 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVID-19 Detection using Transfer Learning with Convolutional Neural Network
Jun 17, 2022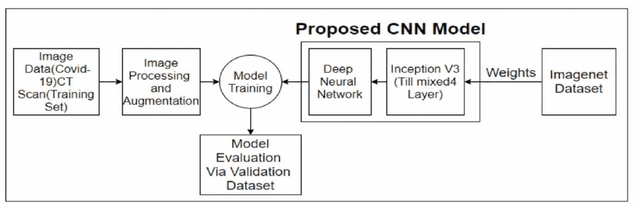
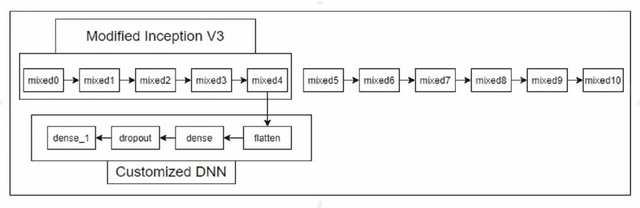
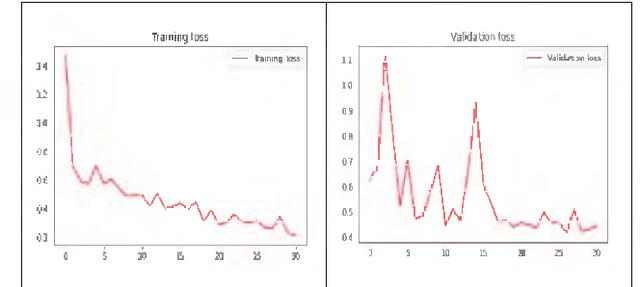
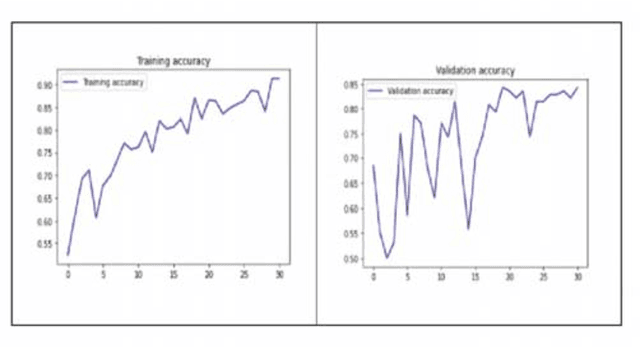
The Novel Coronavirus disease 2019 (COVID-19) is a fatal infectious disease, first recognized in December 2019 in Wuhan, Hubei, China, and has gone on an epidemic situation. Under these circumstances, it became more important to detect COVID-19 in infected people. Nowadays, the testing kits are gradually lessening in number compared to the number of infected population. Under recent prevailing conditions, the diagnosis of lung disease by analyzing chest CT (Computed Tomography) images has become an important tool for both diagnosis and prophecy of COVID-19 patients. In this study, a Transfer learning strategy (CNN) for detecting COVID-19 infection from CT images has been proposed. In the proposed model, a multilayer Convolutional neural network (CNN) with Transfer learning model Inception V3 has been designed. Similar to CNN, it uses convolution and pooling to extract features, but this transfer learning model contains weights of dataset Imagenet. Thus it can detect features very effectively which gives it an upper hand for achieving better accuracy.
* 4 pages, 4 figures, 2nd International Conference on Robotics, Electrical and Signal Processing Techniques (ICREST), DHAKA, Bangladesh
Multi-Classification of Brain Tumor Images Using Transfer Learning Based Deep Neural Network
Jun 17, 2022
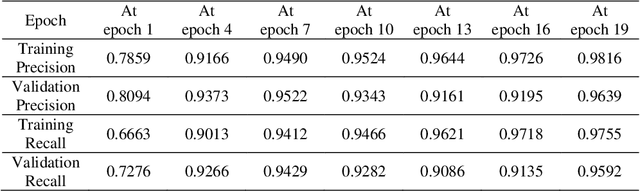
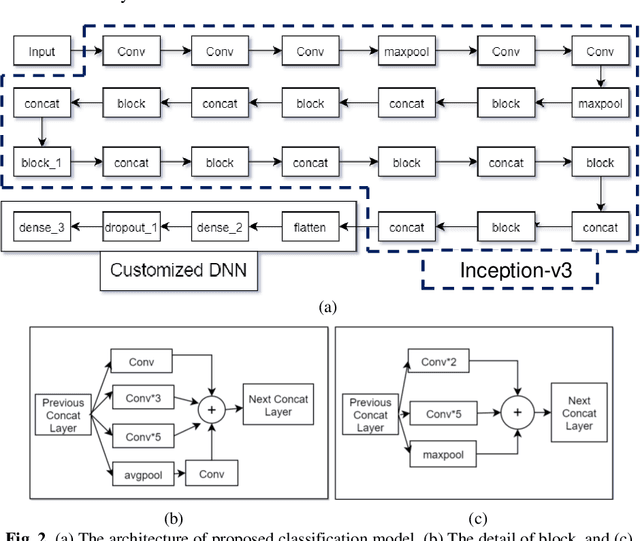

In recent advancement towards computer based diagnostics system, the classification of brain tumor images is a challenging task. This paper mainly focuses on elevating the classification accuracy of brain tumor images with transfer learning based deep neural network. The classification approach is started with the image augmentation operation including rotation, zoom, hori-zontal flip, width shift, height shift, and shear to increase the diversity in image datasets. Then the general features of the input brain tumor images are extracted based on a pre-trained transfer learning method comprised of Inception-v3. Fi-nally, the deep neural network with 4 customized layers is employed for classi-fying the brain tumors in most frequent brain tumor types as meningioma, glioma, and pituitary. The proposed model acquires an effective performance with an overall accuracy of 96.25% which is much improved than some existing multi-classification methods. Whereas, the fine-tuning of hyper-parameters and inclusion of customized DNN with the Inception-v3 model results in an im-provement of the classification accuracy.
* 7 pages, 4 figures, 2 tables, International Virtual Conference on ARTIFICIAL INTELLIGENCE FOR SMART COMMUNITY, Malaysia
ViT-BEVSeg: A Hierarchical Transformer Network for Monocular Birds-Eye-View Segmentation
May 31, 2022
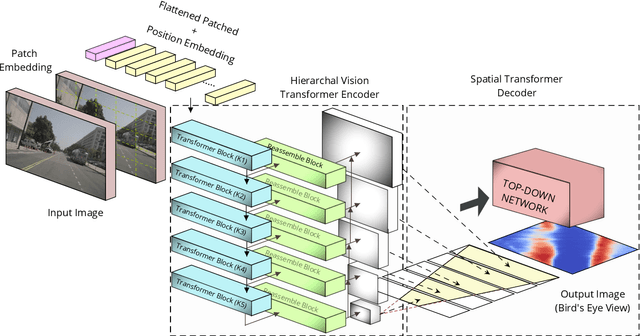

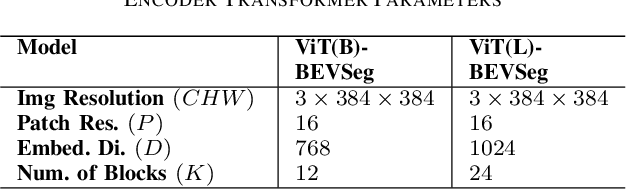
Generating a detailed near-field perceptual model of the environment is an important and challenging problem in both self-driving vehicles and autonomous mobile robotics. A Bird Eye View (BEV) map, providing a panoptic representation, is a commonly used approach that provides a simplified 2D representation of the vehicle surroundings with accurate semantic level segmentation for many downstream tasks. Current state-of-the art approaches to generate BEV-maps employ a Convolutional Neural Network (CNN) backbone to create feature-maps which are passed through a spatial transformer to project the derived features onto the BEV coordinate frame. In this paper, we evaluate the use of vision transformers (ViT) as a backbone architecture to generate BEV maps. Our network architecture, ViT-BEVSeg, employs standard vision transformers to generate a multi-scale representation of the input image. The resulting representation is then provided as an input to a spatial transformer decoder module which outputs segmentation maps in the BEV grid. We evaluate our approach on the nuScenes dataset demonstrating a considerable improvement in the performance relative to state-of-the-art approaches.