 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVDistNet: Self-Supervised Near-Field Distance Estimation on Surround View Fisheye Cameras
Apr 09, 2021
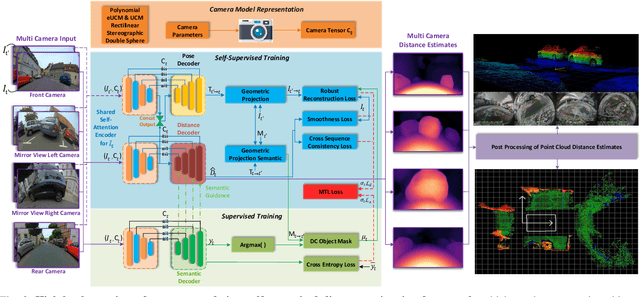
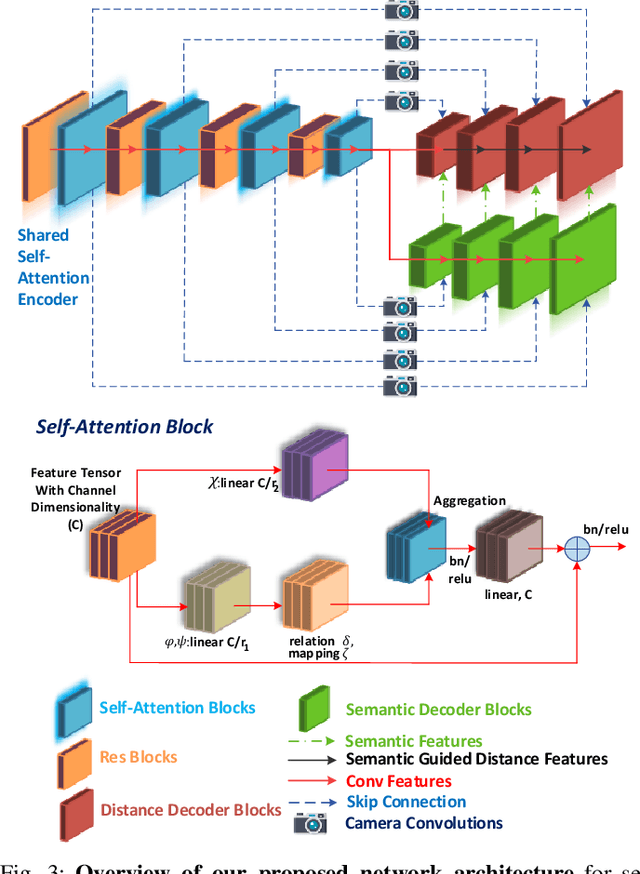

A 360{\deg} perception of scene geometry is essential for automated driving, notably for parking and urban driving scenarios. Typically, it is achieved using surround-view fisheye cameras, focusing on the near-field area around the vehicle. The majority of current depth estimation approaches focus on employing just a single camera, which cannot be straightforwardly generalized to multiple cameras. The depth estimation model must be tested on a variety of cameras equipped to millions of cars with varying camera geometries. Even within a single car, intrinsics vary due to manufacturing tolerances. Deep learning models are sensitive to these changes, and it is practically infeasible to train and test on each camera variant. As a result, we present novel camera-geometry adaptive multi-scale convolutions which utilize the camera parameters as a conditional input, enabling the model to generalize to previously unseen fisheye cameras. Additionally, we improve the distance estimation by pairwise and patchwise vector-based self-attention encoder networks. We evaluate our approach on the Fisheye WoodScape surround-view dataset, significantly improving over previous approaches. We also show a generalization of our approach across different camera viewing angles and perform extensive experiments to support our contributions. To enable comparison with other approaches, we evaluate the front camera data on the KITTI dataset (pinhole camera images) and achieve state-of-the-art performance among self-supervised monocular methods. An overview video with qualitative results is provided at https://youtu.be/bmX0UcU9wtA. Baseline code and dataset will be made public.
UnRectDepthNet: Self-Supervised Monocular Depth Estimation using a Generic Framework for Handling Common Camera Distortion Models
Jul 26, 2020

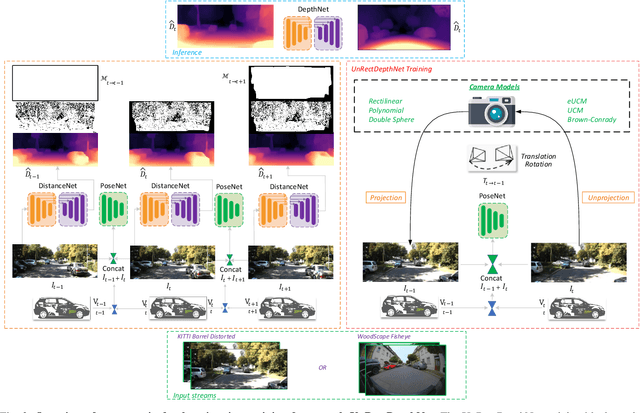

In classical computer vision, rectification is an integral part of multi-view depth estimation. It typically includes epipolar rectification and lens distortion correction. This process simplifies the depth estimation significantly, and thus it has been adopted in CNN approaches. However, rectification has several side effects, including a reduced field of view (FOV), resampling distortion, and sensitivity to calibration errors. The effects are particularly pronounced in case of significant distortion (e.g., wide-angle fisheye cameras). In this paper, we propose a generic scale-aware self-supervised pipeline for estimating depth, euclidean distance, and visual odometry from unrectified monocular videos. We demonstrate a similar level of precision on the unrectified KITTI dataset with barrel distortion comparable to the rectified KITTI dataset. The intuition being that the rectification step can be implicitly absorbed within the CNN model, which learns the distortion model without increasing complexity. Our approach does not suffer from a reduced field of view and avoids computational costs for rectification at inference time. To further illustrate the general applicability of the proposed framework, we apply it to wide-angle fisheye cameras with 190$^\circ$ horizontal field of view. The training framework UnRectDepthNet takes in the camera distortion model as an argument and adapts projection and unprojection functions accordingly. The proposed algorithm is evaluated further on the KITTI rectified dataset, and we achieve state-of-the-art results that improve upon our previous work FisheyeDistanceNet. Qualitative results on a distorted test scene video sequence indicate excellent performance https://youtu.be/K6pbx3bU4Ss.