 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Occlusion Effect on Multi-View Camera Perception in BEV with Multi-Sensor Fusion
Jan 10, 2025Autonomous driving technology is rapidly evolving, offering the potential for safer and more efficient transportation. However, the performance of these systems can be significantly compromised by the occlusion on sensors due to environmental factors like dirt, dust, rain, and fog. These occlusions severely affect vision-based tasks such as object detection, vehicle segmentation, and lane recognition. In this paper, we investigate the impact of various kinds of occlusions on camera sensor by projecting their effects from multi-view camera images of the nuScenes dataset into the Bird's-Eye View (BEV) domain. This approach allows us to analyze how occlusions spatially distribute and influence vehicle segmentation accuracy within the BEV domain. Despite significant advances in sensor technology and multi-sensor fusion, a gap remains in the existing literature regarding the specific effects of camera occlusions on BEV-based perception systems. To address this gap, we use a multi-sensor fusion technique that integrates LiDAR and radar sensor data to mitigate the performance degradation caused by occluded cameras. Our findings demonstrate that this approach significantly enhances the accuracy and robustness of vehicle segmentation tasks, leading to more reliable autonomous driving systems.
Velocity Driven Vision: Asynchronous Sensor Fusion Birds Eye View Models for Autonomous Vehicles
Jul 24, 2024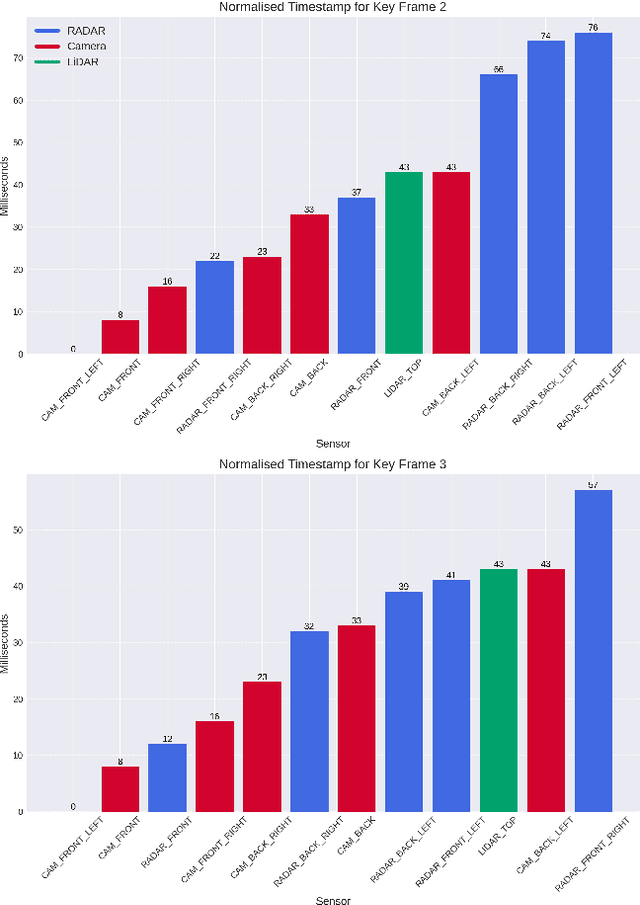
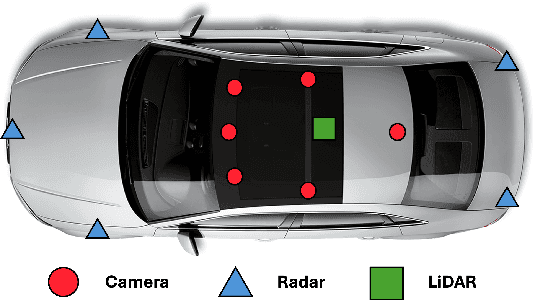
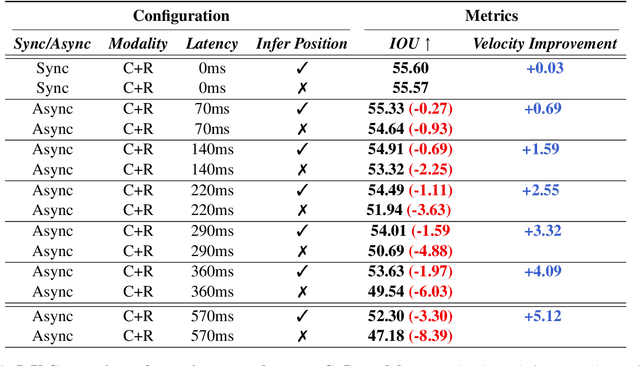
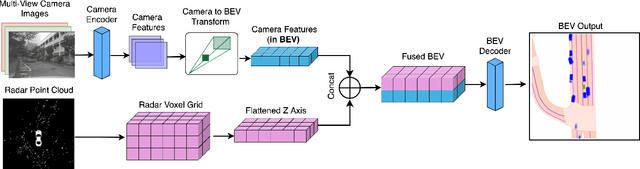
Fusing different sensor modalities can be a difficult task, particularly if they are asynchronous. Asynchronisation may arise due to long processing times or improper synchronisation during calibration, and there must exist a way to still utilise this previous information for the purpose of safe driving, and object detection in ego vehicle/ multi-agent trajectory prediction. Difficulties arise in the fact that the sensor modalities have captured information at different times and also at different positions in space. Therefore, they are not spatially nor temporally aligned. This paper will investigate the challenge of radar and LiDAR sensors being asynchronous relative to the camera sensors, for various time latencies. The spatial alignment will be resolved before lifting into BEV space via the transformation of the radar/LiDAR point clouds into the new ego frame coordinate system. Only after this can we concatenate the radar/LiDAR point cloud and lifted camera features. Temporal alignment will be remedied for radar data only, we will implement a novel method of inferring the future radar point positions using the velocity information. Our approach to resolving the issue of sensor asynchrony yields promising results. We demonstrate velocity information can drastically improve IoU for asynchronous datasets, as for a time latency of 360 milliseconds (ms), IoU improves from 49.54 to 53.63. Additionally, for a time latency of 550ms, the camera+radar (C+R) model outperforms the camera+LiDAR (C+L) model by 0.18 IoU. This is an advancement in utilising the often-neglected radar sensor modality, which is less favoured than LiDAR for autonomous driving purposes.
MapsTP: HD Map Images Based Multimodal Trajectory Prediction for Automated Vehicles
Jul 08, 2024



Predicting ego vehicle trajectories remains a critical challenge, especially in urban and dense areas due to the unpredictable behaviours of other vehicles and pedestrians. Multimodal trajectory prediction enhances decision-making by considering multiple possible future trajectories based on diverse sources of environmental data. In this approach, we leverage ResNet-50 to extract image features from high-definition map data and use IMU sensor data to calculate speed, acceleration, and yaw rate. A temporal probabilistic network is employed to compute potential trajectories, selecting the most accurate and highly probable trajectory paths. This method integrates HD map data to improve the robustness and reliability of trajectory predictions for autonomous vehicles.
Surround-View Fisheye Optics in Computer Vision and Simulation: Survey and Challenges
Feb 21, 2024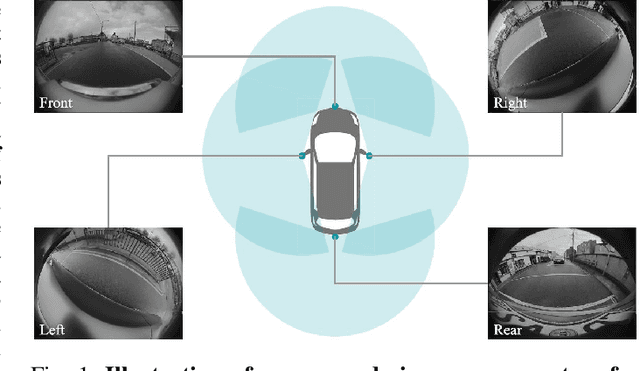

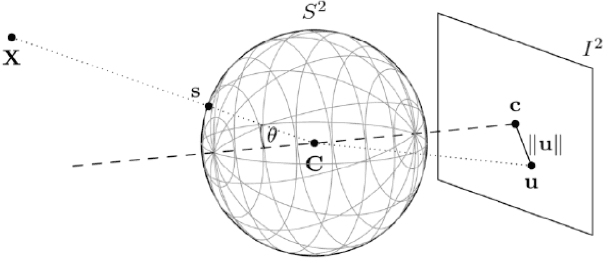

In this paper, we provide a survey on automotive surround-view fisheye optics, with an emphasis on the impact of optical artifacts on computer vision tasks in autonomous driving and ADAS. The automotive industry has advanced in applying state-of-the-art computer vision to enhance road safety and provide automated driving functionality. When using camera systems on vehicles, there is a particular need for a wide field of view to capture the entire vehicle's surroundings, in areas such as low-speed maneuvering, automated parking, and cocoon sensing. However, one crucial challenge in surround-view cameras is the strong optical aberrations of the fisheye camera, which is an area that has received little attention in the literature. Additionally, a comprehensive dataset is needed for testing safety-critical scenarios in vehicle automation. The industry has turned to simulation as a cost-effective strategy for creating synthetic datasets with surround-view camera imagery. We examine different simulation methods (such as model-driven and data-driven simulations) and discuss the simulators' ability (or lack thereof) to model real-world optical performance. Overall, this paper highlights the optical aberrations in automotive fisheye datasets, and the limitations of optical reality in simulated fisheye datasets, with a focus on computer vision in surround-view optical systems.
Optimizing Ego Vehicle Trajectory Prediction: The Graph Enhancement Approach
Jan 10, 2024Predicting the trajectory of an ego vehicle is a critical component of autonomous driving systems. Current state-of-the-art methods typically rely on Deep Neural Networks (DNNs) and sequential models to process front-view images for future trajectory prediction. However, these approaches often struggle with perspective issues affecting object features in the scene. To address this, we advocate for the use of Bird's Eye View (BEV) perspectives, which offer unique advantages in capturing spatial relationships and object homogeneity. In our work, we leverage Graph Neural Networks (GNNs) and positional encoding to represent objects in a BEV, achieving competitive performance compared to traditional DNN-based methods. While the BEV-based approach loses some detailed information inherent to front-view images, we balance this by enriching the BEV data by representing it as a graph where relationships between the objects in a scene are captured effectively.
BEVSeg2TP: Surround View Camera Bird's-Eye-View Based Joint Vehicle Segmentation and Ego Vehicle Trajectory Prediction
Dec 20, 2023



Trajectory prediction is, naturally, a key task for vehicle autonomy. While the number of traffic rules is limited, the combinations and uncertainties associated with each agent's behaviour in real-world scenarios are nearly impossible to encode. Consequently, there is a growing interest in learning-based trajectory prediction. The proposed method in this paper predicts trajectories by considering perception and trajectory prediction as a unified system. In considering them as unified tasks, we show that there is the potential to improve the performance of perception. To achieve these goals, we present BEVSeg2TP - a surround-view camera bird's-eye-view-based joint vehicle segmentation and ego vehicle trajectory prediction system for autonomous vehicles. The proposed system uses a network trained on multiple camera views. The images are transformed using several deep learning techniques to perform semantic segmentation of objects, including other vehicles, in the scene. The segmentation outputs are fused across the camera views to obtain a comprehensive representation of the surrounding vehicles from the bird's-eye-view perspective. The system further predicts the future trajectory of the ego vehicle using a spatiotemporal probabilistic network (STPN) to optimize trajectory prediction. This network leverages information from encoder-decoder transformers and joint vehicle segmentation.
Navigating Uncertainty: The Role of Short-Term Trajectory Prediction in Autonomous Vehicle Safety
Jul 12, 2023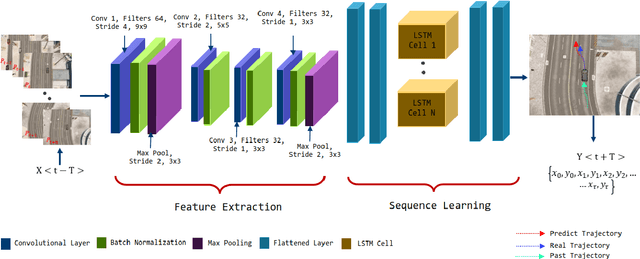
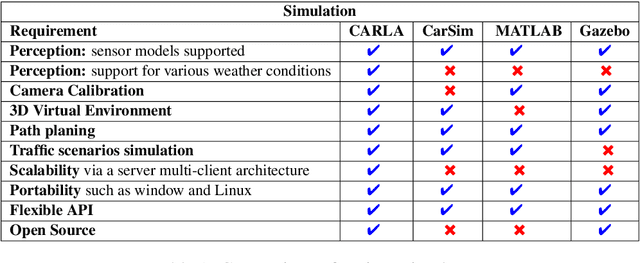
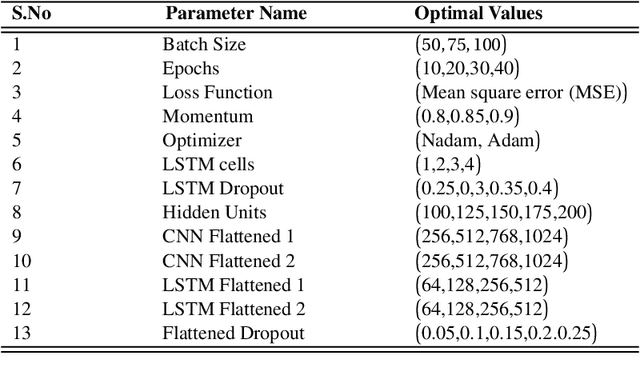
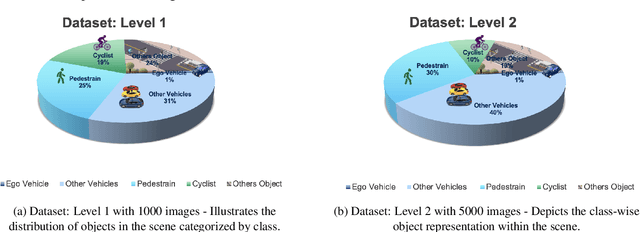
Autonomous vehicles require accurate and reliable short-term trajectory predictions for safe and efficient driving. While most commercial automated vehicles currently use state machine-based algorithms for trajectory forecasting, recent efforts have focused on end-to-end data-driven systems. Often, the design of these models is limited by the availability of datasets, which are typically restricted to generic scenarios. To address this limitation, we have developed a synthetic dataset for short-term trajectory prediction tasks using the CARLA simulator. This dataset is extensive and incorporates what is considered complex scenarios - pedestrians crossing the road, vehicles overtaking - and comprises 6000 perspective view images with corresponding IMU and odometry information for each frame. Furthermore, an end-to-end short-term trajectory prediction model using convolutional neural networks (CNN) and long short-term memory (LSTM) networks has also been developed. This model can handle corner cases, such as slowing down near zebra crossings and stopping when pedestrians cross the road, without the need for explicit encoding of the surrounding environment. In an effort to accelerate this research and assist others, we are releasing our dataset and model to the research community. Our datasets are publicly available on https://github.com/sharmasushil/Navigating-Uncertainty-Trajectory-Prediction .
SIM-ECG: A Signal Importance Mask-driven ECGClassification System
Oct 28, 2021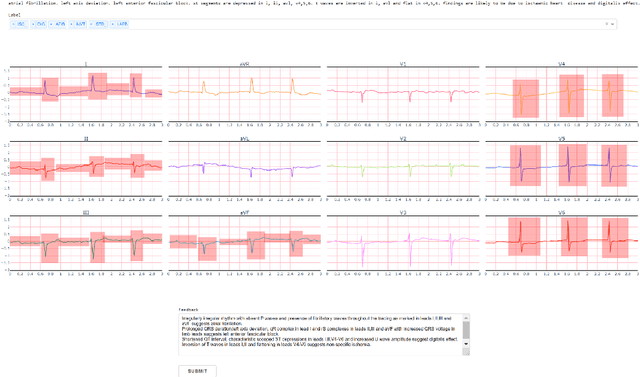
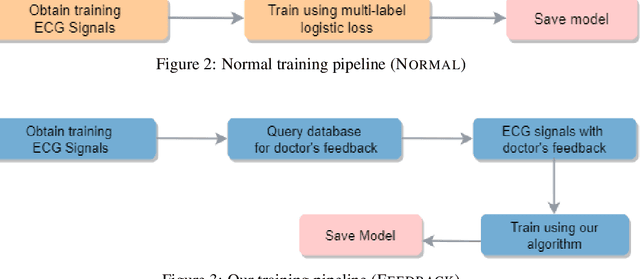
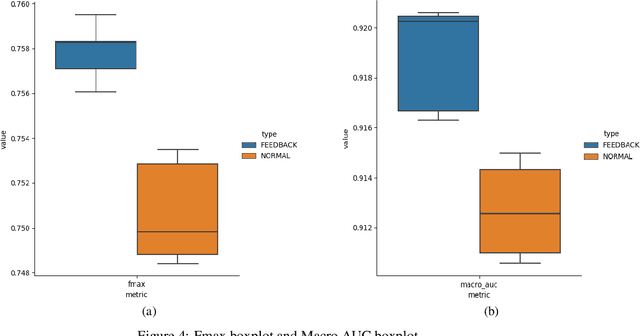
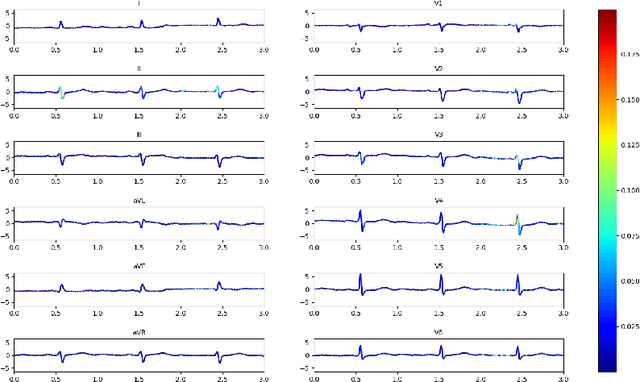
Heart disease is the number one killer, and ECGs can assist in the early diagnosis and prevention of deadly outcomes. Accurate ECG interpretation is critical in detecting heart diseases; however, they are often misinterpreted due to a lack of training or insufficient time spent to detect minute anomalies. Subsequently, researchers turned to machine learning to assist in the analysis. However, existing systems are not as accurate as skilled ECG readers, and black-box approaches to providing diagnosis result in a lack of trust by medical personnel in a given diagnosis. To address these issues, we propose a signal importance mask feedback-based machine learning system that continuously accepts feedback, improves accuracy, and ex-plains the resulting diagnosis. This allows medical personnel to quickly glance at the output and either accept the results, validate the explanation and diagnosis, or quickly correct areas of misinterpretation, giving feedback to the system for improvement. We have tested our system on a publicly available dataset consisting of healthy and disease-indicating samples. We empirically show that our algorithm is better in terms of standard performance measures such as F-score and MacroAUC compared to normal training baseline (without feedback); we also show that our model generates better interpretability maps.