 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescriptor: Distance-Annotated Traffic Perception Question Answering (DTPQA)
Nov 17, 2025The remarkable progress of Vision-Language Models (VLMs) on a variety of tasks has raised interest in their application to automated driving. However, for these models to be trusted in such a safety-critical domain, they must first possess robust perception capabilities, i.e., they must be capable of understanding a traffic scene, which can often be highly complex, with many things happening simultaneously. Moreover, since critical objects and agents in traffic scenes are often at long distances, we require systems with not only strong perception capabilities at close distances (up to 20 meters), but also at long (30+ meters) range. Therefore, it is important to evaluate the perception capabilities of these models in isolation from other skills like reasoning or advanced world knowledge. Distance-Annotated Traffic Perception Question Answering (DTPQA) is a Visual Question Answering (VQA) benchmark designed specifically for this purpose: it can be used to evaluate the perception systems of VLMs in traffic scenarios using trivial yet crucial questions relevant to driving decisions. It consists of two parts: a synthetic benchmark (DTP-Synthetic) created using a simulator, and a real-world benchmark (DTP-Real) built on top of existing images of real traffic scenes. Additionally, DTPQA includes distance annotations, i.e., how far the object in question is from the camera. More specifically, each DTPQA sample consists of (at least): (a) an image, (b) a question, (c) the ground truth answer, and (d) the distance of the object in question, enabling analysis of how VLM performance degrades with increasing object distance. In this article, we provide the dataset itself along with the Python scripts used to create it, which can be used to generate additional data of the same kind.
Evaluating the Impact of Weather-Induced Sensor Occlusion on BEVFusion for 3D Object Detection
Nov 06, 2025Accurate 3D object detection is essential for automated vehicles to navigate safely in complex real-world environments. Bird's Eye View (BEV) representations, which project multi-sensor data into a top-down spatial format, have emerged as a powerful approach for robust perception. Although BEV-based fusion architectures have demonstrated strong performance through multimodal integration, the effects of sensor occlusions, caused by environmental conditions such as fog, haze, or physical obstructions, on 3D detection accuracy remain underexplored. In this work, we investigate the impact of occlusions on both camera and Light Detection and Ranging (LiDAR) outputs using the BEVFusion architecture, evaluated on the nuScenes dataset. Detection performance is measured using mean Average Precision (mAP) and the nuScenes Detection Score (NDS). Our results show that moderate camera occlusions lead to a 41.3% drop in mAP (from 35.6% to 20.9%) when detection is based only on the camera. On the other hand, LiDAR sharply drops in performance only under heavy occlusion, with mAP falling by 47.3% (from 64.7% to 34.1%), with a severe impact on long-range detection. In fused settings, the effect depends on which sensor is occluded: occluding the camera leads to a minor 4.1% drop (from 68.5% to 65.7%), while occluding LiDAR results in a larger 26.8% drop (to 50.1%), revealing the model's stronger reliance on LiDAR for the task of 3D object detection. Our results highlight the need for future research into occlusion-aware evaluation methods and improved sensor fusion techniques that can maintain detection accuracy in the presence of partial sensor failure or degradation due to adverse environmental conditions.
BEVMOSNet: Multimodal Fusion for BEV Moving Object Segmentation
Mar 05, 2025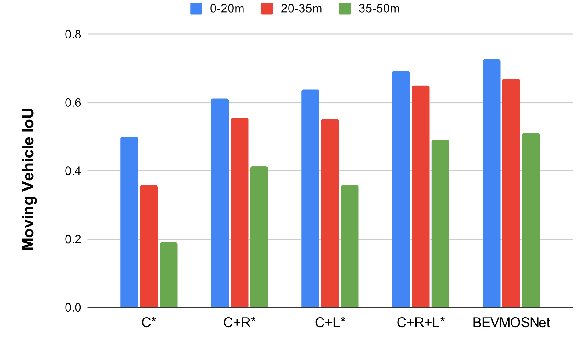
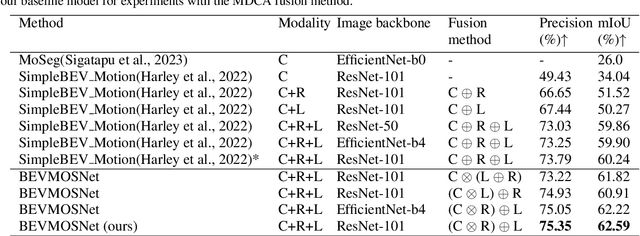
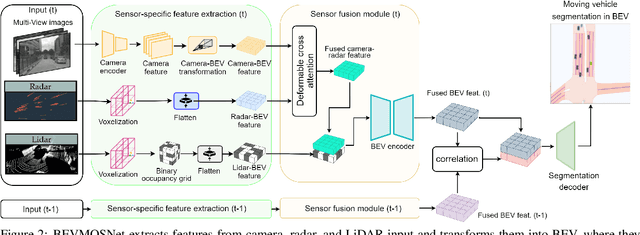
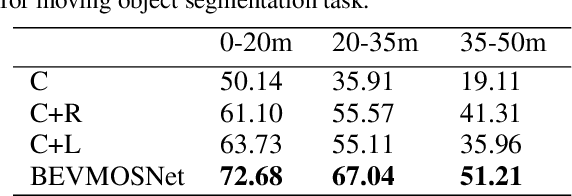
Accurate motion understanding of the dynamic objects within the scene in bird's-eye-view (BEV) is critical to ensure a reliable obstacle avoidance system and smooth path planning for autonomous vehicles. However, this task has received relatively limited exploration when compared to object detection and segmentation with only a few recent vision-based approaches presenting preliminary findings that significantly deteriorate in low-light, nighttime, and adverse weather conditions such as rain. Conversely, LiDAR and radar sensors remain almost unaffected in these scenarios, and radar provides key velocity information of the objects. Therefore, we introduce BEVMOSNet, to our knowledge, the first end-to-end multimodal fusion leveraging cameras, LiDAR, and radar to precisely predict the moving objects in BEV. In addition, we perform a deeper analysis to find out the optimal strategy for deformable cross-attention-guided sensor fusion for cross-sensor knowledge sharing in BEV. While evaluating BEVMOSNet on the nuScenes dataset, we show an overall improvement in IoU score of 36.59% compared to the vision-based unimodal baseline BEV-MoSeg (Sigatapu et al., 2023), and 2.35% compared to the multimodel SimpleBEV (Harley et al., 2022), extended for the motion segmentation task, establishing this method as the state-of-the-art in BEV motion segmentation.
Reflective Teacher: Semi-Supervised Multimodal 3D Object Detection in Bird's-Eye-View via Uncertainty Measure
Dec 05, 2024Applying pseudo labeling techniques has been found to be advantageous in semi-supervised 3D object detection (SSOD) in Bird's-Eye-View (BEV) for autonomous driving, particularly where labeled data is limited. In the literature, Exponential Moving Average (EMA) has been used for adjustments of the weights of teacher network by the student network. However, the same induces catastrophic forgetting in the teacher network. In this work, we address this issue by introducing a novel concept of Reflective Teacher where the student is trained by both labeled and pseudo labeled data while its knowledge is progressively passed to the teacher through a regularizer to ensure retention of previous knowledge. Additionally, we propose Geometry Aware BEV Fusion (GA-BEVFusion) for efficient alignment of multi-modal BEV features, thus reducing the disparity between the modalities - camera and LiDAR. This helps to map the precise geometric information embedded among LiDAR points reliably with the spatial priors for extraction of semantic information from camera images. Our experiments on the nuScenes and Waymo datasets demonstrate: 1) improved performance over state-of-the-art methods in both fully supervised and semi-supervised settings; 2) Reflective Teacher achieves equivalent performance with only 25% and 22% of labeled data for nuScenes and Waymo datasets respectively, in contrast to other fully supervised methods that utilize the full labeled dataset.
Optimizing Visual Question Answering Models for Driving: Bridging the Gap Between Human and Machine Attention Patterns
Jun 13, 2024Visual Question Answering (VQA) models play a critical role in enhancing the perception capabilities of autonomous driving systems by allowing vehicles to analyze visual inputs alongside textual queries, fostering natural interaction and trust between the vehicle and its occupants or other road users. This study investigates the attention patterns of humans compared to a VQA model when answering driving-related questions, revealing disparities in the objects observed. We propose an approach integrating filters to optimize the model's attention mechanisms, prioritizing relevant objects and improving accuracy. Utilizing the LXMERT model for a case study, we compare attention patterns of the pre-trained and Filter Integrated models, alongside human answers using images from the NuImages dataset, gaining insights into feature prioritization. We evaluated the models using a Subjective scoring framework which shows that the integration of the feature encoder filter has enhanced the performance of the VQA model by refining its attention mechanisms.
Surround-view Fisheye Camera Perception for Automated Driving: Overview, Survey and Challenges
May 26, 2022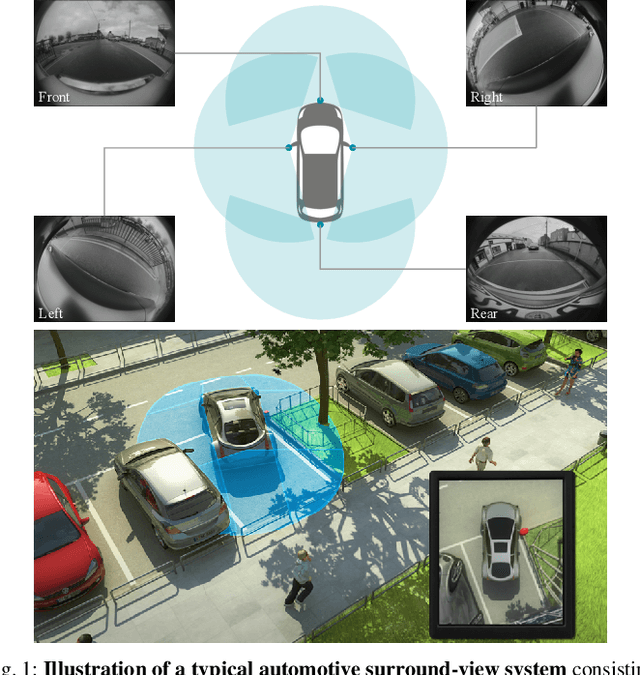
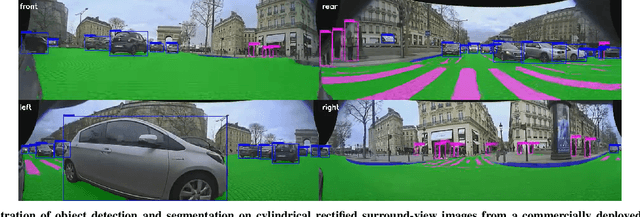

Surround-view fisheye cameras are commonly used for near-field sensing in automated driving. Four fisheye cameras on four sides of the vehicle are sufficient to cover 360{\deg} around the vehicle capturing the entire near-field region. Some primary use cases are automated parking, traffic jam assist, and urban driving. There are limited datasets and very little work on near-field perception tasks as the main focus in automotive perception is on far-field perception. In contrast to far-field, surround-view perception poses additional challenges due to high precision object detection requirements of 10cm and partial visibility of objects. Due to the large radial distortion of fisheye cameras, standard algorithms can not be extended easily to the surround-view use case. Thus we are motivated to provide a self-contained reference for automotive fisheye camera perception for researchers and practitioners. Firstly, we provide a unified and taxonomic treatment of commonly used fisheye camera models. Secondly, we discuss various perception tasks and existing literature. Finally, we discuss the challenges and future direction.
2.5D Vehicle Odometry Estimation
Nov 16, 2021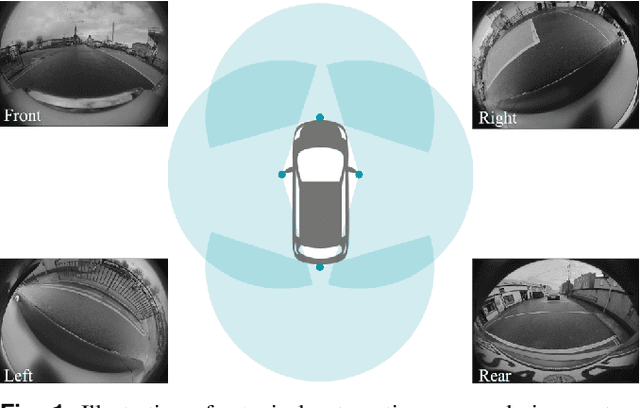

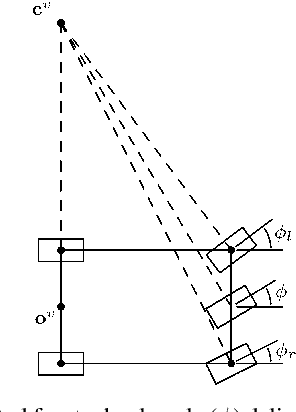
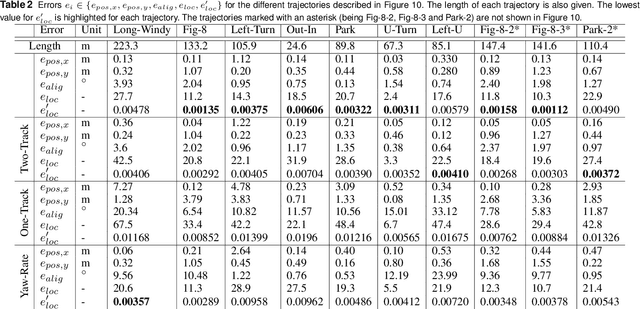
It is well understood that in ADAS applications, a good estimate of the pose of the vehicle is required. This paper proposes a metaphorically named 2.5D odometry, whereby the planar odometry derived from the yaw rate sensor and four wheel speed sensors is augmented by a linear model of suspension. While the core of the planar odometry is a yaw rate model that is already understood in the literature, we augment this by fitting a quadratic to the incoming signals, enabling interpolation, extrapolation, and a finer integration of the vehicle position. We show, by experimental results with a DGPS/IMU reference, that this model provides highly accurate odometry estimates, compared with existing methods. Utilising sensors that return the change in height of vehicle reference points with changing suspension configurations, we define a planar model of the vehicle suspension, thus augmenting the odometry model. We present an experimental framework and evaluations criteria by which the goodness of the odometry is evaluated and compared with existing methods. This odometry model has been designed to support low-speed surround-view camera systems that are well-known. Thus, we present some application results that show a performance boost for viewing and computer vision applications using the proposed odometry
* 13 pages, 16 figures, 2 tables
An Online Learning System for Wireless Charging Alignment using Surround-view Fisheye Cameras
May 26, 2021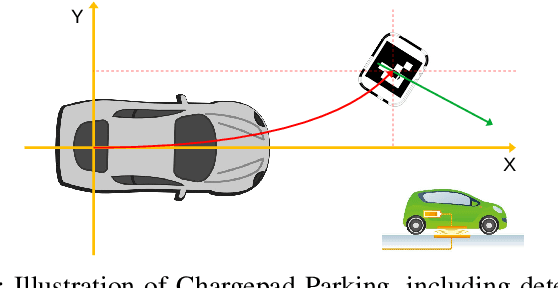

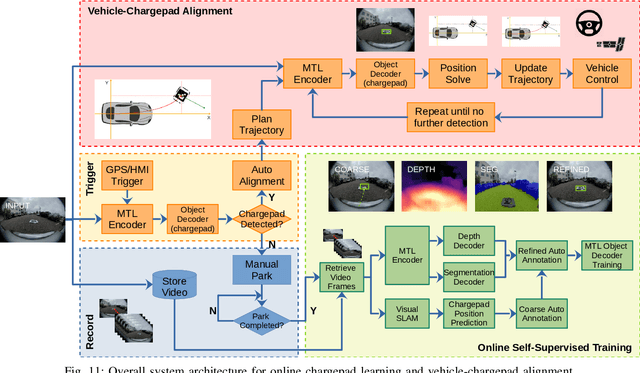

Electric Vehicles are increasingly common, with inductive chargepads being considered a convenient and efficient means of charging electric vehicles. However, drivers are typically poor at aligning the vehicle to the necessary accuracy for efficient inductive charging, making the automated alignment of the two charging plates desirable. In parallel to the electrification of the vehicular fleet, automated parking systems that make use of surround-view camera systems are becoming increasingly popular. In this work, we propose a system based on the surround-view camera architecture to detect, localize and automatically align the vehicle with the inductive chargepad. The visual design of the chargepads is not standardized and not necessarily known beforehand. Therefore a system that relies on offline training will fail in some situations. Thus we propose an online learning method that leverages the driver's actions when manually aligning the vehicle with the chargepad and combine it with weak supervision from semantic segmentation and depth to learn a classifier to auto-annotate the chargepad in the video for further training. In this way, when faced with a previously unseen chargepad, the driver needs only manually align the vehicle a single time. As the chargepad is flat on the ground, it is not easy to detect it from a distance. Thus, we propose using a Visual SLAM pipeline to learn landmarks relative to the chargepad to enable alignment from a greater range. We demonstrate the working system on an automated vehicle as illustrated in the video https://youtu.be/_cLCmkW4UYo. To encourage further research, we will share a chargepad dataset used in this work.
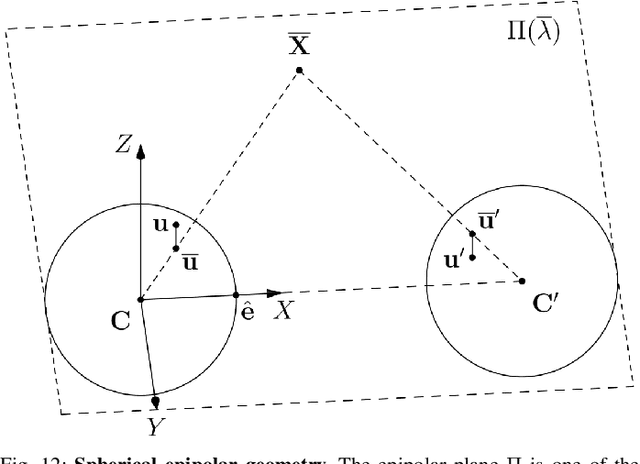
Spherical formulation of geometric motion segmentation constraints in fisheye cameras
Apr 26, 2021



We introduce a visual motion segmentation method employing spherical geometry for fisheye cameras and automoated driving. Three commonly used geometric constraints in pin-hole imagery (the positive height, positive depth and epipolar constraints) are reformulated to spherical coordinates, making them invariant to specific camera configurations as long as the camera calibration is known. A fourth constraint, known as the anti-parallel constraint, is added to resolve motion-parallax ambiguity, to support the detection of moving objects undergoing parallel or near-parallel motion with respect to the host vehicle. A final constraint constraint is described, known as the spherical three-view constraint, is described though not employed in our proposed algorithm. Results are presented and analyzed that demonstrate that the proposal is an effective motion segmentation approach for direct employment on fisheye imagery.
* arXiv admin note: text overlap with arXiv:2003.03262
Generalized Object Detection on Fisheye Cameras for Autonomous Driving: Dataset, Representations and Baseline
Dec 03, 2020
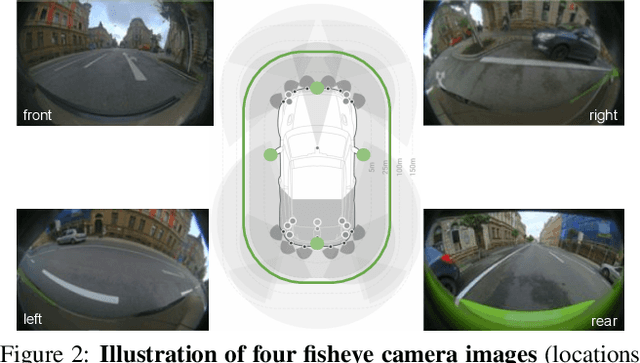
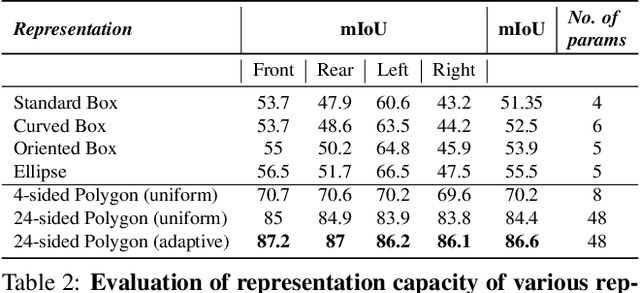
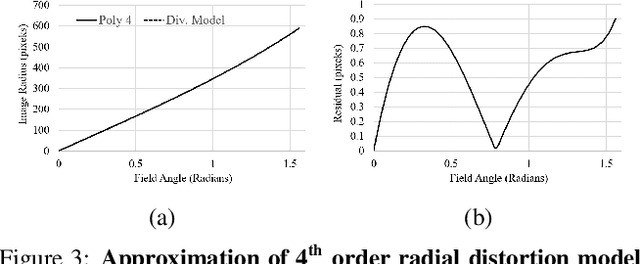
Object detection is a comprehensively studied problem in autonomous driving. However, it has been relatively less explored in the case of fisheye cameras. The standard bounding box fails in fisheye cameras due to the strong radial distortion, particularly in the image's periphery. We explore better representations like oriented bounding box, ellipse, and generic polygon for object detection in fisheye images in this work. We use the IoU metric to compare these representations using accurate instance segmentation ground truth. We design a novel curved bounding box model that has optimal properties for fisheye distortion models. We also design a curvature adaptive perimeter sampling method for obtaining polygon vertices, improving relative mAP score by 4.9% compared to uniform sampling. Overall, the proposed polygon model improves mIoU relative accuracy by 40.3%. It is the first detailed study on object detection on fisheye cameras for autonomous driving scenarios to the best of our knowledge. The dataset comprising of 10,000 images along with all the object representations ground truth will be made public to encourage further research. We summarize our work in a short video with qualitative results at https://youtu.be/iLkOzvJpL-A.