 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescriptor: Distance-Annotated Traffic Perception Question Answering (DTPQA)
Nov 17, 2025The remarkable progress of Vision-Language Models (VLMs) on a variety of tasks has raised interest in their application to automated driving. However, for these models to be trusted in such a safety-critical domain, they must first possess robust perception capabilities, i.e., they must be capable of understanding a traffic scene, which can often be highly complex, with many things happening simultaneously. Moreover, since critical objects and agents in traffic scenes are often at long distances, we require systems with not only strong perception capabilities at close distances (up to 20 meters), but also at long (30+ meters) range. Therefore, it is important to evaluate the perception capabilities of these models in isolation from other skills like reasoning or advanced world knowledge. Distance-Annotated Traffic Perception Question Answering (DTPQA) is a Visual Question Answering (VQA) benchmark designed specifically for this purpose: it can be used to evaluate the perception systems of VLMs in traffic scenarios using trivial yet crucial questions relevant to driving decisions. It consists of two parts: a synthetic benchmark (DTP-Synthetic) created using a simulator, and a real-world benchmark (DTP-Real) built on top of existing images of real traffic scenes. Additionally, DTPQA includes distance annotations, i.e., how far the object in question is from the camera. More specifically, each DTPQA sample consists of (at least): (a) an image, (b) a question, (c) the ground truth answer, and (d) the distance of the object in question, enabling analysis of how VLM performance degrades with increasing object distance. In this article, we provide the dataset itself along with the Python scripts used to create it, which can be used to generate additional data of the same kind.
Evaluating the Impact of Weather-Induced Sensor Occlusion on BEVFusion for 3D Object Detection
Nov 06, 2025Accurate 3D object detection is essential for automated vehicles to navigate safely in complex real-world environments. Bird's Eye View (BEV) representations, which project multi-sensor data into a top-down spatial format, have emerged as a powerful approach for robust perception. Although BEV-based fusion architectures have demonstrated strong performance through multimodal integration, the effects of sensor occlusions, caused by environmental conditions such as fog, haze, or physical obstructions, on 3D detection accuracy remain underexplored. In this work, we investigate the impact of occlusions on both camera and Light Detection and Ranging (LiDAR) outputs using the BEVFusion architecture, evaluated on the nuScenes dataset. Detection performance is measured using mean Average Precision (mAP) and the nuScenes Detection Score (NDS). Our results show that moderate camera occlusions lead to a 41.3% drop in mAP (from 35.6% to 20.9%) when detection is based only on the camera. On the other hand, LiDAR sharply drops in performance only under heavy occlusion, with mAP falling by 47.3% (from 64.7% to 34.1%), with a severe impact on long-range detection. In fused settings, the effect depends on which sensor is occluded: occluding the camera leads to a minor 4.1% drop (from 68.5% to 65.7%), while occluding LiDAR results in a larger 26.8% drop (to 50.1%), revealing the model's stronger reliance on LiDAR for the task of 3D object detection. Our results highlight the need for future research into occlusion-aware evaluation methods and improved sensor fusion techniques that can maintain detection accuracy in the presence of partial sensor failure or degradation due to adverse environmental conditions.
BEVMOSNet: Multimodal Fusion for BEV Moving Object Segmentation
Mar 05, 2025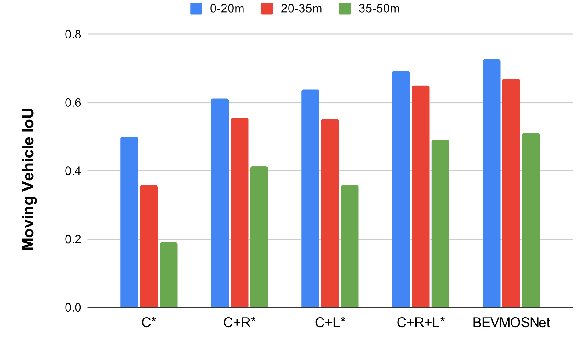
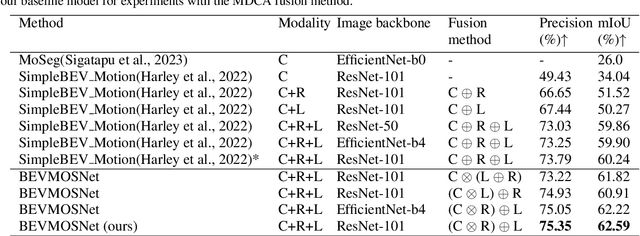
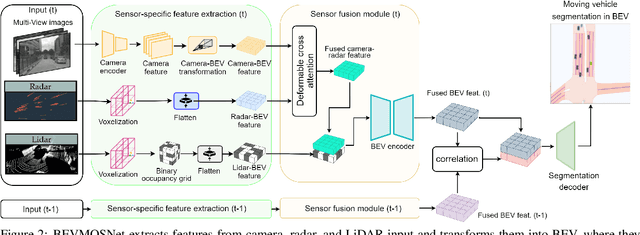
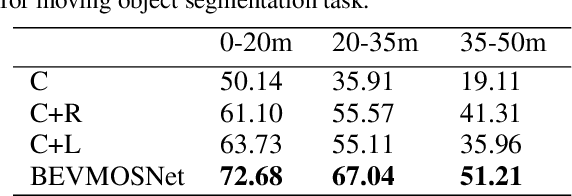
Accurate motion understanding of the dynamic objects within the scene in bird's-eye-view (BEV) is critical to ensure a reliable obstacle avoidance system and smooth path planning for autonomous vehicles. However, this task has received relatively limited exploration when compared to object detection and segmentation with only a few recent vision-based approaches presenting preliminary findings that significantly deteriorate in low-light, nighttime, and adverse weather conditions such as rain. Conversely, LiDAR and radar sensors remain almost unaffected in these scenarios, and radar provides key velocity information of the objects. Therefore, we introduce BEVMOSNet, to our knowledge, the first end-to-end multimodal fusion leveraging cameras, LiDAR, and radar to precisely predict the moving objects in BEV. In addition, we perform a deeper analysis to find out the optimal strategy for deformable cross-attention-guided sensor fusion for cross-sensor knowledge sharing in BEV. While evaluating BEVMOSNet on the nuScenes dataset, we show an overall improvement in IoU score of 36.59% compared to the vision-based unimodal baseline BEV-MoSeg (Sigatapu et al., 2023), and 2.35% compared to the multimodel SimpleBEV (Harley et al., 2022), extended for the motion segmentation task, establishing this method as the state-of-the-art in BEV motion segmentation.
Revisiting Birds Eye View Perception Models with Frozen Foundation Models: DINOv2 and Metric3Dv2
Jan 14, 2025



Birds Eye View perception models require extensive data to perform and generalize effectively. While traditional datasets often provide abundant driving scenes from diverse locations, this is not always the case. It is crucial to maximize the utility of the available training data. With the advent of large foundation models such as DINOv2 and Metric3Dv2, a pertinent question arises: can these models be integrated into existing model architectures to not only reduce the required training data but surpass the performance of current models? We choose two model architectures in the vehicle segmentation domain to alter: Lift-Splat-Shoot, and Simple-BEV. For Lift-Splat-Shoot, we explore the implementation of frozen DINOv2 for feature extraction and Metric3Dv2 for depth estimation, where we greatly exceed the baseline results by 7.4 IoU while utilizing only half the training data and iterations. Furthermore, we introduce an innovative application of Metric3Dv2's depth information as a PseudoLiDAR point cloud incorporated into the Simple-BEV architecture, replacing traditional LiDAR. This integration results in a +3 IoU improvement compared to the Camera-only model.
Minimizing Occlusion Effect on Multi-View Camera Perception in BEV with Multi-Sensor Fusion
Jan 10, 2025Autonomous driving technology is rapidly evolving, offering the potential for safer and more efficient transportation. However, the performance of these systems can be significantly compromised by the occlusion on sensors due to environmental factors like dirt, dust, rain, and fog. These occlusions severely affect vision-based tasks such as object detection, vehicle segmentation, and lane recognition. In this paper, we investigate the impact of various kinds of occlusions on camera sensor by projecting their effects from multi-view camera images of the nuScenes dataset into the Bird's-Eye View (BEV) domain. This approach allows us to analyze how occlusions spatially distribute and influence vehicle segmentation accuracy within the BEV domain. Despite significant advances in sensor technology and multi-sensor fusion, a gap remains in the existing literature regarding the specific effects of camera occlusions on BEV-based perception systems. To address this gap, we use a multi-sensor fusion technique that integrates LiDAR and radar sensor data to mitigate the performance degradation caused by occluded cameras. Our findings demonstrate that this approach significantly enhances the accuracy and robustness of vehicle segmentation tasks, leading to more reliable autonomous driving systems.
Reflective Teacher: Semi-Supervised Multimodal 3D Object Detection in Bird's-Eye-View via Uncertainty Measure
Dec 05, 2024Applying pseudo labeling techniques has been found to be advantageous in semi-supervised 3D object detection (SSOD) in Bird's-Eye-View (BEV) for autonomous driving, particularly where labeled data is limited. In the literature, Exponential Moving Average (EMA) has been used for adjustments of the weights of teacher network by the student network. However, the same induces catastrophic forgetting in the teacher network. In this work, we address this issue by introducing a novel concept of Reflective Teacher where the student is trained by both labeled and pseudo labeled data while its knowledge is progressively passed to the teacher through a regularizer to ensure retention of previous knowledge. Additionally, we propose Geometry Aware BEV Fusion (GA-BEVFusion) for efficient alignment of multi-modal BEV features, thus reducing the disparity between the modalities - camera and LiDAR. This helps to map the precise geometric information embedded among LiDAR points reliably with the spatial priors for extraction of semantic information from camera images. Our experiments on the nuScenes and Waymo datasets demonstrate: 1) improved performance over state-of-the-art methods in both fully supervised and semi-supervised settings; 2) Reflective Teacher achieves equivalent performance with only 25% and 22% of labeled data for nuScenes and Waymo datasets respectively, in contrast to other fully supervised methods that utilize the full labeled dataset.
Deformable Convolution Based Road Scene Semantic Segmentation of Fisheye Images in Autonomous Driving
Jul 23, 2024



This study investigates the effectiveness of modern Deformable Convolutional Neural Networks (DCNNs) for semantic segmentation tasks, particularly in autonomous driving scenarios with fisheye images. These images, providing a wide field of view, pose unique challenges for extracting spatial and geometric information due to dynamic changes in object attributes. Our experiments focus on segmenting the WoodScape fisheye image dataset into ten distinct classes, assessing the Deformable Networks' ability to capture intricate spatial relationships and improve segmentation accuracy. Additionally, we explore different loss functions to address class imbalance issues and compare the performance of conventional CNN architectures with Deformable Convolution-based CNNs, including Vanilla U-Net and Residual U-Net architectures. The significant improvement in mIoU score resulting from integrating Deformable CNNs demonstrates their effectiveness in handling the geometric distortions present in fisheye imagery, exceeding the performance of traditional CNN architectures. This underscores the significant role of Deformable convolution in enhancing semantic segmentation performance for fisheye imagery.
MapsTP: HD Map Images Based Multimodal Trajectory Prediction for Automated Vehicles
Jul 08, 2024



Predicting ego vehicle trajectories remains a critical challenge, especially in urban and dense areas due to the unpredictable behaviours of other vehicles and pedestrians. Multimodal trajectory prediction enhances decision-making by considering multiple possible future trajectories based on diverse sources of environmental data. In this approach, we leverage ResNet-50 to extract image features from high-definition map data and use IMU sensor data to calculate speed, acceleration, and yaw rate. A temporal probabilistic network is employed to compute potential trajectories, selecting the most accurate and highly probable trajectory paths. This method integrates HD map data to improve the robustness and reliability of trajectory predictions for autonomous vehicles.
Optimizing Visual Question Answering Models for Driving: Bridging the Gap Between Human and Machine Attention Patterns
Jun 13, 2024Visual Question Answering (VQA) models play a critical role in enhancing the perception capabilities of autonomous driving systems by allowing vehicles to analyze visual inputs alongside textual queries, fostering natural interaction and trust between the vehicle and its occupants or other road users. This study investigates the attention patterns of humans compared to a VQA model when answering driving-related questions, revealing disparities in the objects observed. We propose an approach integrating filters to optimize the model's attention mechanisms, prioritizing relevant objects and improving accuracy. Utilizing the LXMERT model for a case study, we compare attention patterns of the pre-trained and Filter Integrated models, alongside human answers using images from the NuImages dataset, gaining insights into feature prioritization. We evaluated the models using a Subjective scoring framework which shows that the integration of the feature encoder filter has enhanced the performance of the VQA model by refining its attention mechanisms.
FisheyeDetNet: 360° Surround view Fisheye Camera based Object Detection System for Autonomous Driving
Apr 27, 2024



Object detection is a mature problem in autonomous driving with pedestrian detection being one of the first deployed algorithms. It has been comprehensively studied in the literature. However, object detection is relatively less explored for fisheye cameras used for surround-view near field sensing. The standard bounding box representation fails in fisheye cameras due to heavy radial distortion, particularly in the periphery. To mitigate this, we explore extending the standard object detection output representation of bounding box. We design rotated bounding boxes, ellipse, generic polygon as polar arc/angle representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model FisheyeDetNet with polygon outperforms others and achieves a mAP score of 49.5 % on Valeo fisheye surround-view dataset for automated driving applications. This dataset has 60K images captured from 4 surround-view cameras across Europe, North America and Asia. To the best of our knowledge, this is the first detailed study on object detection on fisheye cameras for autonomous driving scenarios.