 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Personalization for Diffusion Models
Oct 02, 2025



Updating diffusion models in an incremental setting would be practical in real-world applications yet computationally challenging. We present a novel learning strategy of Concept Neuron Selection (CNS), a simple yet effective approach to perform personalization in a continual learning scheme. CNS uniquely identifies neurons in diffusion models that are closely related to the target concepts. In order to mitigate catastrophic forgetting problems while preserving zero-shot text-to-image generation ability, CNS finetunes concept neurons in an incremental manner and jointly preserves knowledge learned of previous concepts. Evaluation of real-world datasets demonstrates that CNS achieves state-of-the-art performance with minimal parameter adjustments, outperforming previous methods in both single and multi-concept personalization works. CNS also achieves fusion-free operation, reducing memory storage and processing time for continual personalization.
Towards Light Weight Object Detection System
Oct 08, 2022
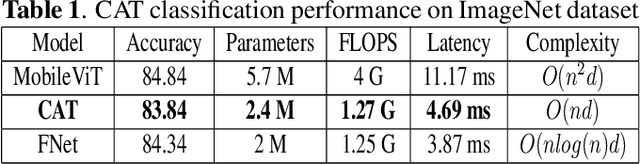

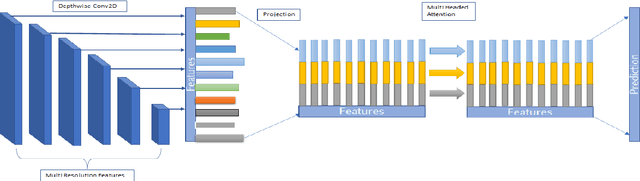
Transformers are a popular choice for classification tasks and as backbones for object detection tasks. However, their high latency brings challenges in their adaptation to lightweight object detection systems. We present an approximation of the self-attention layers used in the transformer architecture. This approximation reduces the latency of the classification system while incurring minimal loss in accuracy. We also present a method that uses a transformer encoder layer for multi-resolution feature fusion. This feature fusion improves the accuracy of the state-of-the-art lightweight object detection system without significantly increasing the number of parameters. Finally, we provide an abstraction for the transformer architecture called Generalized Transformer (gFormer) that can guide the design of novel transformer-like architectures.
Direct Handheld Burst Imaging to Simulated Defocus
Jul 13, 2022

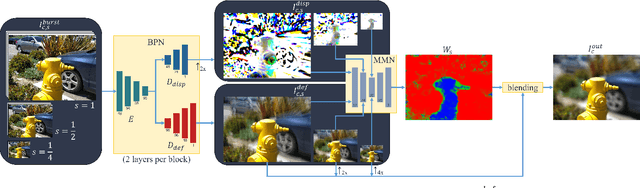

A shallow depth-of-field image keeps the subject in focus, and the foreground and background contexts blurred. This effect requires much larger lens apertures than those of smartphone cameras. Conventional methods acquire RGB-D images and blur image regions based on their depth. However, this approach is not suitable for reflective or transparent surfaces, or finely detailed object silhouettes, where the depth value is inaccurate or ambiguous. We present a learning-based method to synthesize the defocus blur in shallow depth-of-field images from handheld bursts acquired with a single small aperture lens. Our deep learning model directly produces the shallow depth-of-field image, avoiding explicit depth-based blurring. The simulated aperture diameter equals the camera translation during burst acquisition. Our method does not suffer from artifacts due to inaccurate or ambiguous depth estimation, and it is well-suited to portrait photography.
Scene Graph Expansion for Semantics-Guided Image Outpainting
May 05, 2022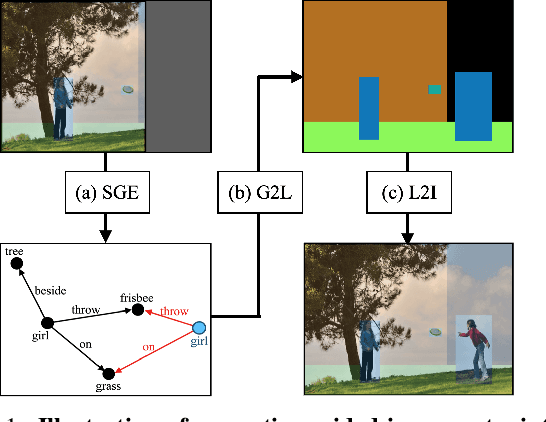
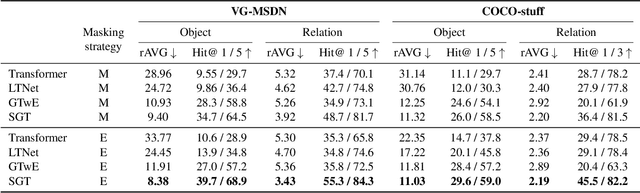
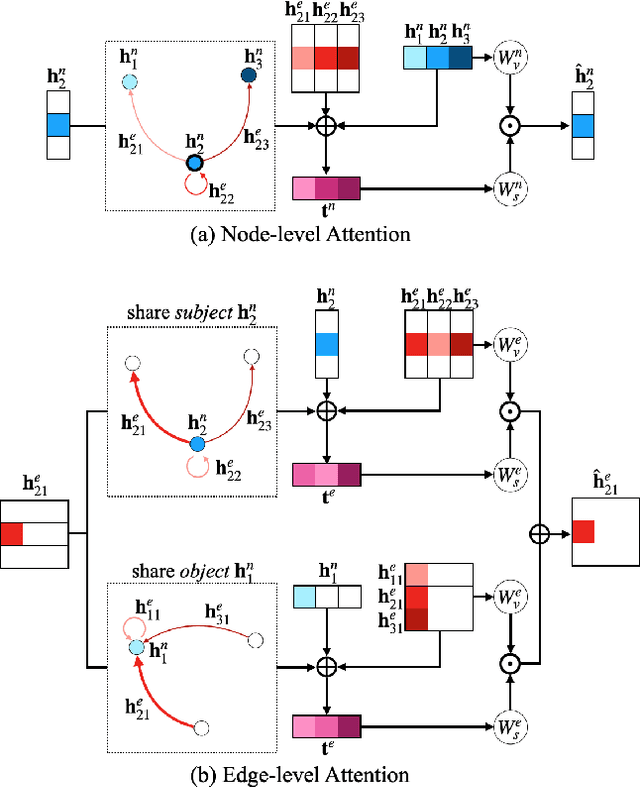

In this paper, we address the task of semantics-guided image outpainting, which is to complete an image by generating semantically practical content. Different from most existing image outpainting works, we approach the above task by understanding and completing image semantics at the scene graph level. In particular, we propose a novel network of Scene Graph Transformer (SGT), which is designed to take node and edge features as inputs for modeling the associated structural information. To better understand and process graph-based inputs, our SGT uniquely performs feature attention at both node and edge levels. While the former views edges as relationship regularization, the latter observes the co-occurrence of nodes for guiding the attention process. We demonstrate that, given a partial input image with its layout and scene graph, our SGT can be applied for scene graph expansion and its conversion to a complete layout. Following state-of-the-art layout-to-image conversions works, the task of image outpainting can be completed with sufficient and practical semantics introduced. Extensive experiments are conducted on the datasets of MS-COCO and Visual Genome, which quantitatively and qualitatively confirm the effectiveness of our proposed SGT and outpainting frameworks.