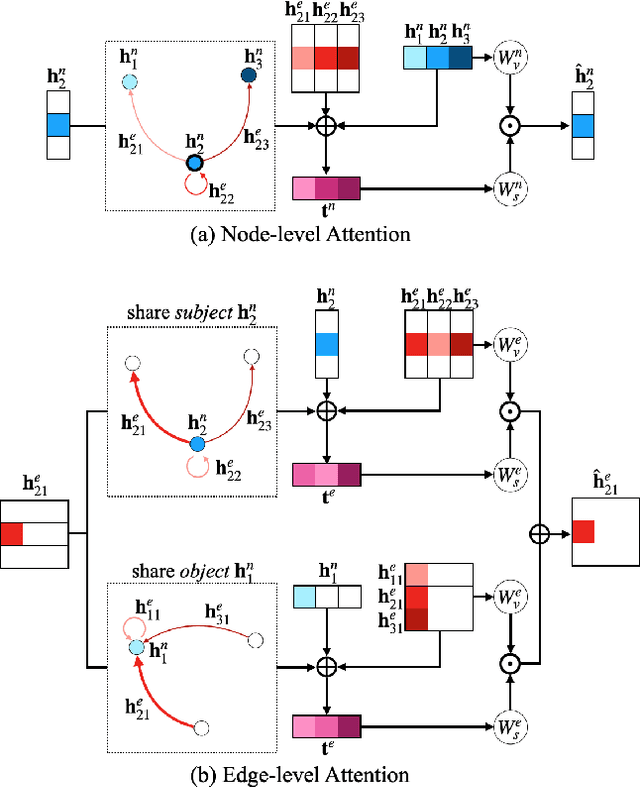

In this paper, we address the task of semantics-guided image outpainting, which is to complete an image by generating semantically practical content. Different from most existing image outpainting works, we approach the above task by understanding and completing image semantics at the scene graph level. In particular, we propose a novel network of Scene Graph Transformer (SGT), which is designed to take node and edge features as inputs for modeling the associated structural information. To better understand and process graph-based inputs, our SGT uniquely performs feature attention at both node and edge levels. While the former views edges as relationship regularization, the latter observes the co-occurrence of nodes for guiding the attention process. We demonstrate that, given a partial input image with its layout and scene graph, our SGT can be applied for scene graph expansion and its conversion to a complete layout. Following state-of-the-art layout-to-image conversions works, the task of image outpainting can be completed with sufficient and practical semantics introduced. Extensive experiments are conducted on the datasets of MS-COCO and Visual Genome, which quantitatively and qualitatively confirm the effectiveness of our proposed SGT and outpainting frameworks.