 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroLGP-SM: Scalable Surrogate-Assisted Neuroevolution for Deep Neural Networks
Apr 12, 2024Evolutionary Algorithms (EAs) play a crucial role in the architectural configuration and training of Artificial Deep Neural Networks (DNNs), a process known as neuroevolution. However, neuroevolution is hindered by its inherent computational expense, requiring multiple generations, a large population, and numerous epochs. The most computationally intensive aspect lies in evaluating the fitness function of a single candidate solution. To address this challenge, we employ Surrogate-assisted EAs (SAEAs). While a few SAEAs approaches have been proposed in neuroevolution, none have been applied to truly large DNNs due to issues like intractable information usage. In this work, drawing inspiration from Genetic Programming semantics, we use phenotypic distance vectors, outputted from DNNs, alongside Kriging Partial Least Squares (KPLS), an approach that is effective in handling these large vectors, making them suitable for search. Our proposed approach, named Neuro-Linear Genetic Programming surrogate model (NeuroLGP-SM), efficiently and accurately estimates DNN fitness without the need for complete evaluations. NeuroLGP-SM demonstrates competitive or superior results compared to 12 other methods, including NeuroLGP without SM, convolutional neural networks, support vector machines, and autoencoders. Additionally, it is worth noting that NeuroLGP-SM is 25% more energy-efficient than its NeuroLGP counterpart. This efficiency advantage adds to the overall appeal of our proposed NeuroLGP-SM in optimising the configuration of large DNNs.
NeuroLGP-SM: A Surrogate-assisted Neuroevolution Approach using Linear Genetic Programming
Mar 28, 2024
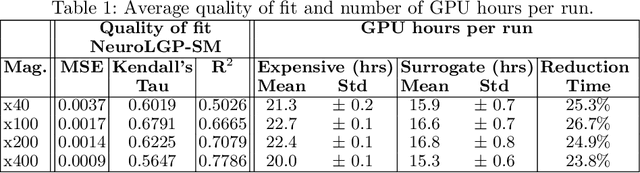
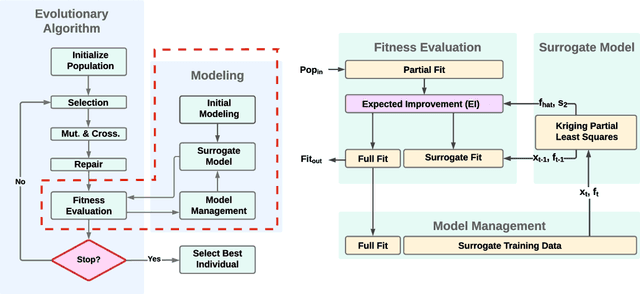
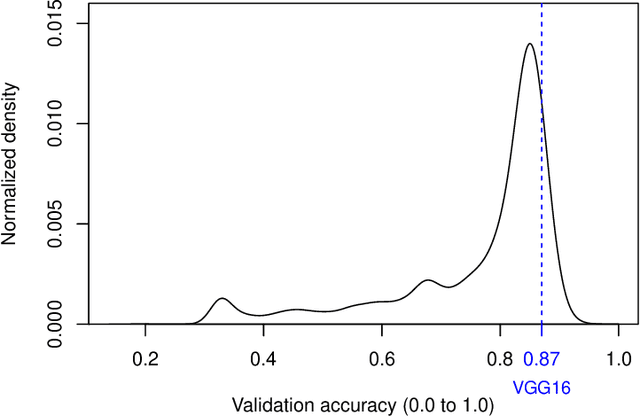
Evolutionary algorithms are increasingly recognised as a viable computational approach for the automated optimisation of deep neural networks (DNNs) within artificial intelligence. This method extends to the training of DNNs, an approach known as neuroevolution. However, neuroevolution is an inherently resource-intensive process, with certain studies reporting the consumption of thousands of GPU days for refining and training a single DNN network. To address the computational challenges associated with neuroevolution while still attaining good DNN accuracy, surrogate models emerge as a pragmatic solution. Despite their potential, the integration of surrogate models into neuroevolution is still in its early stages, hindered by factors such as the effective use of high-dimensional data and the representation employed in neuroevolution. In this context, we address these challenges by employing a suitable representation based on Linear Genetic Programming, denoted as NeuroLGP, and leveraging Kriging Partial Least Squares. The amalgamation of these two techniques culminates in our proposed methodology known as the NeuroLGP-Surrogate Model (NeuroLGP-SM). For comparison purposes, we also code and use a baseline approach incorporating a repair mechanism, a common practice in neuroevolution. Notably, the baseline approach surpasses the renowned VGG-16 model in accuracy. Given the computational intensity inherent in DNN operations, a singular run is typically the norm. To evaluate the efficacy of our proposed approach, we conducted 96 independent runs. Significantly, our methodologies consistently outperform the baseline, with the SM model demonstrating superior accuracy or comparable results to the NeuroLGP approach. Noteworthy is the additional advantage that the SM approach exhibits a 25% reduction in computational requirements, further emphasising its efficiency for neuroevolution.
Evolutionary Multi-objective Optimisation in Neurotrajectory Prediction
Aug 04, 2023Machine learning has rapidly evolved during the last decade, achieving expert human performance on notoriously challenging problems such as image classification. This success is partly due to the re-emergence of bio-inspired modern artificial neural networks (ANNs) along with the availability of computation power, vast labelled data and ingenious human-based expert knowledge as well as optimisation approaches that can find the correct configuration (and weights) for these networks. Neuroevolution is a term used for the latter when employing evolutionary algorithms. Most of the works in neuroevolution have focused their attention in a single type of ANNs, named Convolutional Neural Networks (CNNs). Moreover, most of these works have used a single optimisation approach. This work makes a progressive step forward in neuroevolution for vehicle trajectory prediction, referred to as neurotrajectory prediction, where multiple objectives must be considered. To this end, rich ANNs composed of CNNs and Long-short Term Memory Network are adopted. Two well-known and robust Evolutionary Multi-objective Optimisation (EMO) algorithms, NSGA-II and MOEA/D are also adopted. The completely different underlying mechanism of each of these algorithms sheds light on the implications of using one over the other EMO approach in neurotrajectory prediction. In particular, the importance of considering objective scaling is highlighted, finding that MOEA/D can be more adept at focusing on specific objectives whereas, NSGA-II tends to be more invariant to objective scaling. Additionally, certain objectives are shown to be either beneficial or detrimental to finding valid models, for instance, inclusion of a distance feedback objective was considerably detrimental to finding valid models, while a lateral velocity objective was more beneficial.
* 38 pages, 6 Figure, 10 Tables
Initial Steps Towards Tackling High-dimensional Surrogate Modeling for Neuroevolution Using Kriging Partial Least Squares
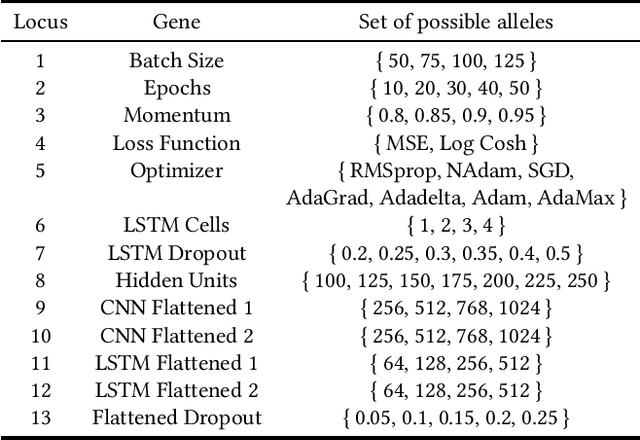
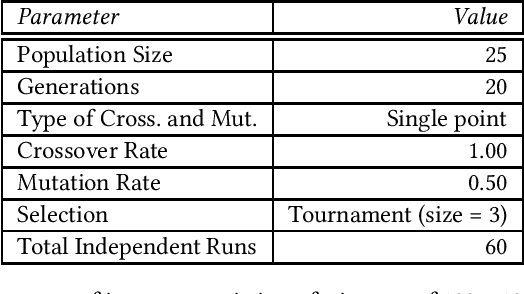
May 11, 2023Surrogate-assisted evolutionary algorithms (SAEAs) aim to use efficient computational models with the goal of approximating the fitness function in evolutionary computation systems. This area of research has been active for over two decades and has received significant attention from the specialised research community in different areas, for example, single and many objective optimisation or dynamic and stationary optimisation problems. An emergent and exciting area that has received little attention from the SAEAs community is in neuroevolution. This refers to the use of evolutionary algorithms in the automatic configuration of artificial neural network (ANN) architectures, hyper-parameters and/or the training of ANNs. However, ANNs suffer from two major issues: (a) the use of highly-intense computational power for their correct training, and (b) the highly specialised human expertise required to correctly configure ANNs necessary to get a well-performing network. This work aims to fill this important research gap in SAEAs in neuroevolution by addressing these two issues. We demonstrate how one can use a Kriging Partial Least Squares method that allows efficient computation of good approximate surrogate models compared to the well-known Kriging method, which normally cannot be used in neuroevolution due to the high dimensionality of the data.
Evolving the MCTS Upper Confidence Bounds for Trees Using a Semantic-inspired Evolutionary Algorithm in the Game of Carcassonne
Aug 29, 2022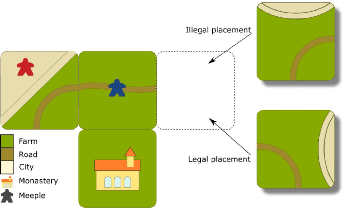

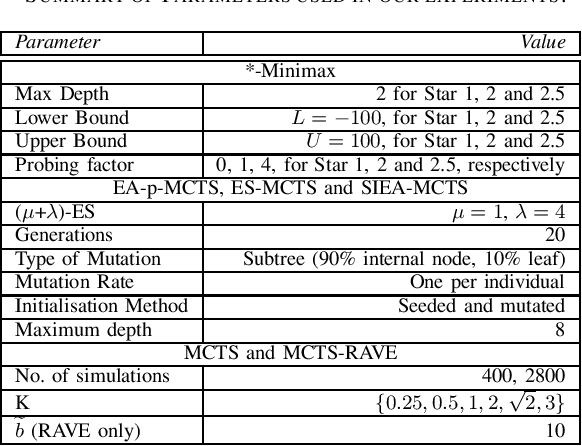

Monte Carlo Tree Search (MCTS) is a sampling best-first method to search for optimal decisions. The success of MCTS depends heavily on how the tree is built and the selection process plays a fundamental role in this. One particular selection mechanism that has proved to be reliable is based on the Upper Confidence Bounds for Trees (UCT). The UCT attempts to balance exploration and exploitation by considering the values stored in the statistical tree of the MCTS. However, some tuning of the MCTS UCT is necessary for this to work well. In this work, we use Evolutionary Algorithms (EAs) to evolve mathematical expressions with the goal to substitute the UCT formula and use the evolved expressions in MCTS. More specifically, we evolve expressions by means of our proposed Semantic-inspired Evolutionary Algorithm in MCTS approach (SIEA-MCTS). This is inspired by semantics in Genetic Programming (GP), where the use of fitness cases is seen as a requirement to be adopted in GP. Fitness cases are normally used to determine the fitness of individuals and can be used to compute the semantic similarity (or dissimilarity) of individuals. However, fitness cases are not available in MCTS. We extend this notion by using multiple reward values from MCTS that allow us to determine both the fitness of an individual and its semantics. By doing so, we show how SIEA-MCTS is able to successfully evolve mathematical expressions that yield better or competitive results compared to UCT without the need of tuning these evolved expressions. We compare the performance of the proposed SIEA-MCTS against MCTS algorithms, MCTS Rapid Action Value Estimation algorithms, three variants of the *-minimax family of algorithms, a random controller and two more EA approaches. We consistently show how SIEA-MCTS outperforms most of these intelligent controllers in the challenging game of Carcassonne.
Highlights of Semantics in Multi-objective Genetic Programming
Jun 13, 2022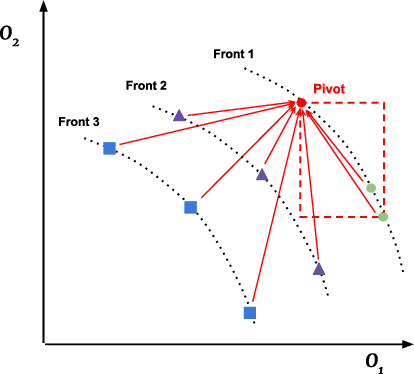
Semantics is a growing area of research in Genetic programming (GP) and refers to the behavioural output of a Genetic Programming individual when executed. This research expands upon the current understanding of semantics by proposing a new approach: Semantic-based Distance as an additional criteriOn (SDO), in the thus far, somewhat limited researched area of semantics in Multi-objective GP (MOGP). Our work included an expansive analysis of the GP in terms of performance and diversity metrics, using two additional semantic-based approaches, namely Semantic Similarity-based Crossover (SCC) and Semantic-based Crowding Distance (SCD). Each approach is integrated into two evolutionary multi-objective (EMO) frameworks: Non-dominated Sorting Genetic Algorithm II (NSGA-II) and the Strength Pareto Evolutionary Algorithm 2 (SPEA2), and along with the three semantic approaches, the canonical form of NSGA-II and SPEA2 are rigorously compared. Using highly-unbalanced binary classification datasets, we demonstrated that the newly proposed approach of SDO consistently generated more non-dominated solutions, with better diversity and improved hypervolume results.
ViT-BEVSeg: A Hierarchical Transformer Network for Monocular Birds-Eye-View Segmentation
May 31, 2022
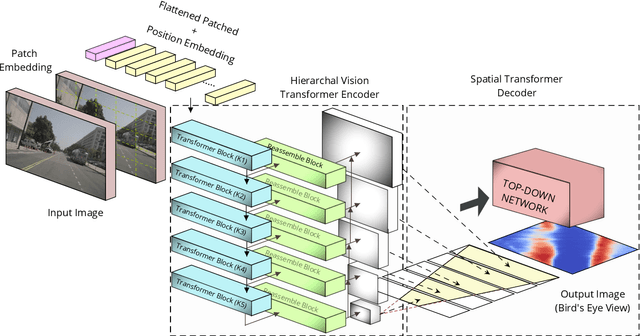

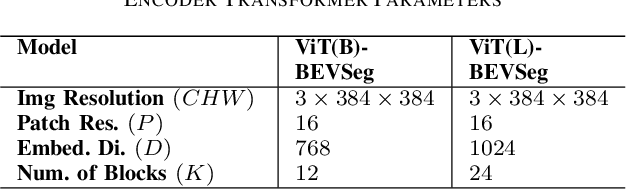
Generating a detailed near-field perceptual model of the environment is an important and challenging problem in both self-driving vehicles and autonomous mobile robotics. A Bird Eye View (BEV) map, providing a panoptic representation, is a commonly used approach that provides a simplified 2D representation of the vehicle surroundings with accurate semantic level segmentation for many downstream tasks. Current state-of-the art approaches to generate BEV-maps employ a Convolutional Neural Network (CNN) backbone to create feature-maps which are passed through a spatial transformer to project the derived features onto the BEV coordinate frame. In this paper, we evaluate the use of vision transformers (ViT) as a backbone architecture to generate BEV maps. Our network architecture, ViT-BEVSeg, employs standard vision transformers to generate a multi-scale representation of the input image. The resulting representation is then provided as an input to a spatial transformer decoder module which outputs segmentation maps in the BEV grid. We evaluate our approach on the nuScenes dataset demonstrating a considerable improvement in the performance relative to state-of-the-art approaches.
Neuroevolutionary Multi-objective approaches to Trajectory Prediction in Autonomous Vehicles
May 06, 2022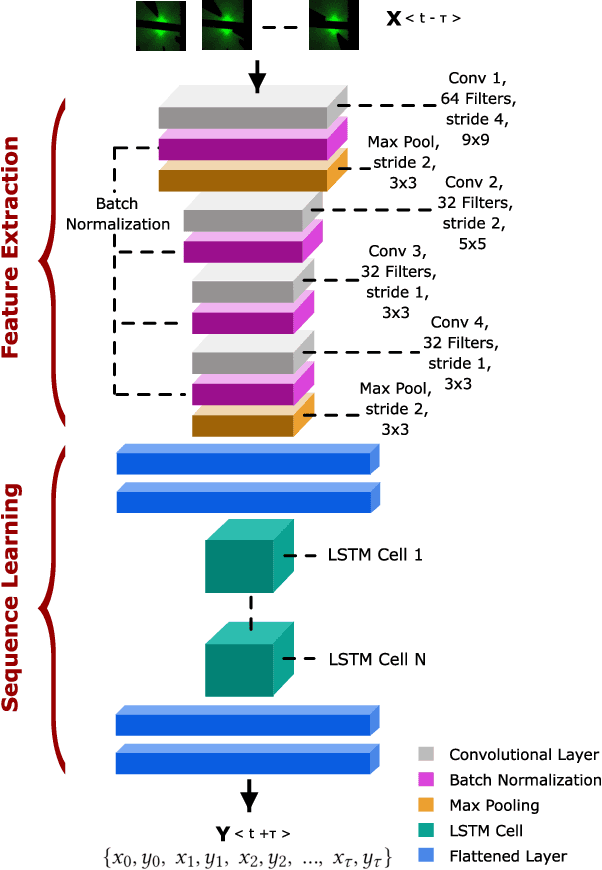
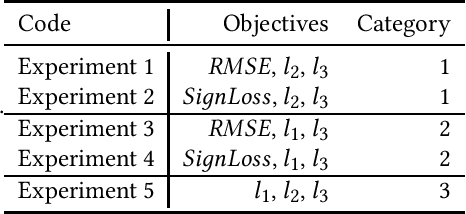
The incentive for using Evolutionary Algorithms (EAs) for the automated optimization and training of deep neural networks (DNNs), a process referred to as neuroevolution, has gained momentum in recent years. The configuration and training of these networks can be posed as optimization problems. Indeed, most of the recent works on neuroevolution have focused their attention on single-objective optimization. Moreover, from the little research that has been done at the intersection of neuroevolution and evolutionary multi-objective optimization (EMO), all the research that has been carried out has focused predominantly on the use of one type of DNN: convolutional neural networks (CNNs), using well-established standard benchmark problems such as MNIST. In this work, we make a leap in the understanding of these two areas (neuroevolution and EMO), regarded in this work as neuroevolutionary multi-objective, by using and studying a rich DNN composed of a CNN and Long-short Term Memory network. Moreover, we use a robust and challenging vehicle trajectory prediction problem. By using the well-known Non-dominated Sorting Genetic Algorithm-II, we study the effects of five different objectives, tested in categories of three, allowing us to show how these objectives have either a positive or detrimental effect in neuroevolution for trajectory prediction in autonomous vehicles.
On the Evolution of the MCTS Upper Confidence Bounds for Trees by Means of Evolutionary Algorithms in the Game of Carcassonne
Dec 17, 2021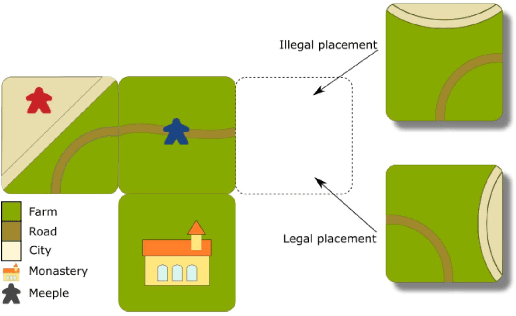
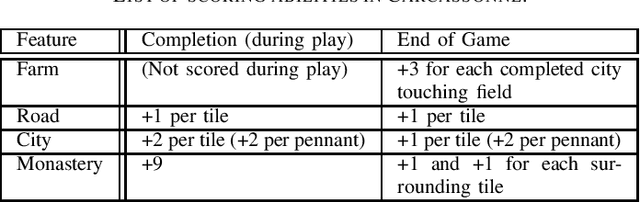
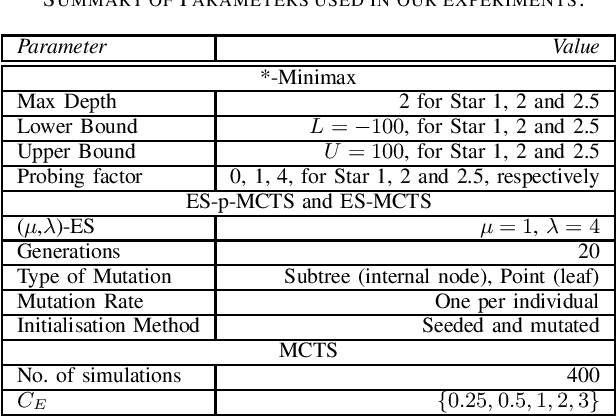
Monte Carlo Tree Search (MCTS) is a sampling best-first method to search for optimal decisions. The MCTS's popularity is based on its extraordinary results in the challenging two-player based game Go, a game considered much harder than Chess and that until very recently was considered infeasible for Artificial Intelligence methods. The success of MCTS depends heavily on how the tree is built and the selection process plays a fundamental role in this. One particular selection mechanism that has proved to be reliable is based on the Upper Confidence Bounds for Trees, commonly referred as UCT. The UCT attempts to nicely balance exploration and exploitation by considering the values stored in the statistical tree of the MCTS. However, some tuning of the MCTS UCT is necessary for this to work well. In this work, we use Evolutionary Algorithms (EAs) to evolve mathematical expressions with the goal to substitute the UCT mathematical expression. We compare our proposed approach, called Evolution Strategy in MCTS (ES-MCTS) against five variants of the MCTS UCT, three variants of the star-minimax family of algorithms as well as a random controller in the Game of Carcassonne. We also use a variant of our proposed EA-based controller, dubbed ES partially integrated in MCTS. We show how the ES-MCTS controller, is able to outperform all these 10 intelligent controllers, including robust MCTS UCT controllers.
Semantics in Multi-objective Genetic Programming
May 06, 2021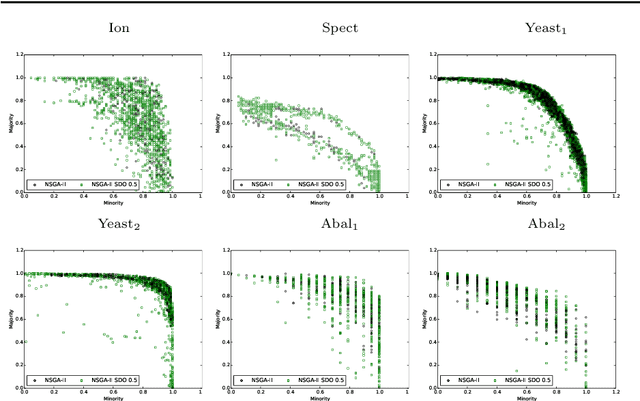
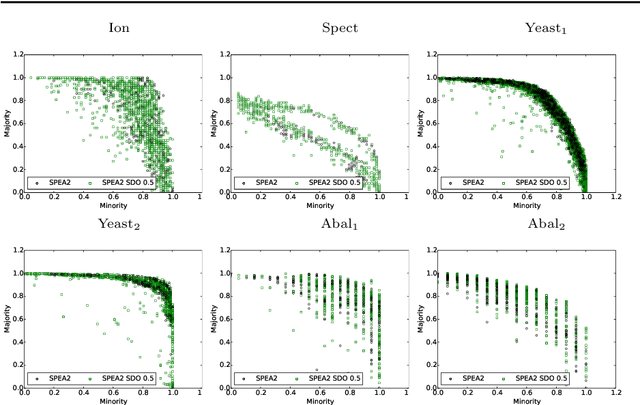
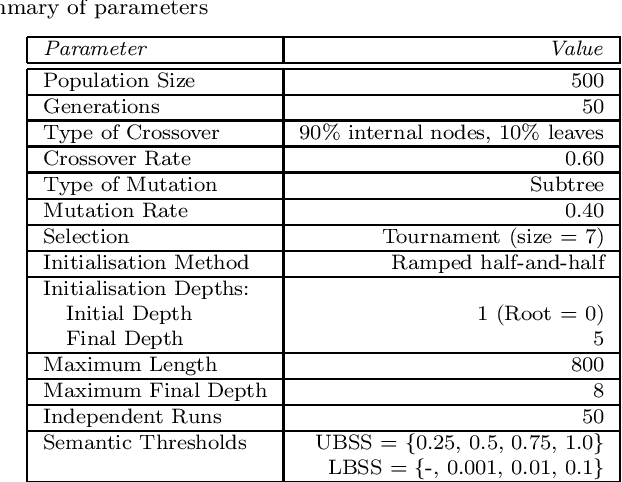
Semantics has become a key topic of research in Genetic Programming (GP). Semantics refers to the outputs (behaviour) of a GP individual when this is run on a data set. The majority of works that focus on semantic diversity in single-objective GP indicates that it is highly beneficial in evolutionary search. Surprisingly, there is minuscule research conducted in semantics in Multi-objective GP (MOGP). In this work we make a leap beyond our understanding of semantics in MOGP and propose SDO: Semantic-based Distance as an additional criteriOn. This naturally encourages semantic diversity in MOGP. To do so, we find a pivot in the less dense region of the first Pareto front (most promising front). This is then used to compute a distance between the pivot and every individual in the population. The resulting distance is then used as an additional criterion to be optimised to favour semantic diversity. We also use two other semantic-based methods as baselines, called Semantic Similarity-based Crossover and Semantic-based Crowding Distance. Furthermore, we also use the NSGA-II and the SPEA2 for comparison too. We use highly unbalanced binary classification problems and consistently show how our proposed SDO approach produces more non-dominated solutions and better diversity, leading to better statistically significant results, using the hypervolume results as evaluation measure, compared to the rest of the other four methods.