 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroLGP-SM: A Surrogate-assisted Neuroevolution Approach using Linear Genetic Programming
Mar 28, 2024
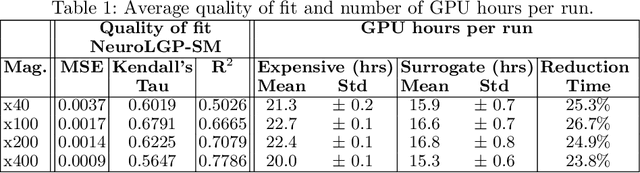
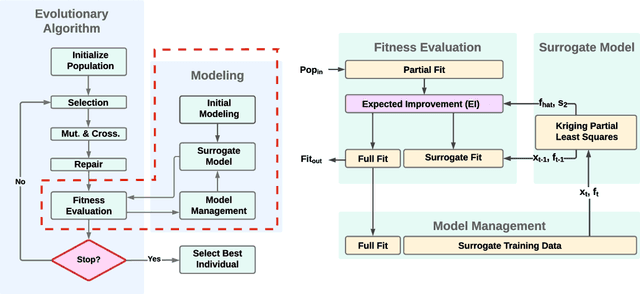
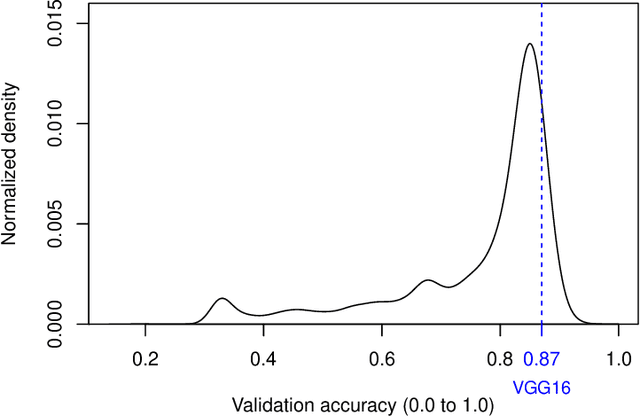
Evolutionary algorithms are increasingly recognised as a viable computational approach for the automated optimisation of deep neural networks (DNNs) within artificial intelligence. This method extends to the training of DNNs, an approach known as neuroevolution. However, neuroevolution is an inherently resource-intensive process, with certain studies reporting the consumption of thousands of GPU days for refining and training a single DNN network. To address the computational challenges associated with neuroevolution while still attaining good DNN accuracy, surrogate models emerge as a pragmatic solution. Despite their potential, the integration of surrogate models into neuroevolution is still in its early stages, hindered by factors such as the effective use of high-dimensional data and the representation employed in neuroevolution. In this context, we address these challenges by employing a suitable representation based on Linear Genetic Programming, denoted as NeuroLGP, and leveraging Kriging Partial Least Squares. The amalgamation of these two techniques culminates in our proposed methodology known as the NeuroLGP-Surrogate Model (NeuroLGP-SM). For comparison purposes, we also code and use a baseline approach incorporating a repair mechanism, a common practice in neuroevolution. Notably, the baseline approach surpasses the renowned VGG-16 model in accuracy. Given the computational intensity inherent in DNN operations, a singular run is typically the norm. To evaluate the efficacy of our proposed approach, we conducted 96 independent runs. Significantly, our methodologies consistently outperform the baseline, with the SM model demonstrating superior accuracy or comparable results to the NeuroLGP approach. Noteworthy is the additional advantage that the SM approach exhibits a 25% reduction in computational requirements, further emphasising its efficiency for neuroevolution.
Investigating the Evolvability of Web Page Load Time
Feb 22, 2018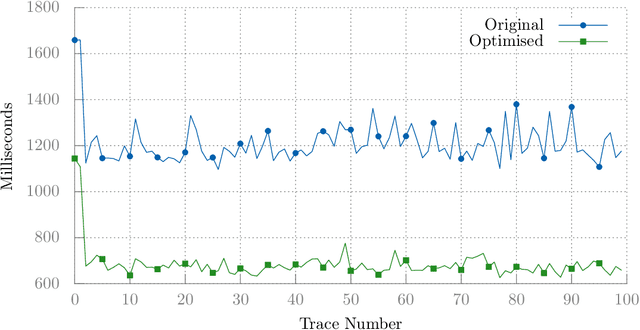
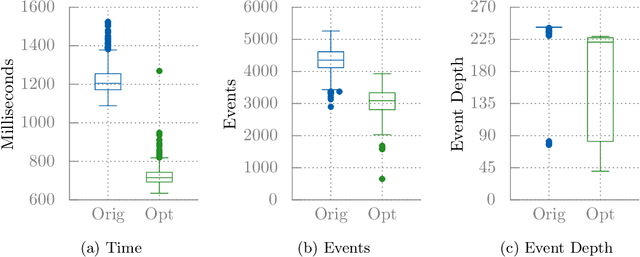
Client-side Javascript execution environments (browsers) allow anonymous functions and event-based programming concepts such as callbacks. We investigate whether a mutate-and-test approach can be used to optimise web page load time in these environments. First, we characterise a web page load issue in a benchmark web page and derive performance metrics from page load event traces. We parse Javascript source code to an AST and make changes to method calls which appear in a web page load event trace. We present an operator based solely on code deletion and evaluate an existing "community-contributed" performance optimising code transform. By exploring Javascript code changes and exploiting combinations of non-destructive changes, we can optimise page load time by 41% in our benchmark web page.
A Search for Improved Performance in Regular Expressions
Apr 13, 2017
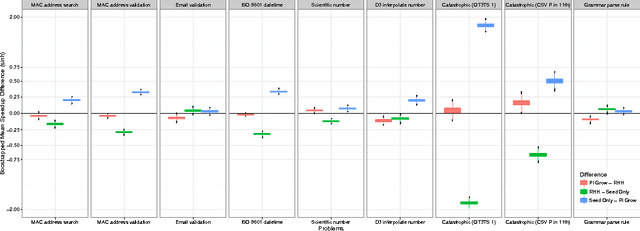


The primary aim of automated performance improvement is to reduce the running time of programs while maintaining (or improving on) functionality. In this paper, Genetic Programming is used to find performance improvements in regular expressions for an array of target programs, representing the first application of automated software improvement for run-time performance in the Regular Expression language. This particular problem is interesting as there may be many possible alternative regular expressions which perform the same task while exhibiting subtle differences in performance. A benchmark suite of candidate regular expressions is proposed for improvement. We show that the application of Genetic Programming techniques can result in performance improvements in all cases. As we start evolution from a known good regular expression, diversity is critical in escaping the local optima of the seed expression. In order to understand diversity during evolution we compare an initial population consisting of only seed programs with a population initialised using a combination of a single seed individual with individuals generated using PI Grow and Ramped-half-and-half initialisation mechanisms.
Performance Localisation
Sep 05, 2016
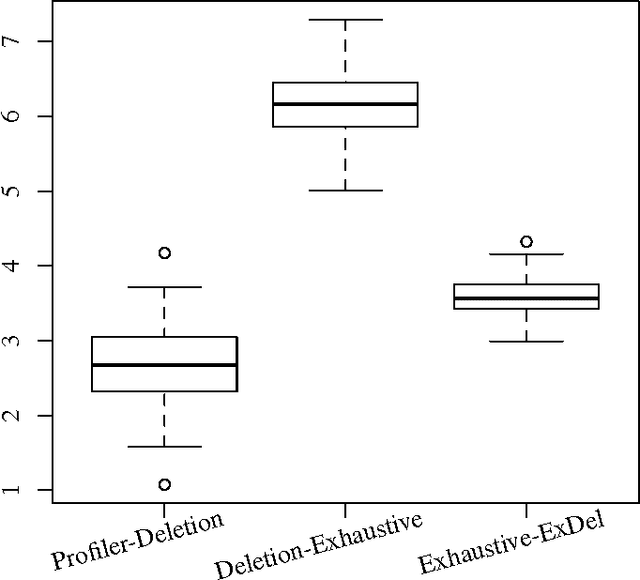


Performance becomes an issue particularly when execution cost hinders the functionality of a program. Typically a profiler can be used to find program code execution which represents a large portion of the overall execution cost of a program. Pinpointing where a performance issue exists provides a starting point for tracing cause back through a program. While profiling shows where a performance issue manifests, we use mutation analysis to show where a performance improvement is likely to exist. We find that mutation analysis can indicate locations within a program which are highly impactful to the overall execution cost of a program yet are executed relatively infrequently. By better locating potential performance improvements in programs we hope to make performance improvement more amenable to automation.
Scaling Genetic Programming for Source Code Modification
Nov 21, 2012In Search Based Software Engineering, Genetic Programming has been used for bug fixing, performance improvement and parallelisation of programs through the modification of source code. Where an evolutionary computation algorithm, such as Genetic Programming, is to be applied to similar code manipulation tasks, the complexity and size of source code for real-world software poses a scalability problem. To address this, we intend to inspect how the Software Engineering concepts of modularity, granularity and localisation of change can be reformulated as additional mechanisms within a Genetic Programming algorithm.