 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DTextureTransformer: Geometry Aware Texture Generation for Arbitrary Mesh Topology
Mar 07, 2024



Learning to generate textures for a novel 3D mesh given a collection of 3D meshes and real-world 2D images is an important problem with applications in various domains such as 3D simulation, augmented and virtual reality, gaming, architecture, and design. Existing solutions either do not produce high-quality textures or deform the original high-resolution input mesh topology into a regular grid to make this generation easier but also lose the original mesh topology. In this paper, we present a novel framework called the 3DTextureTransformer that enables us to generate high-quality textures without deforming the original, high-resolution input mesh. Our solution, a hybrid of geometric deep learning and StyleGAN-like architecture, is flexible enough to work on arbitrary mesh topologies and also easily extensible to texture generation for point cloud representations. Our solution employs a message-passing framework in 3D in conjunction with a StyleGAN-like architecture for 3D texture generation. The architecture achieves state-of-the-art performance among a class of solutions that can learn from a collection of 3D geometry and real-world 2D images while working with any arbitrary mesh topology.
Neural Machine Translation for Code Generation
May 22, 2023

Neural machine translation (NMT) methods developed for natural language processing have been shown to be highly successful in automating translation from one natural language to another. Recently, these NMT methods have been adapted to the generation of program code. In NMT for code generation, the task is to generate output source code that satisfies constraints expressed in the input. In the literature, a variety of different input scenarios have been explored, including generating code based on natural language description, lower-level representations such as binary or assembly (neural decompilation), partial representations of source code (code completion and repair), and source code in another language (code translation). In this paper we survey the NMT for code generation literature, cataloging the variety of methods that have been explored according to input and output representations, model architectures, optimization techniques used, data sets, and evaluation methods. We discuss the limitations of existing methods and future research directions
Towards Light Weight Object Detection System
Oct 08, 2022
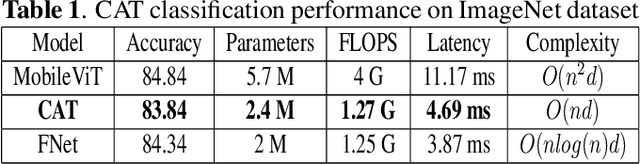

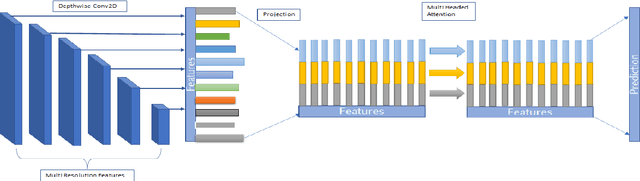
Transformers are a popular choice for classification tasks and as backbones for object detection tasks. However, their high latency brings challenges in their adaptation to lightweight object detection systems. We present an approximation of the self-attention layers used in the transformer architecture. This approximation reduces the latency of the classification system while incurring minimal loss in accuracy. We also present a method that uses a transformer encoder layer for multi-resolution feature fusion. This feature fusion improves the accuracy of the state-of-the-art lightweight object detection system without significantly increasing the number of parameters. Finally, we provide an abstraction for the transformer architecture called Generalized Transformer (gFormer) that can guide the design of novel transformer-like architectures.
Texture Generation Using Graph Generative Adversarial Network And Differentiable Rendering
Jun 17, 2022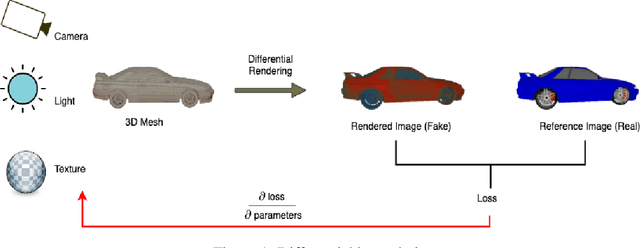
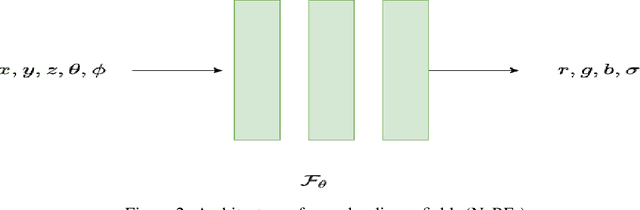
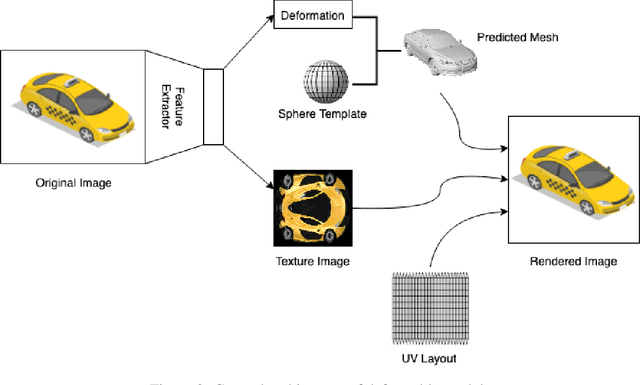
Novel texture synthesis for existing 3D mesh models is an important step towards photo realistic asset generation for existing simulators. But existing methods inherently work in the 2D image space which is the projection of the 3D space from a given camera perspective. These methods take camera angle, 3D model information, lighting information and generate photorealistic 2D image. To generate a photorealistic image from another perspective or lighting, we need to make a computationally expensive forward pass each time we change the parameters. Also, it is hard to generate such images for a simulator that can satisfy the temporal constraints the sequences of images should be similar but only need to change the viewpoint of lighting as desired. The solution can not be directly integrated with existing tools like Blender and Unreal Engine. Manual solution is expensive and time consuming. We thus present a new system called a graph generative adversarial network (GGAN) that can generate textures which can be directly integrated into a given 3D mesh models with tools like Blender and Unreal Engine and can be simulated from any perspective and lighting condition easily.
SIM-ECG: A Signal Importance Mask-driven ECGClassification System
Oct 28, 2021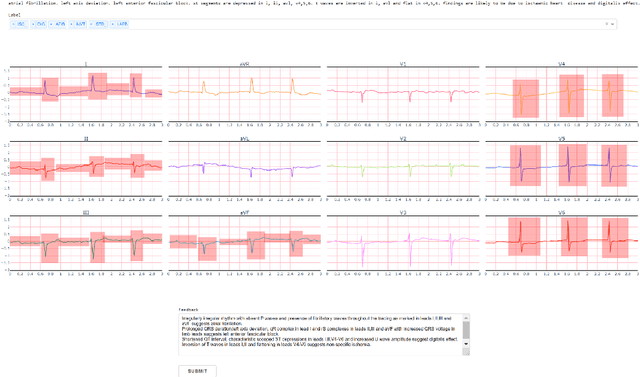
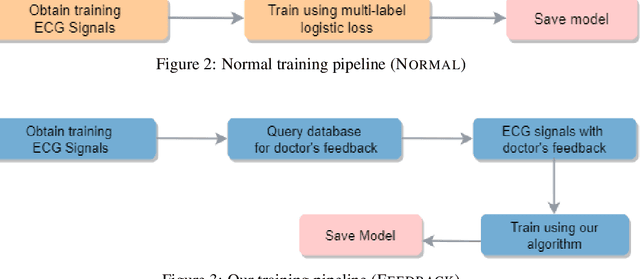
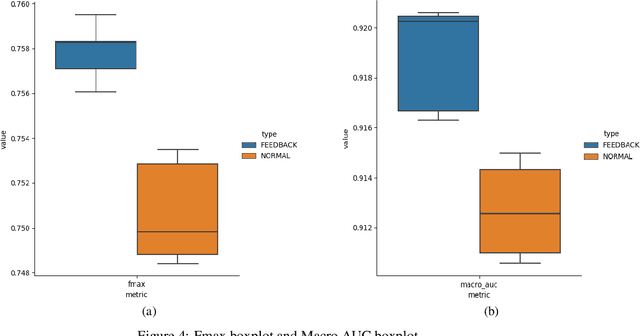
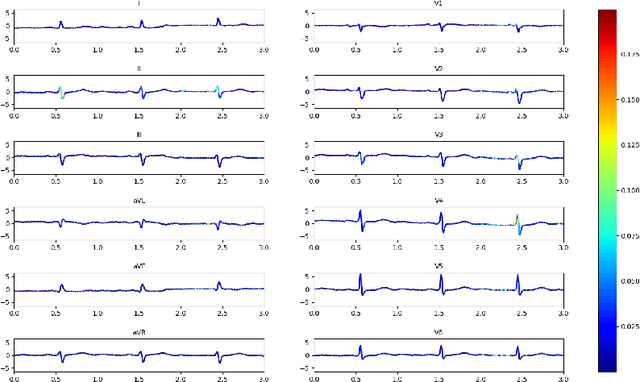
Heart disease is the number one killer, and ECGs can assist in the early diagnosis and prevention of deadly outcomes. Accurate ECG interpretation is critical in detecting heart diseases; however, they are often misinterpreted due to a lack of training or insufficient time spent to detect minute anomalies. Subsequently, researchers turned to machine learning to assist in the analysis. However, existing systems are not as accurate as skilled ECG readers, and black-box approaches to providing diagnosis result in a lack of trust by medical personnel in a given diagnosis. To address these issues, we propose a signal importance mask feedback-based machine learning system that continuously accepts feedback, improves accuracy, and ex-plains the resulting diagnosis. This allows medical personnel to quickly glance at the output and either accept the results, validate the explanation and diagnosis, or quickly correct areas of misinterpretation, giving feedback to the system for improvement. We have tested our system on a publicly available dataset consisting of healthy and disease-indicating samples. We empirically show that our algorithm is better in terms of standard performance measures such as F-score and MacroAUC compared to normal training baseline (without feedback); we also show that our model generates better interpretability maps.
Improving the trustworthiness of image classification models by utilizing bounding-box annotations
Aug 15, 2021
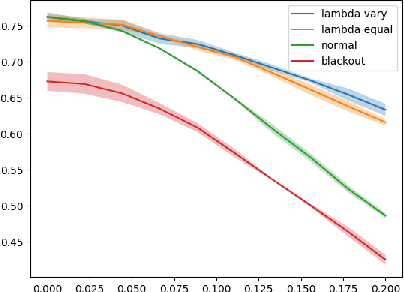

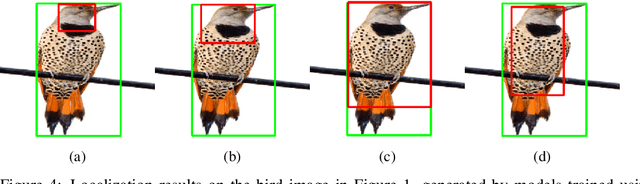
We study utilizing auxiliary information in training data to improve the trustworthiness of machine learning models. Specifically, in the context of image classification, we propose to optimize a training objective that incorporates bounding box information, which is available in many image classification datasets. Preliminary experimental results show that the proposed algorithm achieves better performance in accuracy, robustness, and interpretability compared with baselines.
* 6 pages including references