 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Estimation using Weighted-loss and Transfer Learning
Apr 11, 2024

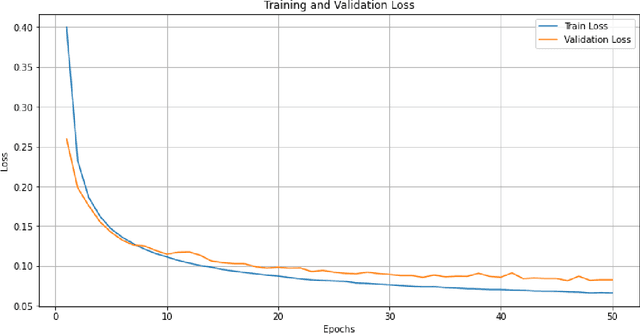
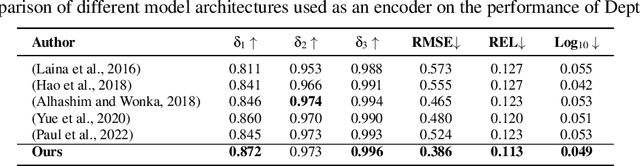
Depth estimation from 2D images is a common computer vision task that has applications in many fields including autonomous vehicles, scene understanding and robotics. The accuracy of a supervised depth estimation method mainly relies on the chosen loss function, the model architecture, quality of data and performance metrics. In this study, we propose a simplified and adaptable approach to improve depth estimation accuracy using transfer learning and an optimized loss function. The optimized loss function is a combination of weighted losses to which enhance robustness and generalization: Mean Absolute Error (MAE), Edge Loss and Structural Similarity Index (SSIM). We use a grid search and a random search method to find optimized weights for the losses, which leads to an improved model. We explore multiple encoder-decoder-based models including DenseNet121, DenseNet169, DenseNet201, and EfficientNet for the supervised depth estimation model on NYU Depth Dataset v2. We observe that the EfficientNet model, pre-trained on ImageNet for classification when used as an encoder, with a simple upsampling decoder, gives the best results in terms of RSME, REL and log10: 0.386, 0.113 and 0.049, respectively. We also perform a qualitative analysis which illustrates that our model produces depth maps that closely resemble ground truth, even in cases where the ground truth is flawed. The results indicate significant improvements in accuracy and robustness, with EfficientNet being the most successful architecture.
Beyond the Known: Adversarial Autoencoders in Novelty Detection
Apr 06, 2024In novelty detection, the goal is to decide if a new data point should be categorized as an inlier or an outlier, given a training dataset that primarily captures the inlier distribution. Recent approaches typically use deep encoder and decoder network frameworks to derive a reconstruction error, and employ this error either to determine a novelty score, or as the basis for a one-class classifier. In this research, we use a similar framework but with a lightweight deep network, and we adopt a probabilistic score with reconstruction error. Our methodology calculates the probability of whether the sample comes from the inlier distribution or not. This work makes two key contributions. The first is that we compute the novelty probability by linearizing the manifold that holds the structure of the inlier distribution. This allows us to interpret how the probability is distributed and can be determined in relation to the local coordinates of the manifold tangent space. The second contribution is that we improve the training protocol for the network. Our results indicate that our approach is effective at learning the target class, and it outperforms recent state-of-the-art methods on several benchmark datasets.
Robust Classification of High-Dimensional Spectroscopy Data Using Deep Learning and Data Synthesis
Mar 26, 2020

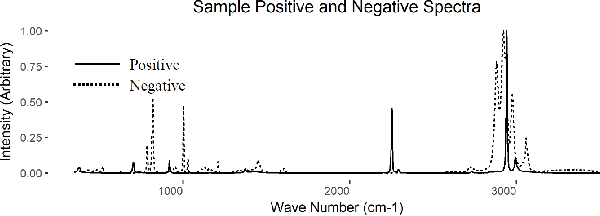
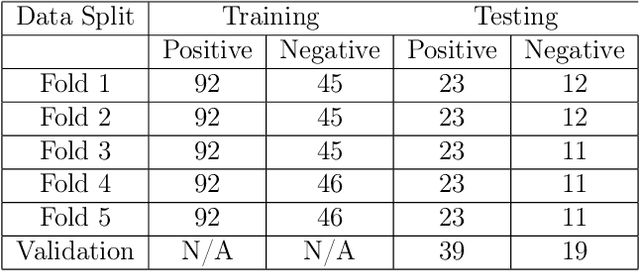
This paper presents a new approach to classification of high dimensional spectroscopy data and demonstrates that it outperforms other current state-of-the art approaches. The specific task we consider is identifying whether samples contain chlorinated solvents or not, based on their Raman spectra. We also examine robustness to classification of outlier samples that are not represented in the training set (negative outliers). A novel application of a locally-connected neural network (NN) for the binary classification of spectroscopy data is proposed and demonstrated to yield improved accuracy over traditionally popular algorithms. Additionally, we present the ability to further increase the accuracy of the locally-connected NN algorithm through the use of synthetic training spectra and we investigate the use of autoencoder based one-class classifiers and outlier detectors. Finally, a two-step classification process is presented as an alternative to the binary and one-class classification paradigms. This process combines the locally-connected NN classifier, the use of synthetic training data, and an autoencoder based outlier detector to produce a model which is shown to both produce high classification accuracy, and be robust to the presence of negative outliers.
A Virtual Testbed for Critical Incident Investigation with Autonomous Remote Aerial Vehicle Surveying, Artificial Intelligence, and Decision Support
Jan 25, 2019
Autonomous robotics and artificial intelligence techniques can be used to support human personnel in the event of critical incidents. These incidents can pose great danger to human life. Some examples of such assistance include: multi-robot surveying of the scene; collection of sensor data and scene imagery, real-time risk assessment and analysis; object identification and anomaly detection; and retrieval of relevant supporting documentation such as standard operating procedures (SOPs). These incidents, although often rare, can involve chemical, biological, radiological/nuclear or explosive (CBRNE) substances and can be of high consequence. Real-world training and deployment of these systems can be costly and sometimes not feasible. For this reason, we have developed a realistic 3D model of a CBRNE scenario to act as a testbed for an initial set of assisting AI tools that we have developed.
* arXiv admin note: substantial text overlap with arXiv:1806.04497
Using a Game Engine to Simulate Critical Incidents and Data Collection by Autonomous Drones
Dec 17, 2018

Using a game engine, we have developed a virtual environment which models important aspects of critical incident scenarios. We focused on modelling phenomena relating to the identification and gathering of key forensic evidence, in order to develop and test a system which can handle chemical, biological, radiological/nuclear or explosive (CBRNe) events autonomously. This allows us to build and validate AI-based technologies, which can be trained and tested in our custom virtual environment before being deployed in real-world scenarios. We have used our virtual scenario to rapidly prototype a system which can use simulated Remote Aerial Vehicles (RAVs) to gather images from the environment for the purpose of mapping. Our environment provides us with an effective medium through which we can develop and test various AI methodologies for critical incident scene assessment, in a safe and controlled manner
* 5 Pages
Skilled Experience Catalogue: A Skill-Balancing Mechanism for Non-Player Characters using Reinforcement Learning
Jun 20, 2018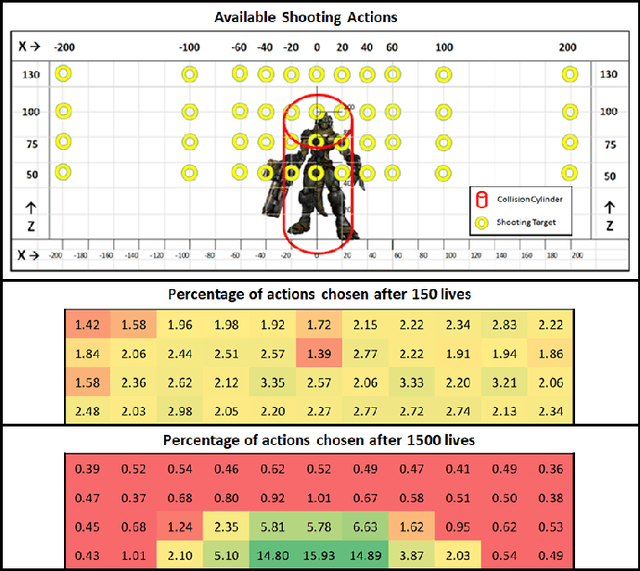
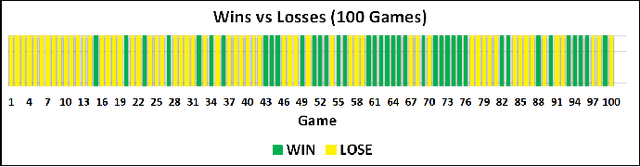
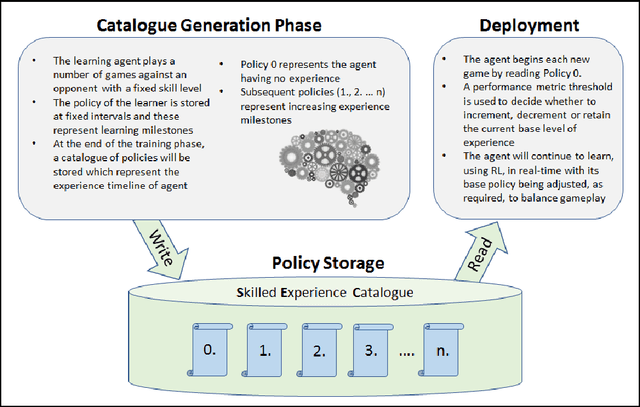
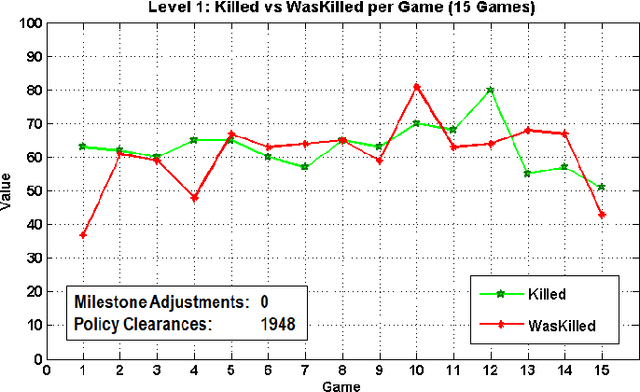
In this paper, we introduce a skill-balancing mechanism for adversarial non-player characters (NPCs), called Skilled Experience Catalogue (SEC). The objective of this mechanism is to approximately match the skill level of an NPC to an opponent in real-time. We test the technique in the context of a First-Person Shooter (FPS) game. Specifically, the technique adjusts a reinforcement learning NPC's proficiency with a weapon based on its current performance against an opponent. Firstly, a catalogue of experience, in the form of stored learning policies, is built up by playing a series of training games. Once the NPC has been sufficiently trained, the catalogue acts as a timeline of experience with incremental knowledge milestones in the form of stored learning policies. If the NPC is performing poorly, it can jump to a later stage in the learning timeline to be equipped with more informed decision-making. Likewise, if it is performing significantly better than the opponent, it will jump to an earlier stage. The NPC continues to learn in real-time using reinforcement learning but its policy is adjusted, as required, by loading the most suitable milestones for the current circumstances.
Adaptive Shooting for Bots in First Person Shooter Games Using Reinforcement Learning
Jun 14, 2018

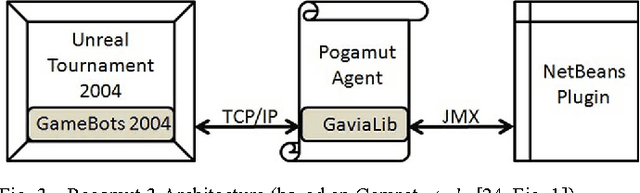
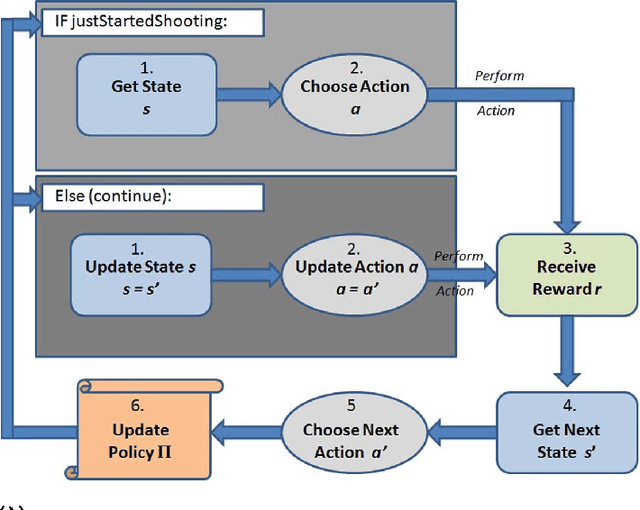
In current state-of-the-art commercial first person shooter games, computer controlled bots, also known as non player characters, can often be easily distinguishable from those controlled by humans. Tell-tale signs such as failed navigation, "sixth sense" knowledge of human players' whereabouts and deterministic, scripted behaviors are some of the causes of this. We propose, however, that one of the biggest indicators of non humanlike behavior in these games can be found in the weapon shooting capability of the bot. Consistently perfect accuracy and "locking on" to opponents in their visual field from any distance are indicative capabilities of bots that are not found in human players. Traditionally, the bot is handicapped in some way with either a timed reaction delay or a random perturbation to its aim, which doesn't adapt or improve its technique over time. We hypothesize that enabling the bot to learn the skill of shooting through trial and error, in the same way a human player learns, will lead to greater variation in game-play and produce less predictable non player characters. This paper describes a reinforcement learning shooting mechanism for adapting shooting over time based on a dynamic reward signal from the amount of damage caused to opponents.
* IEEE Transactions on Computational Intelligence and AI in Games (2015)
Analysis of the Effect of Unexpected Outliers in the Classification of Spectroscopy Data
Jun 14, 2018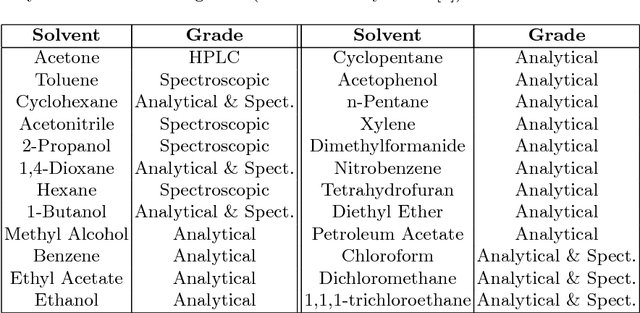

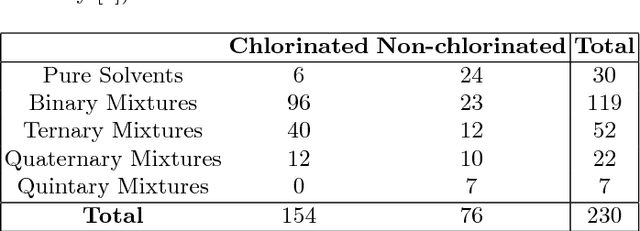

Multi-class classification algorithms are very widely used, but we argue that they are not always ideal from a theoretical perspective, because they assume all classes are characterized by the data, whereas in many applications, training data for some classes may be entirely absent, rare, or statistically unrepresentative. We evaluate one-sided classifiers as an alternative, since they assume that only one class (the target) is well characterized. We consider a task of identifying whether a substance contains a chlorinated solvent, based on its chemical spectrum. For this application, it is not really feasible to collect a statistically representative set of outliers, since that group may contain \emph{anything} apart from the target chlorinated solvents. Using a new one-sided classification toolkit, we compare a One-Sided k-NN algorithm with two well-known binary classification algorithms, and conclude that the one-sided classifier is more robust to unexpected outliers.
* Irish Conference on Artificial Intelligence and Cognitive Science (2009)
Learning to Shoot in First Person Shooter Games by Stabilizing Actions and Clustering Rewards for Reinforcement Learning
Jun 13, 2018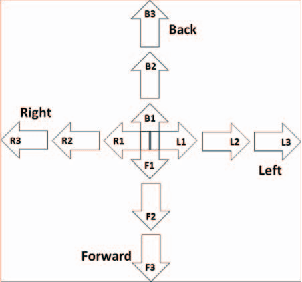
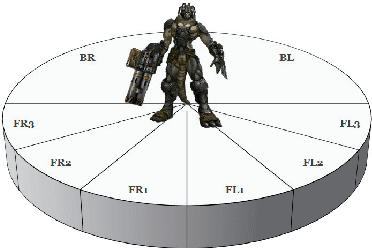
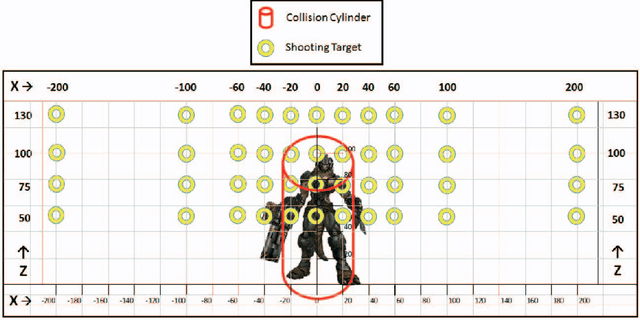
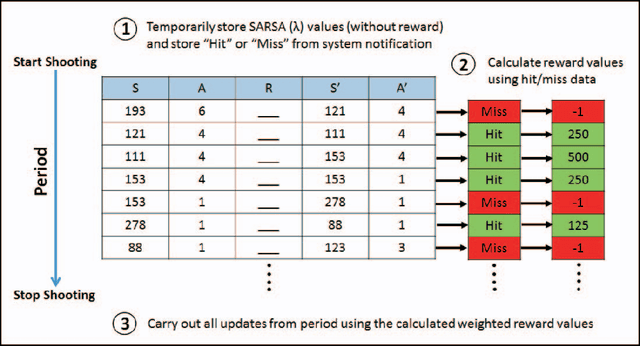
While reinforcement learning (RL) has been applied to turn-based board games for many years, more complex games involving decision-making in real-time are beginning to receive more attention. A challenge in such environments is that the time that elapses between deciding to take an action and receiving a reward based on its outcome can be longer than the interval between successive decisions. We explore this in the context of a non-player character (NPC) in a modern first-person shooter game. Such games take place in 3D environments where players, both human and computer-controlled, compete by engaging in combat and completing task objectives. We investigate the use of RL to enable NPCs to gather experience from game-play and improve their shooting skill over time from a reward signal based on the damage caused to opponents. We propose a new method for RL updates and reward calculations, in which the updates are carried out periodically, after each shooting encounter has ended, and a new weighted-reward mechanism is used which increases the reward applied to actions that lead to damaging the opponent in successive hits in what we term "hit clusters".
* IEEE Conference on Computational Intelligence and Games (CIG), 2015
DRE-Bot: A Hierarchical First Person Shooter Bot Using Multiple Sarsa Reinforcement Learners
Jun 13, 2018



This paper describes an architecture for controlling non-player characters (NPC) in the First Person Shooter (FPS) game Unreal Tournament 2004. Specifically, the DRE-Bot architecture is made up of three reinforcement learners, Danger, Replenish and Explore, which use the tabular Sarsa({\lambda}) algorithm. This algorithm enables the NPC to learn through trial and error building up experience over time in an approach inspired by human learning. Experimentation is carried to measure the performance of DRE-Bot when competing against fixed strategy bots that ship with the game. The discount parameter, {\gamma}, and the trace parameter, {\lambda}, are also varied to see if their values have an effect on the performance.
* 17th International Conference on Computer Games (CGAMES) 2012