 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Light Weight Object Detection System
Oct 08, 2022
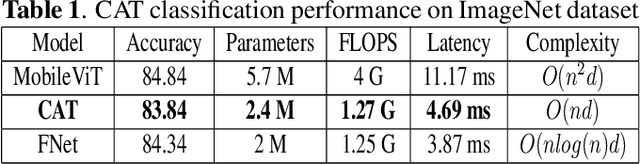

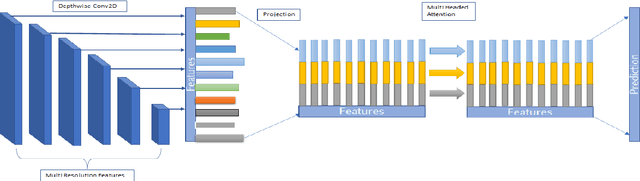
Transformers are a popular choice for classification tasks and as backbones for object detection tasks. However, their high latency brings challenges in their adaptation to lightweight object detection systems. We present an approximation of the self-attention layers used in the transformer architecture. This approximation reduces the latency of the classification system while incurring minimal loss in accuracy. We also present a method that uses a transformer encoder layer for multi-resolution feature fusion. This feature fusion improves the accuracy of the state-of-the-art lightweight object detection system without significantly increasing the number of parameters. Finally, we provide an abstraction for the transformer architecture called Generalized Transformer (gFormer) that can guide the design of novel transformer-like architectures.
Direct Handheld Burst Imaging to Simulated Defocus
Jul 13, 2022

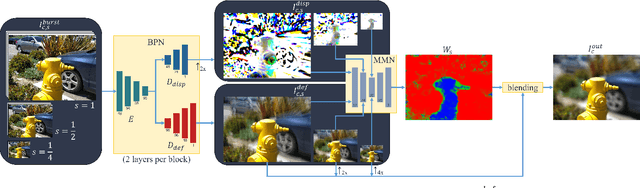

A shallow depth-of-field image keeps the subject in focus, and the foreground and background contexts blurred. This effect requires much larger lens apertures than those of smartphone cameras. Conventional methods acquire RGB-D images and blur image regions based on their depth. However, this approach is not suitable for reflective or transparent surfaces, or finely detailed object silhouettes, where the depth value is inaccurate or ambiguous. We present a learning-based method to synthesize the defocus blur in shallow depth-of-field images from handheld bursts acquired with a single small aperture lens. Our deep learning model directly produces the shallow depth-of-field image, avoiding explicit depth-based blurring. The simulated aperture diameter equals the camera translation during burst acquisition. Our method does not suffer from artifacts due to inaccurate or ambiguous depth estimation, and it is well-suited to portrait photography.