 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Estimation using Weighted-loss and Transfer Learning
Apr 11, 2024

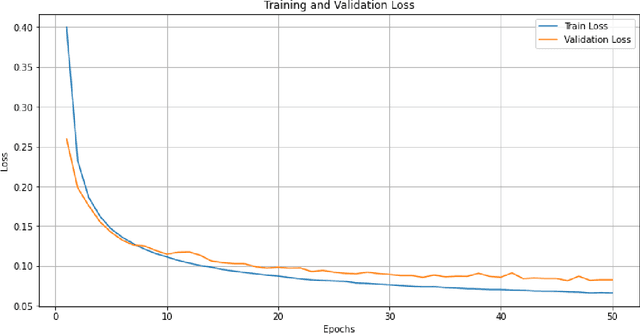
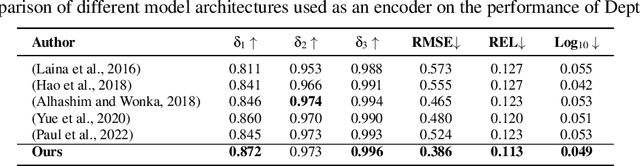
Depth estimation from 2D images is a common computer vision task that has applications in many fields including autonomous vehicles, scene understanding and robotics. The accuracy of a supervised depth estimation method mainly relies on the chosen loss function, the model architecture, quality of data and performance metrics. In this study, we propose a simplified and adaptable approach to improve depth estimation accuracy using transfer learning and an optimized loss function. The optimized loss function is a combination of weighted losses to which enhance robustness and generalization: Mean Absolute Error (MAE), Edge Loss and Structural Similarity Index (SSIM). We use a grid search and a random search method to find optimized weights for the losses, which leads to an improved model. We explore multiple encoder-decoder-based models including DenseNet121, DenseNet169, DenseNet201, and EfficientNet for the supervised depth estimation model on NYU Depth Dataset v2. We observe that the EfficientNet model, pre-trained on ImageNet for classification when used as an encoder, with a simple upsampling decoder, gives the best results in terms of RSME, REL and log10: 0.386, 0.113 and 0.049, respectively. We also perform a qualitative analysis which illustrates that our model produces depth maps that closely resemble ground truth, even in cases where the ground truth is flawed. The results indicate significant improvements in accuracy and robustness, with EfficientNet being the most successful architecture.