 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking SAM2-based Trackers on FMOX
Dec 10, 2025



Several object tracking pipelines extending Segment Anything Model 2 (SAM2) have been proposed in the past year, where the approach is to follow and segment the object from a single exemplar template provided by the user on a initialization frame. We propose to benchmark these high performing trackers (SAM2, EfficientTAM, DAM4SAM and SAMURAI) on datasets containing fast moving objects (FMO) specifically designed to be challenging for tracking approaches. The goal is to understand better current limitations in state-of-the-art trackers by providing more detailed insights on the behavior of these trackers. We show that overall the trackers DAM4SAM and SAMURAI perform well on more challenging sequences.
Scalable and Efficient Hierarchical Visual Topological Mapping
Apr 07, 2024



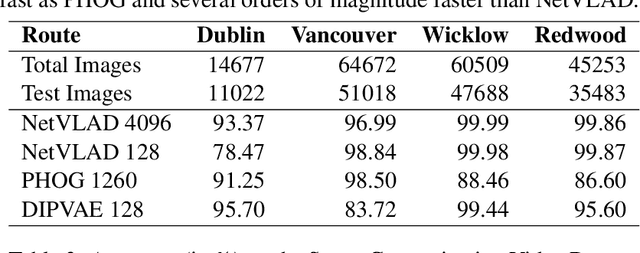
Hierarchical topological representations can significantly reduce search times within mapping and localization algorithms. Although recent research has shown the potential for such approaches, limited consideration has been given to the suitability and comparative performance of different global feature representations within this context. In this work, we evaluate state-of-the-art hand-crafted and learned global descriptors using a hierarchical topological mapping technique on benchmark datasets and present results of a comprehensive evaluation of the impact of the global descriptor used. Although learned descriptors have been incorporated into place recognition methods to improve retrieval accuracy and enhance overall recall, the problem of scalability and efficiency when applied to longer trajectories has not been adequately addressed in a majority of research studies. Based on our empirical analysis of multiple runs, we identify that continuity and distinctiveness are crucial characteristics for an optimal global descriptor that enable efficient and scalable hierarchical mapping, and present a methodology for quantifying and contrasting these characteristics across different global descriptors. Our study demonstrates that the use of global descriptors based on an unsupervised learned Variational Autoencoder (VAE) excels in these characteristics and achieves significantly lower runtime. It runs on a consumer grade desktop, up to 2.3x faster than the second best global descriptor, NetVLAD, and up to 9.5x faster than the hand-crafted descriptor, PHOG, on the longest track evaluated (St Lucia, 17.6 km), without sacrificing overall recall performance.
WoodScape Motion Segmentation for Autonomous Driving -- CVPR 2023 OmniCV Workshop Challenge
Jan 16, 2024Motion segmentation is a complex yet indispensable task in autonomous driving. The challenges introduced by the ego-motion of the cameras, radial distortion in fisheye lenses, and the need for temporal consistency make the task more complicated, rendering traditional and standard Convolutional Neural Network (CNN) approaches less effective. The consequent laborious data labeling, representation of diverse and uncommon scenarios, and extensive data capture requirements underscore the imperative of synthetic data for improving machine learning model performance. To this end, we employ the PD-WoodScape synthetic dataset developed by Parallel Domain, alongside the WoodScape fisheye dataset. Thus, we present the WoodScape fisheye motion segmentation challenge for autonomous driving, held as part of the CVPR 2023 Workshop on Omnidirectional Computer Vision (OmniCV). As one of the first competitions focused on fisheye motion segmentation, we aim to explore and evaluate the potential and impact of utilizing synthetic data in this domain. In this paper, we provide a detailed analysis on the competition which attracted the participation of 112 global teams and a total of 234 submissions. This study delineates the complexities inherent in the task of motion segmentation, emphasizes the significance of fisheye datasets, articulate the necessity for synthetic datasets and the resultant domain gap they engender, outlining the foundational blueprint for devising successful solutions. Subsequently, we delve into the details of the baseline experiments and winning methods evaluating their qualitative and quantitative results, providing with useful insights.
Fast and Efficient Scene Categorization for Autonomous Driving using VAEs
Oct 26, 2022

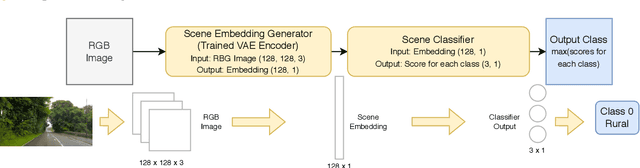
Scene categorization is a useful precursor task that provides prior knowledge for many advanced computer vision tasks with a broad range of applications in content-based image indexing and retrieval systems. Despite the success of data driven approaches in the field of computer vision such as object detection, semantic segmentation, etc., their application in learning high-level features for scene recognition has not achieved the same level of success. We propose to generate a fast and efficient intermediate interpretable generalized global descriptor that captures coarse features from the image and use a classification head to map the descriptors to 3 scene categories: Rural, Urban and Suburban. We train a Variational Autoencoder in an unsupervised manner and map images to a constrained multi-dimensional latent space and use the latent vectors as compact embeddings that serve as global descriptors for images. The experimental results evidence that the VAE latent vectors capture coarse information from the image, supporting their usage as global descriptors. The proposed global descriptor is very compact with an embedding length of 128, significantly faster to compute, and is robust to seasonal and illuminational changes, while capturing sufficient scene information required for scene categorization.
* Published in the 24th Irish Machine Vision and Image Processing Conference (IMVIP 2022)
GP-net: Grasp Proposal for Mobile Manipulators
Sep 21, 2022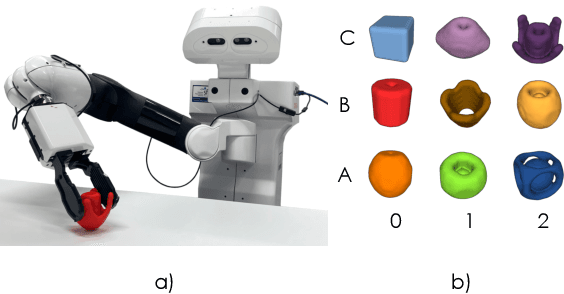

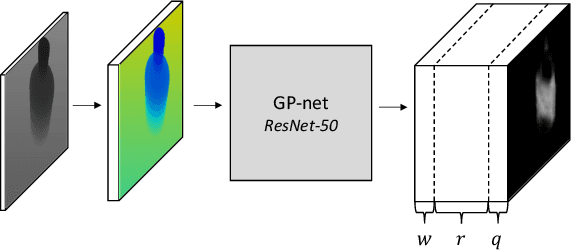
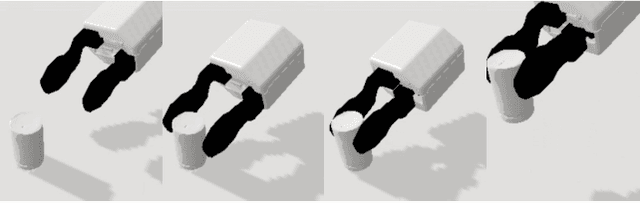
We present the Grasp Proposal Network (GP-net), a Convolutional Neural Network model which can generate 6-DOF grasps for mobile manipulators. To train GP-net, we synthetically generate a dataset containing depth-images and ground-truth grasp information for more than 1400 objects. In real-world experiments we use the EGAD! grasping benchmark to evaluate GP-net against two commonly used algorithms, the Volumetric Grasping Network (VGN) and the Grasp Pose Detection package (GPD), on a PAL TIAGo mobile manipulator. GP-net achieves grasp success rates of 82.2% compared to 57.8% for VGN and 63.3% with GPD. In contrast to the state-of-the-art methods in robotic grasping, GP-net can be used out-of-the-box for grasping objects with mobile manipulators without limiting the workspace, requiring table segmentation or needing a high-end GPU. To encourage the usage of GP-net, we provide a ROS package along with our code and pre-trained models at https://aucoroboticsmu.github.io/GP-net/.
Woodscape Fisheye Object Detection for Autonomous Driving -- CVPR 2022 OmniCV Workshop Challenge
Jun 26, 2022



Object detection is a comprehensively studied problem in autonomous driving. However, it has been relatively less explored in the case of fisheye cameras. The strong radial distortion breaks the translation invariance inductive bias of Convolutional Neural Networks. Thus, we present the WoodScape fisheye object detection challenge for autonomous driving which was held as part of the CVPR 2022 Workshop on Omnidirectional Computer Vision (OmniCV). This is one of the first competitions focused on fisheye camera object detection. We encouraged the participants to design models which work natively on fisheye images without rectification. We used CodaLab to host the competition based on the publicly available WoodScape fisheye dataset. In this paper, we provide a detailed analysis on the competition which attracted the participation of 120 global teams and a total of 1492 submissions. We briefly discuss the details of the winning methods and analyze their qualitative and quantitative results.
ViT-BEVSeg: A Hierarchical Transformer Network for Monocular Birds-Eye-View Segmentation
May 31, 2022
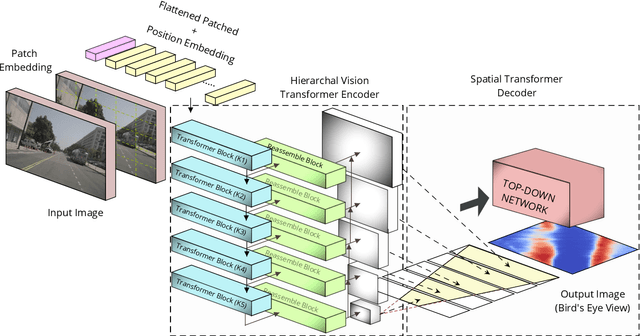

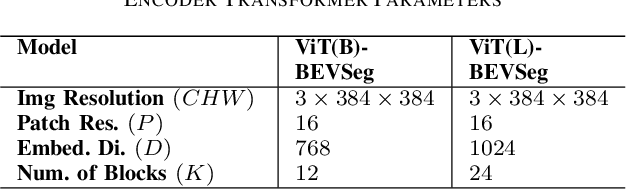
Generating a detailed near-field perceptual model of the environment is an important and challenging problem in both self-driving vehicles and autonomous mobile robotics. A Bird Eye View (BEV) map, providing a panoptic representation, is a commonly used approach that provides a simplified 2D representation of the vehicle surroundings with accurate semantic level segmentation for many downstream tasks. Current state-of-the art approaches to generate BEV-maps employ a Convolutional Neural Network (CNN) backbone to create feature-maps which are passed through a spatial transformer to project the derived features onto the BEV coordinate frame. In this paper, we evaluate the use of vision transformers (ViT) as a backbone architecture to generate BEV maps. Our network architecture, ViT-BEVSeg, employs standard vision transformers to generate a multi-scale representation of the input image. The resulting representation is then provided as an input to a spatial transformer decoder module which outputs segmentation maps in the BEV grid. We evaluate our approach on the nuScenes dataset demonstrating a considerable improvement in the performance relative to state-of-the-art approaches.
2.5D Vehicle Odometry Estimation
Nov 16, 2021

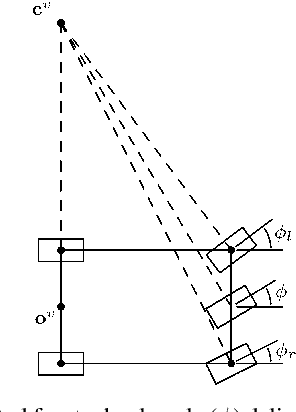
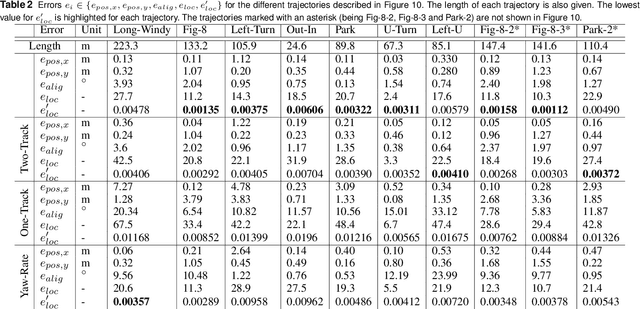
It is well understood that in ADAS applications, a good estimate of the pose of the vehicle is required. This paper proposes a metaphorically named 2.5D odometry, whereby the planar odometry derived from the yaw rate sensor and four wheel speed sensors is augmented by a linear model of suspension. While the core of the planar odometry is a yaw rate model that is already understood in the literature, we augment this by fitting a quadratic to the incoming signals, enabling interpolation, extrapolation, and a finer integration of the vehicle position. We show, by experimental results with a DGPS/IMU reference, that this model provides highly accurate odometry estimates, compared with existing methods. Utilising sensors that return the change in height of vehicle reference points with changing suspension configurations, we define a planar model of the vehicle suspension, thus augmenting the odometry model. We present an experimental framework and evaluations criteria by which the goodness of the odometry is evaluated and compared with existing methods. This odometry model has been designed to support low-speed surround-view camera systems that are well-known. Thus, we present some application results that show a performance boost for viewing and computer vision applications using the proposed odometry
* 13 pages, 16 figures, 2 tables
Woodscape Fisheye Semantic Segmentation for Autonomous Driving -- CVPR 2021 OmniCV Workshop Challenge
Jul 17, 2021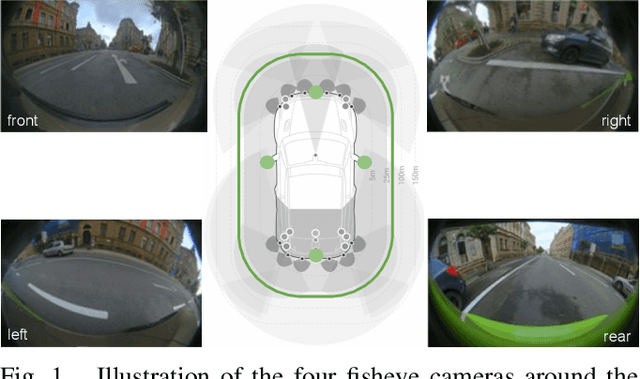
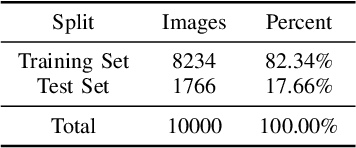
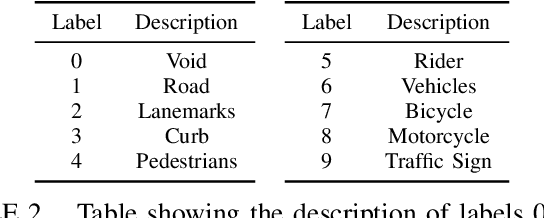

We present the WoodScape fisheye semantic segmentation challenge for autonomous driving which was held as part of the CVPR 2021 Workshop on Omnidirectional Computer Vision (OmniCV). This challenge is one of the first opportunities for the research community to evaluate the semantic segmentation techniques targeted for fisheye camera perception. Due to strong radial distortion standard models don't generalize well to fisheye images and hence the deformations in the visual appearance of objects and entities needs to be encoded implicitly or as explicit knowledge. This challenge served as a medium to investigate the challenges and new methodologies to handle the complexities with perception on fisheye images. The challenge was hosted on CodaLab and used the recently released WoodScape dataset comprising of 10k samples. In this paper, we provide a summary of the competition which attracted the participation of 71 global teams and a total of 395 submissions. The top teams recorded significantly improved mean IoU and accuracy scores over the baseline PSPNet with ResNet-50 backbone. We summarize the methods of winning algorithms and analyze the failure cases. We conclude by providing future directions for the research.
OdoViz: A 3D Odometry Visualization and Processing Tool
Jul 15, 2021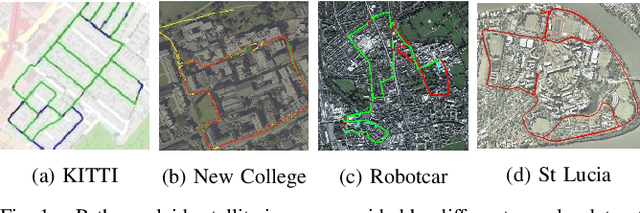

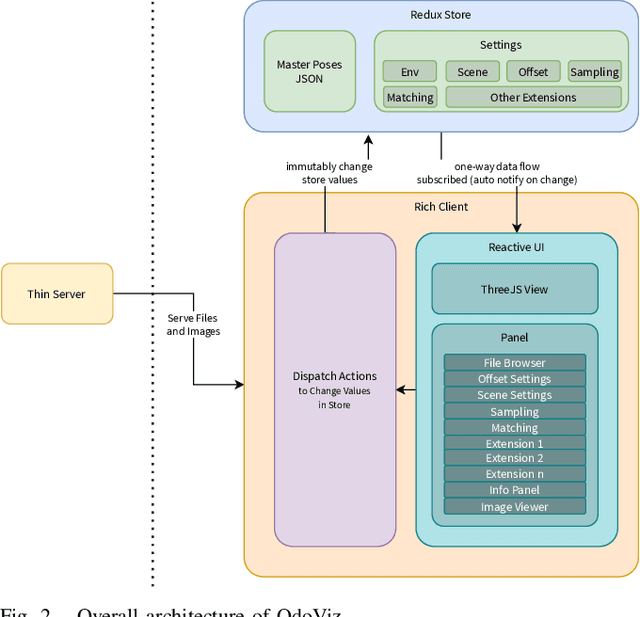

OdoViz is a reactive web-based tool for 3D visualization and processing of autonomous vehicle datasets designed to support common tasks in visual place recognition research. The system includes functionality for loading, inspecting, visualizing, and processing GPS/INS poses, point clouds and camera images. It supports a number of commonly used driving datasets and can be adapted to load custom datasets with minimal effort. OdoViz's design consists of a slim server to serve the datasets coupled with a rich client frontend. This design supports multiple deployment configurations including single user stand-alone installations, research group installations serving datasets internally across a lab, or publicly accessible web-frontends for providing online interfaces for exploring and interacting with datasets. The tool allows viewing complete vehicle trajectories traversed at multiple different time periods simultaneously, facilitating tasks such as sub-sampling, comparing and finding pose correspondences both across and within sequences. This significantly reduces the effort required in creating subsets of data from existing datasets for machine learning tasks. Further to the above, the system also supports adding custom extensions and plugins to extend the capabilities of the software for other potential data management, visualization and processing tasks. The platform has been open-sourced to promote its use and encourage further contributions from the research community.