 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikiLi: A Spiking Simulation of LiDAR based Real-time Object Detection for Autonomous Driving
Jun 06, 2022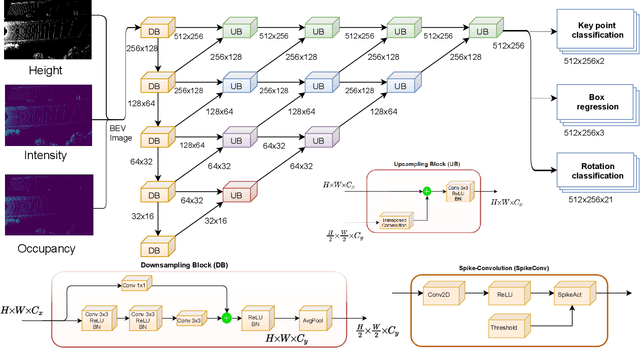
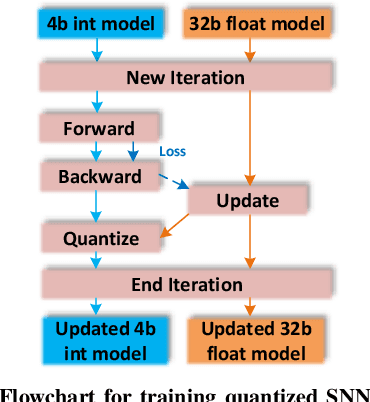
Spiking Neural Networks are a recent and new neural network design approach that promises tremendous improvements in power efficiency, computation efficiency, and processing latency. They do so by using asynchronous spike-based data flow, event-based signal generation, processing, and modifying the neuron model to resemble biological neurons closely. While some initial works have shown significant initial evidence of applicability to common deep learning tasks, their applications in complex real-world tasks has been relatively low. In this work, we first illustrate the applicability of spiking neural networks to a complex deep learning task namely Lidar based 3D object detection for automated driving. Secondly, we make a step-by-step demonstration of simulating spiking behavior using a pre-trained convolutional neural network. We closely model essential aspects of spiking neural networks in simulation and achieve equivalent run-time and accuracy on a GPU. When the model is realized on a neuromorphic hardware, we expect to have significantly improved power efficiency.
BEVDetNet: Bird's Eye View LiDAR Point Cloud based Real-time 3D Object Detection for Autonomous Driving
Apr 21, 2021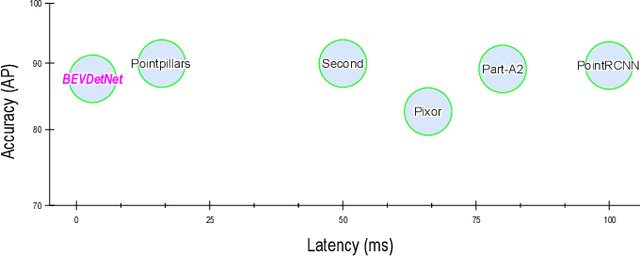
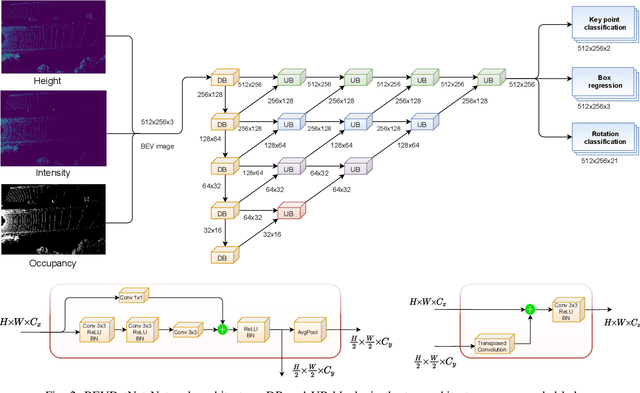

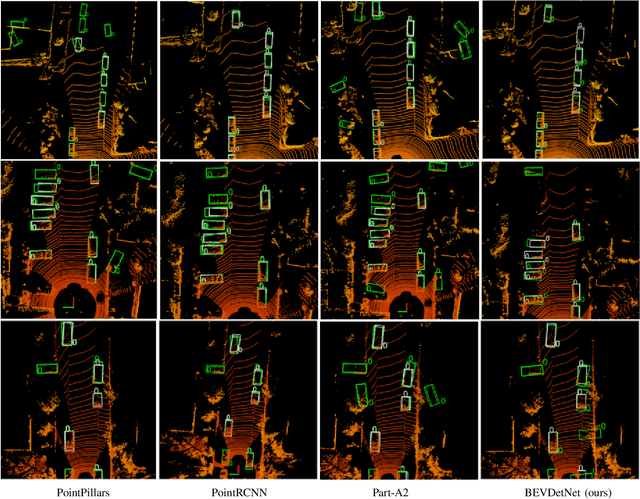
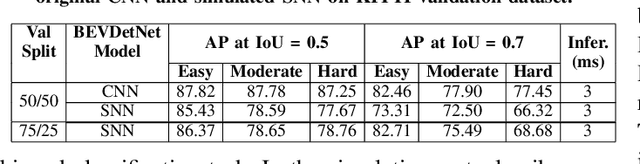
LiDAR based 3D object detection is a crucial module in autonomous driving particularly for long range sensing. Most of the research is focused on achieving higher accuracy and these models are not optimized for deployment on embedded systems from the perspective of latency and power efficiency. For high speed driving scenarios, latency is a crucial parameter as it provides more time to react to dangerous situations. Typically a voxel or point-cloud based 3D convolution approach is utilized for this module. Firstly, they are inefficient on embedded platforms as they are not suitable for efficient parallelization. Secondly, they have a variable runtime due to level of sparsity of the scene which is against the determinism needed in a safety system. In this work, we aim to develop a very low latency algorithm with fixed runtime. We propose a novel semantic segmentation architecture as a single unified model for object center detection using key points, box predictions and orientation prediction using binned classification in a simpler Bird's Eye View (BEV) 2D representation. The proposed architecture can be trivially extended to include semantic segmentation classes like road without any additional computation. The proposed model has a latency of 4 ms on the embedded Nvidia Xavier platform. The model is 5X faster than other top accuracy models with a minimal accuracy degradation of 2% in Average Precision at IoU=0.5 on KITTI dataset.
UnRectDepthNet: Self-Supervised Monocular Depth Estimation using a Generic Framework for Handling Common Camera Distortion Models
Jul 26, 2020

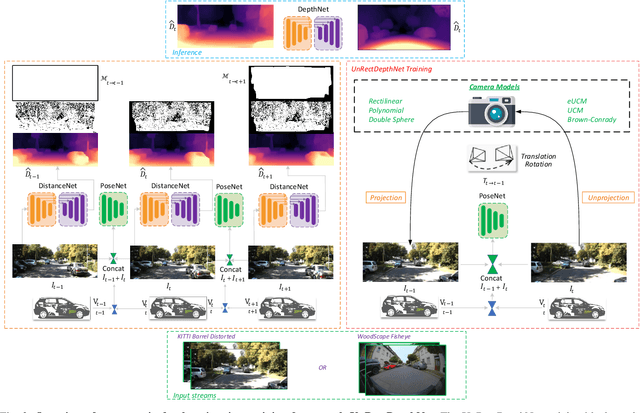

In classical computer vision, rectification is an integral part of multi-view depth estimation. It typically includes epipolar rectification and lens distortion correction. This process simplifies the depth estimation significantly, and thus it has been adopted in CNN approaches. However, rectification has several side effects, including a reduced field of view (FOV), resampling distortion, and sensitivity to calibration errors. The effects are particularly pronounced in case of significant distortion (e.g., wide-angle fisheye cameras). In this paper, we propose a generic scale-aware self-supervised pipeline for estimating depth, euclidean distance, and visual odometry from unrectified monocular videos. We demonstrate a similar level of precision on the unrectified KITTI dataset with barrel distortion comparable to the rectified KITTI dataset. The intuition being that the rectification step can be implicitly absorbed within the CNN model, which learns the distortion model without increasing complexity. Our approach does not suffer from a reduced field of view and avoids computational costs for rectification at inference time. To further illustrate the general applicability of the proposed framework, we apply it to wide-angle fisheye cameras with 190$^\circ$ horizontal field of view. The training framework UnRectDepthNet takes in the camera distortion model as an argument and adapts projection and unprojection functions accordingly. The proposed algorithm is evaluated further on the KITTI rectified dataset, and we achieve state-of-the-art results that improve upon our previous work FisheyeDistanceNet. Qualitative results on a distorted test scene video sequence indicate excellent performance https://youtu.be/K6pbx3bU4Ss.
FisheyeDistanceNet: Self-Supervised Scale-Aware Distance Estimation using Monocular Fisheye Camera for Autonomous Driving
Oct 10, 2019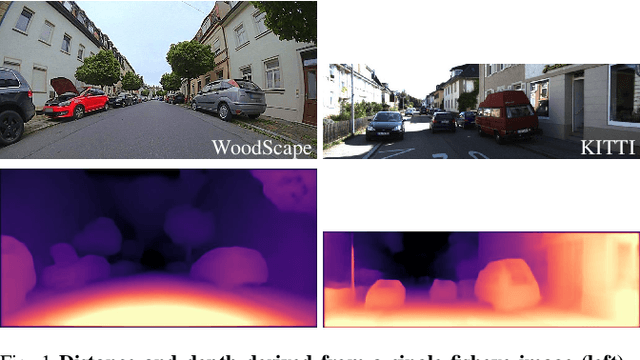



Fisheye cameras are commonly used in applications like autonomous driving and surveillance to provide a large field of view ($>180^\circ$). However, they come at the cost of strong non-linear distortion which require more complex algorithms. In this paper, we explore Euclidean distance estimation on fisheye cameras for automotive scenes. Obtaining accurate and dense depth supervision is difficult in practice, but self-supervised learning approaches show promising results and could potentially overcome the problem. We present a novel self-supervised scale-aware framework for learning Euclidean distance and ego-motion from raw monocular fisheye videos without applying rectification. While it is possible to perform piece-wise linear approximation of fisheye projection surface and apply standard rectilinear models, it has its own set of issues like re-sampling distortion and discontinuities in transition regions. To encourage further research in this area, we will release this dataset as part of our WoodScape project \cite{yogamani2019woodscape}. We further evaluated the proposed algorithm on the KITTI dataset and obtained state-of-the-art results comparable to other self-supervised monocular methods. Qualitative results on an unseen fisheye video demonstrate impressive performance, see https://youtu.be/Sgq1WzoOmXg .