 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurround-view Fisheye Camera Perception for Automated Driving: Overview, Survey and Challenges
May 26, 2022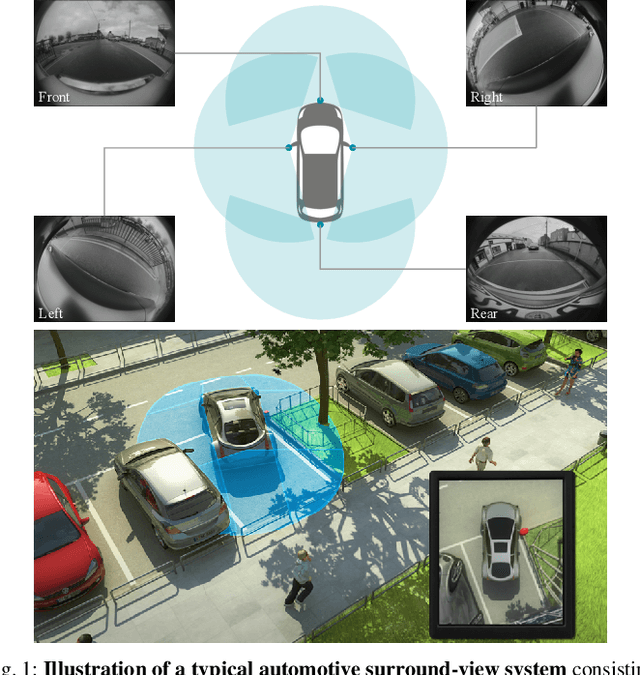

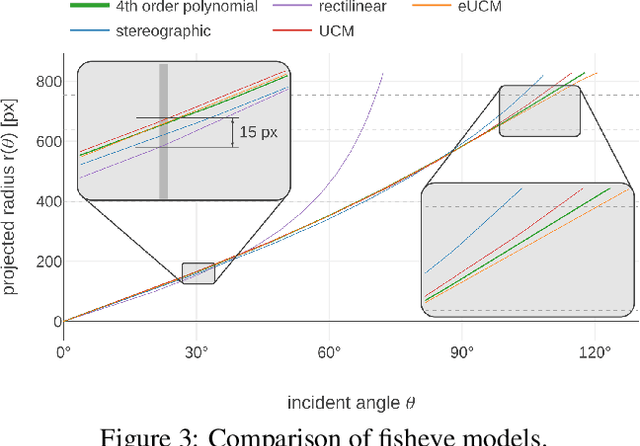
Surround-view fisheye cameras are commonly used for near-field sensing in automated driving. Four fisheye cameras on four sides of the vehicle are sufficient to cover 360{\deg} around the vehicle capturing the entire near-field region. Some primary use cases are automated parking, traffic jam assist, and urban driving. There are limited datasets and very little work on near-field perception tasks as the main focus in automotive perception is on far-field perception. In contrast to far-field, surround-view perception poses additional challenges due to high precision object detection requirements of 10cm and partial visibility of objects. Due to the large radial distortion of fisheye cameras, standard algorithms can not be extended easily to the surround-view use case. Thus we are motivated to provide a self-contained reference for automotive fisheye camera perception for researchers and practitioners. Firstly, we provide a unified and taxonomic treatment of commonly used fisheye camera models. Secondly, we discuss various perception tasks and existing literature. Finally, we discuss the challenges and future direction.
OmniDet: Surround View Cameras based Multi-task Visual Perception Network for Autonomous Driving
Feb 15, 2021
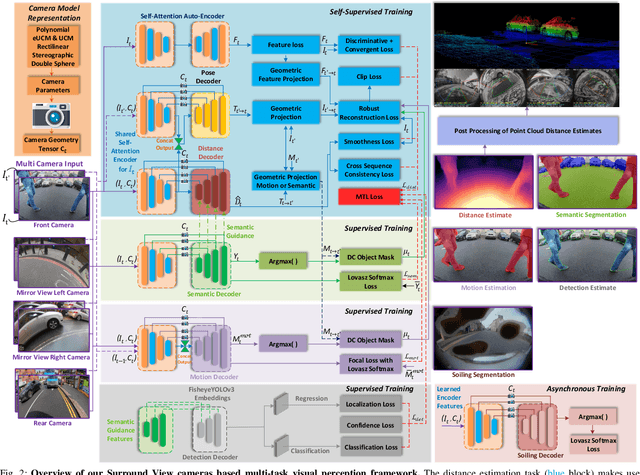
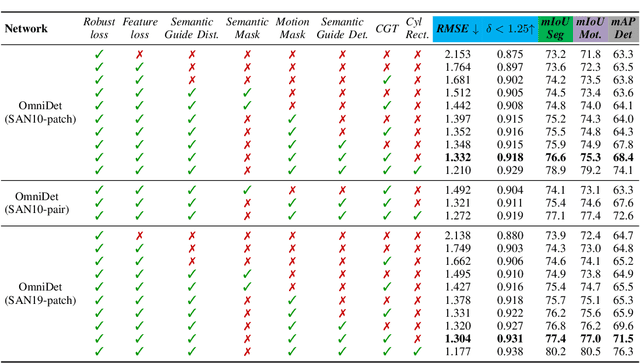
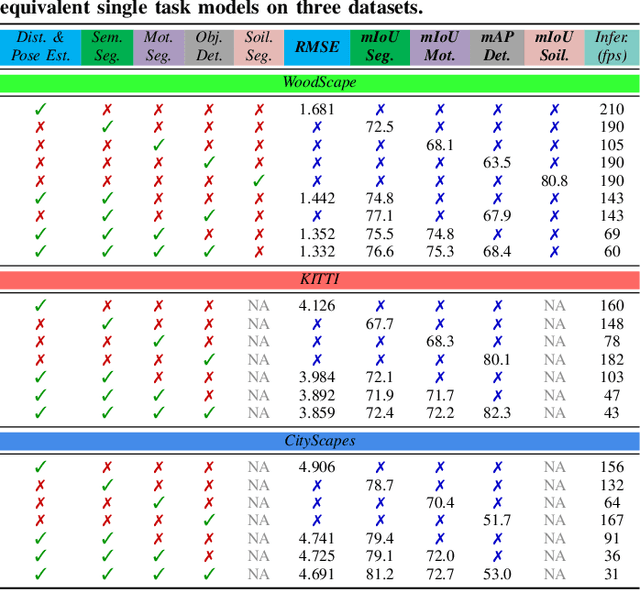
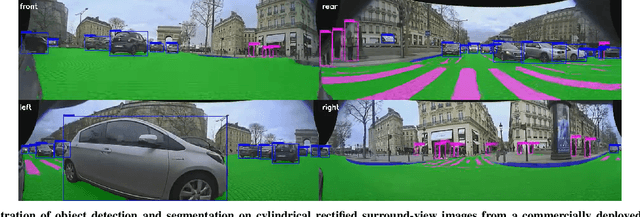
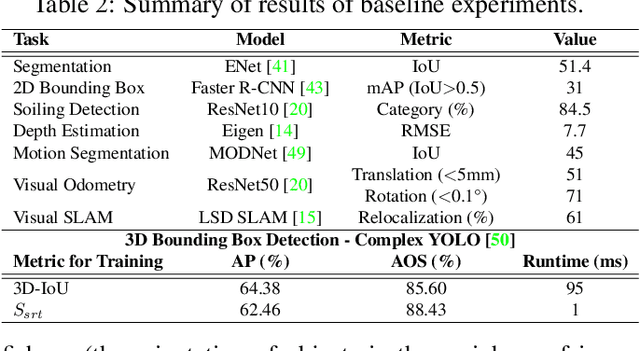
Surround View fisheye cameras are commonly deployed in automated driving for 360\deg{} near-field sensing around the vehicle. This work presents a multi-task visual perception network on unrectified fisheye images to enable the vehicle to sense its surrounding environment. It consists of six primary tasks necessary for an autonomous driving system: depth estimation, visual odometry, semantic segmentation, motion segmentation, object detection, and lens soiling detection. We demonstrate that the jointly trained model performs better than the respective single task versions. Our multi-task model has a shared encoder providing a significant computational advantage and has synergized decoders where tasks support each other. We propose a novel camera geometry based adaptation mechanism to encode the fisheye distortion model both at training and inference. This was crucial to enable training on the WoodScape dataset, comprised of data from different parts of the world collected by 12 different cameras mounted on three different cars with different intrinsics and viewpoints. Given that bounding boxes is not a good representation for distorted fisheye images, we also extend object detection to use a polygon with non-uniformly sampled vertices. We additionally evaluate our model on standard automotive datasets, namely KITTI and Cityscapes. We obtain the state-of-the-art results on KITTI for depth estimation and pose estimation tasks and competitive performance on the other tasks. We perform extensive ablation studies on various architecture choices and task weighting methodologies. A short video at https://youtu.be/xbSjZ5OfPes provides qualitative results.
UnRectDepthNet: Self-Supervised Monocular Depth Estimation using a Generic Framework for Handling Common Camera Distortion Models
Jul 26, 2020

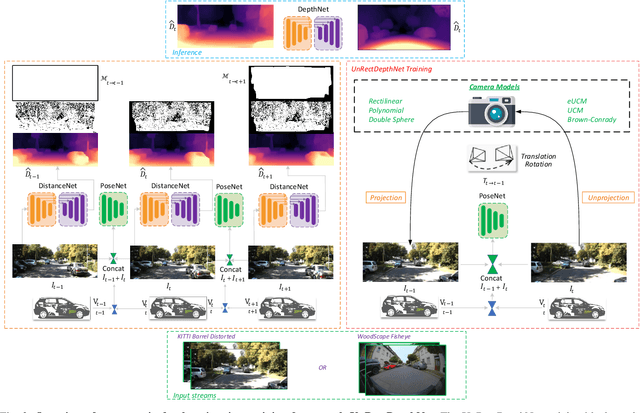

In classical computer vision, rectification is an integral part of multi-view depth estimation. It typically includes epipolar rectification and lens distortion correction. This process simplifies the depth estimation significantly, and thus it has been adopted in CNN approaches. However, rectification has several side effects, including a reduced field of view (FOV), resampling distortion, and sensitivity to calibration errors. The effects are particularly pronounced in case of significant distortion (e.g., wide-angle fisheye cameras). In this paper, we propose a generic scale-aware self-supervised pipeline for estimating depth, euclidean distance, and visual odometry from unrectified monocular videos. We demonstrate a similar level of precision on the unrectified KITTI dataset with barrel distortion comparable to the rectified KITTI dataset. The intuition being that the rectification step can be implicitly absorbed within the CNN model, which learns the distortion model without increasing complexity. Our approach does not suffer from a reduced field of view and avoids computational costs for rectification at inference time. To further illustrate the general applicability of the proposed framework, we apply it to wide-angle fisheye cameras with 190$^\circ$ horizontal field of view. The training framework UnRectDepthNet takes in the camera distortion model as an argument and adapts projection and unprojection functions accordingly. The proposed algorithm is evaluated further on the KITTI rectified dataset, and we achieve state-of-the-art results that improve upon our previous work FisheyeDistanceNet. Qualitative results on a distorted test scene video sequence indicate excellent performance https://youtu.be/K6pbx3bU4Ss.
FisheyeDistanceNet: Self-Supervised Scale-Aware Distance Estimation using Monocular Fisheye Camera for Autonomous Driving
Oct 10, 2019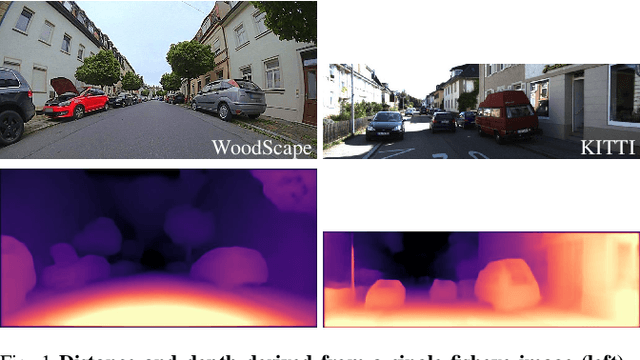



Fisheye cameras are commonly used in applications like autonomous driving and surveillance to provide a large field of view ($>180^\circ$). However, they come at the cost of strong non-linear distortion which require more complex algorithms. In this paper, we explore Euclidean distance estimation on fisheye cameras for automotive scenes. Obtaining accurate and dense depth supervision is difficult in practice, but self-supervised learning approaches show promising results and could potentially overcome the problem. We present a novel self-supervised scale-aware framework for learning Euclidean distance and ego-motion from raw monocular fisheye videos without applying rectification. While it is possible to perform piece-wise linear approximation of fisheye projection surface and apply standard rectilinear models, it has its own set of issues like re-sampling distortion and discontinuities in transition regions. To encourage further research in this area, we will release this dataset as part of our WoodScape project \cite{yogamani2019woodscape}. We further evaluated the proposed algorithm on the KITTI dataset and obtained state-of-the-art results comparable to other self-supervised monocular methods. Qualitative results on an unseen fisheye video demonstrate impressive performance, see https://youtu.be/Sgq1WzoOmXg .
WoodScape: A multi-task, multi-camera fisheye dataset for autonomous driving
May 04, 2019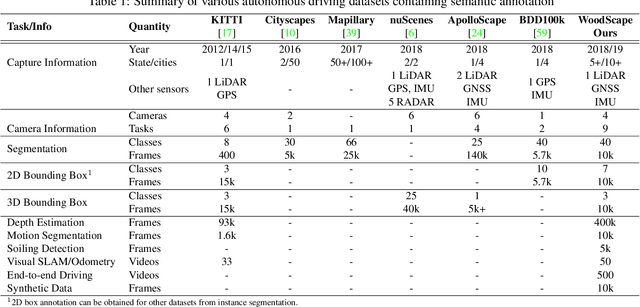
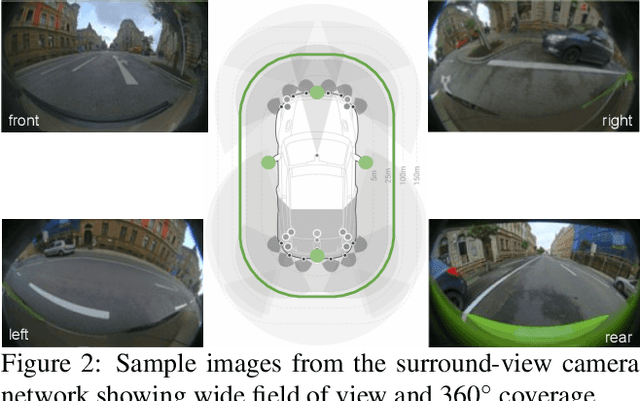
Fisheye cameras are commonly employed for obtaining a large field of view in surveillance, augmented reality and in particular automotive applications. In spite of its prevalence, there are few public datasets for detailed evaluation of computer vision algorithms on fisheye images. We release the first extensive fisheye automotive dataset, WoodScape, named after Robert Wood who invented the fisheye camera in 1906. WoodScape comprises of four surround view cameras and nine tasks including segmentation, depth estimation, 3D bounding box detection and soiling detection. Semantic annotation of 40 classes at the instance level is provided for over 10,000 images and annotation for other tasks are provided for over 100,000 images. We would like to encourage the community to adapt computer vision models for fisheye camera instead of naive rectification.
Efficient Semantic Segmentation for Visual Bird's-eye View Interpretation
Nov 29, 2018


The ability to perform semantic segmentation in real-time capable applications with limited hardware is of great importance. One such application is the interpretation of the visual bird's-eye view, which requires the semantic segmentation of the four omnidirectional camera images. In this paper, we present an efficient semantic segmentation that sets new standards in terms of runtime and hardware requirements. Our two main contributions are the decrease of the runtime by parallelizing the ArgMax layer and the reduction of hardware requirements by applying the channel pruning method to the ENet model.
Monocular Fisheye Camera Depth Estimation Using Sparse LiDAR Supervision
Sep 24, 2018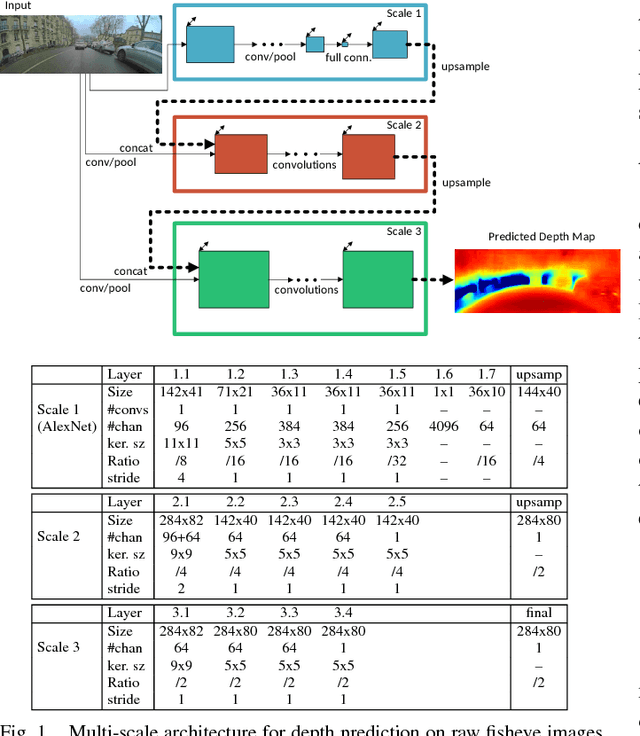

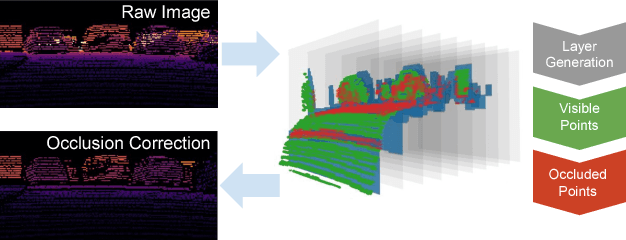

Near field depth estimation around a self driving car is an important function that can be achieved by four wide angle fisheye cameras having a field of view of over 180. Depth estimation based on convolutional neural networks (CNNs) produce state of the art results, but progress is hindered because depth annotation cannot be obtained manually. Synthetic datasets are commonly used but they have limitations. For instance, they do not capture the extensive variability in the appearance of objects like vehicles present in real datasets. There is also a domain shift while performing inference on natural images illustrated by many attempts to handle the domain adaptation explicitly. In this work, we explore an alternate approach of training using sparse LiDAR data as ground truth for depth estimation for fisheye camera. We built our own dataset using our self driving car setup which has a 64 beam Velodyne LiDAR and four wide angle fisheye cameras. To handle the difference in view points of LiDAR and fisheye camera, an occlusion resolution mechanism was implemented. We started with Eigen's multiscale convolutional network architecture and improved by modifying activation function and optimizer. We obtained promising results on our dataset with RMSE errors comparable to the state of the art results obtained on KITTI.