 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDAR-BEVMTN: Real-Time LiDAR Bird's-Eye View Multi-Task Perception Network for Autonomous Driving
Jul 17, 2023



LiDAR is crucial for robust 3D scene perception in autonomous driving. LiDAR perception has the largest body of literature after camera perception. However, multi-task learning across tasks like detection, segmentation, and motion estimation using LiDAR remains relatively unexplored, especially on automotive-grade embedded platforms. We present a real-time multi-task convolutional neural network for LiDAR-based object detection, semantics, and motion segmentation. The unified architecture comprises a shared encoder and task-specific decoders, enabling joint representation learning. We propose a novel Semantic Weighting and Guidance (SWAG) module to transfer semantic features for improved object detection selectively. Our heterogeneous training scheme combines diverse datasets and exploits complementary cues between tasks. The work provides the first embedded implementation unifying these key perception tasks from LiDAR point clouds achieving 3ms latency on the embedded NVIDIA Xavier platform. We achieve state-of-the-art results for two tasks, semantic and motion segmentation, and close to state-of-the-art performance for 3D object detection. By maximizing hardware efficiency and leveraging multi-task synergies, our method delivers an accurate and efficient solution tailored for real-world automated driving deployment. Qualitative results can be seen at https://youtu.be/H-hWRzv2lIY.
Near Field iToF LIDAR Depth Improvement from Limited Number of Shots
Apr 14, 2023Indirect Time of Flight LiDARs can indirectly calculate the scene's depth from the phase shift angle between transmitted and received laser signals with amplitudes modulated at a predefined frequency. Unfortunately, this method generates ambiguity in calculated depth when the phase shift angle value exceeds $2\pi$. Current state-of-the-art methods use raw samples generated using two distinct modulation frequencies to overcome this ambiguity problem. However, this comes at the cost of increasing laser components' stress and raising their temperature, which reduces their lifetime and increases power consumption. In our work, we study two different methods to recover the entire depth range of the LiDAR using fewer raw data sample shots from a single modulation frequency with the support of sensor's gray scale output to reduce the laser components' stress and power consumption.
SpikiLi: A Spiking Simulation of LiDAR based Real-time Object Detection for Autonomous Driving
Jun 06, 2022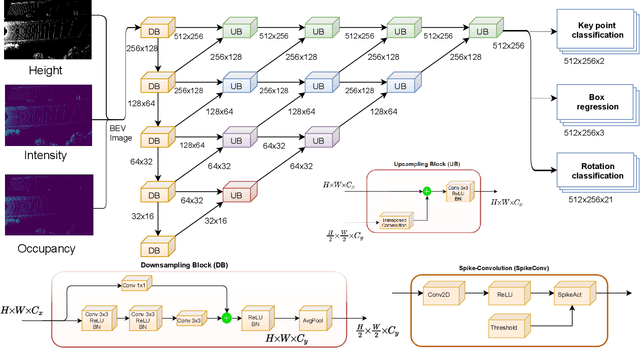
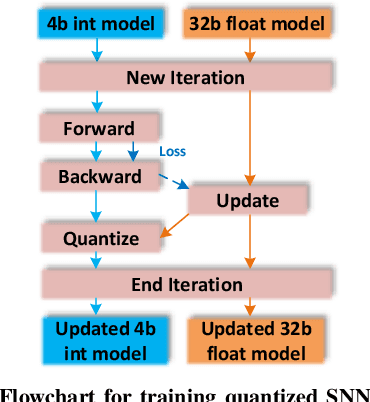
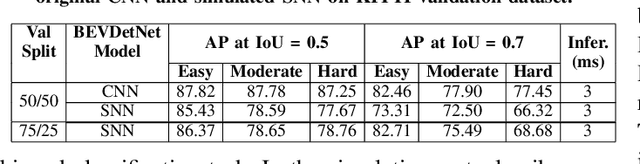
Spiking Neural Networks are a recent and new neural network design approach that promises tremendous improvements in power efficiency, computation efficiency, and processing latency. They do so by using asynchronous spike-based data flow, event-based signal generation, processing, and modifying the neuron model to resemble biological neurons closely. While some initial works have shown significant initial evidence of applicability to common deep learning tasks, their applications in complex real-world tasks has been relatively low. In this work, we first illustrate the applicability of spiking neural networks to a complex deep learning task namely Lidar based 3D object detection for automated driving. Secondly, we make a step-by-step demonstration of simulating spiking behavior using a pre-trained convolutional neural network. We closely model essential aspects of spiking neural networks in simulation and achieve equivalent run-time and accuracy on a GPU. When the model is realized on a neuromorphic hardware, we expect to have significantly improved power efficiency.
A deep learning approach for direction of arrival estimation using automotive-grade ultrasonic sensors
Feb 25, 2022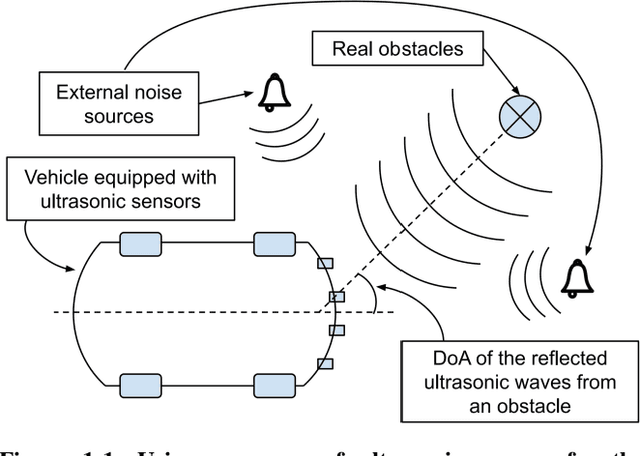
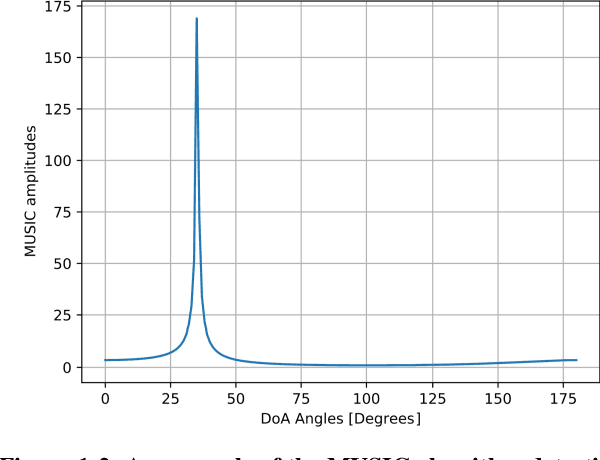
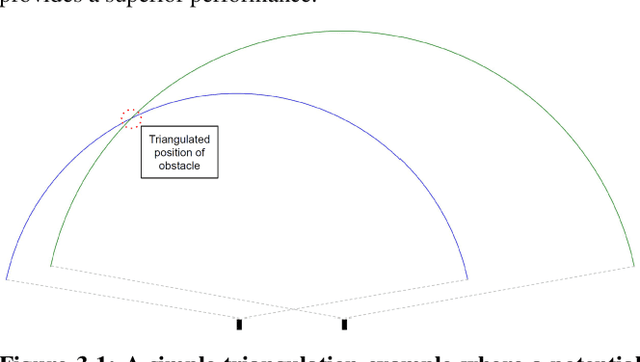
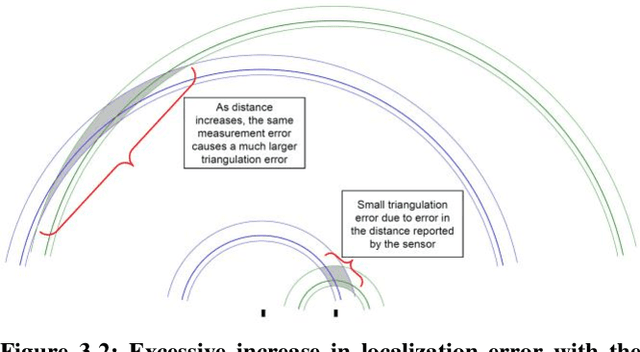
In this paper, a deep learning approach is presented for direction of arrival estimation using automotive-grade ultrasonic sensors which are used for driving assistance systems such as automatic parking. A study and implementation of the state of the art deterministic direction of arrival estimation algorithms is used as a benchmark for the performance of the proposed approach. Analysis of the performance of the proposed algorithms against the existing algorithms is carried out over simulation data as well as data from a measurement campaign done using automotive-grade ultrasonic sensors. Both sets of results clearly show the superiority of the proposed approach under realistic conditions such as noise from the environment as well as eventual errors in measurements. It is demonstrated as well how the proposed approach can overcome some of the known limitations of the existing algorithms such as precision dilution of triangulation and aliasing.
LiMoSeg: Real-time Bird's Eye View based LiDAR Motion Segmentation
Nov 08, 2021

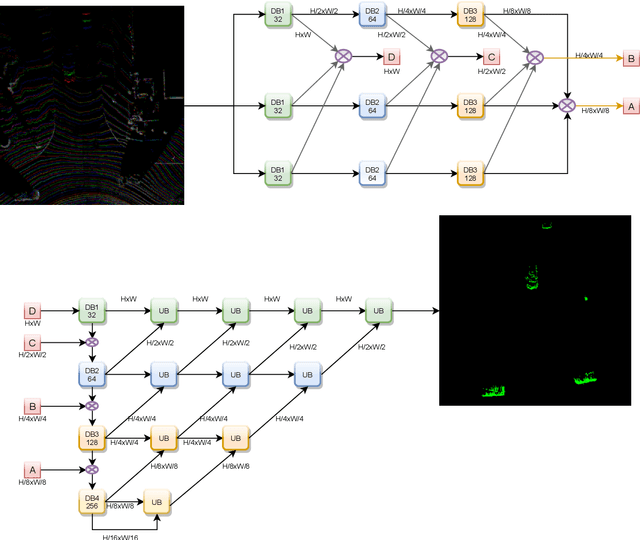

Moving object detection and segmentation is an essential task in the Autonomous Driving pipeline. Detecting and isolating static and moving components of a vehicle's surroundings are particularly crucial in path planning and localization tasks. This paper proposes a novel real-time architecture for motion segmentation of Light Detection and Ranging (LiDAR) data. We use two successive scans of LiDAR data in 2D Bird's Eye View (BEV) representation to perform pixel-wise classification as static or moving. Furthermore, we propose a novel data augmentation technique to reduce the significant class imbalance between static and moving objects. We achieve this by artificially synthesizing moving objects by cutting and pasting static vehicles. We demonstrate a low latency of 8 ms on a commonly used automotive embedded platform, namely Nvidia Jetson Xavier. To the best of our knowledge, this is the first work directly performing motion segmentation in LiDAR BEV space. We provide quantitative results on the challenging SemanticKITTI dataset, and qualitative results are provided in https://youtu.be/2aJ-cL8b0LI.
BEVDetNet: Bird's Eye View LiDAR Point Cloud based Real-time 3D Object Detection for Autonomous Driving
Apr 21, 2021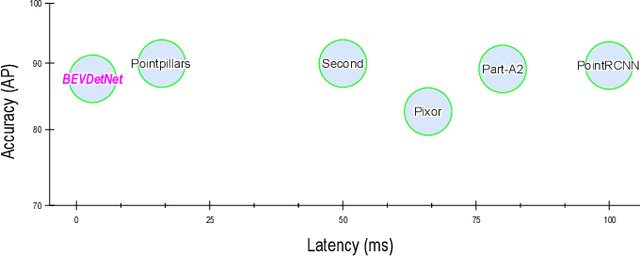
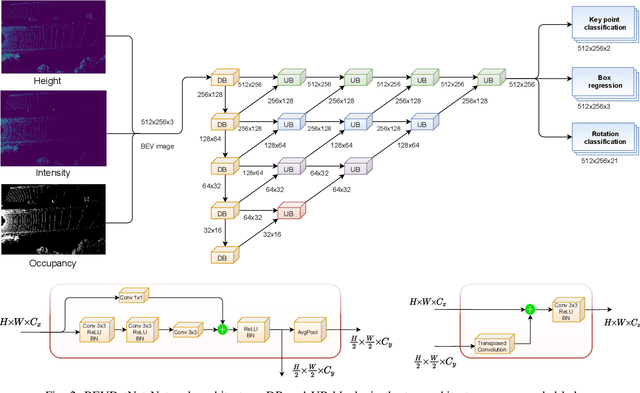

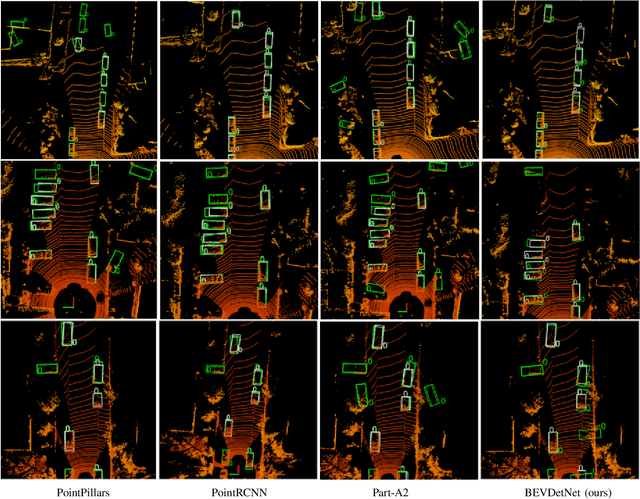
LiDAR based 3D object detection is a crucial module in autonomous driving particularly for long range sensing. Most of the research is focused on achieving higher accuracy and these models are not optimized for deployment on embedded systems from the perspective of latency and power efficiency. For high speed driving scenarios, latency is a crucial parameter as it provides more time to react to dangerous situations. Typically a voxel or point-cloud based 3D convolution approach is utilized for this module. Firstly, they are inefficient on embedded platforms as they are not suitable for efficient parallelization. Secondly, they have a variable runtime due to level of sparsity of the scene which is against the determinism needed in a safety system. In this work, we aim to develop a very low latency algorithm with fixed runtime. We propose a novel semantic segmentation architecture as a single unified model for object center detection using key points, box predictions and orientation prediction using binned classification in a simpler Bird's Eye View (BEV) 2D representation. The proposed architecture can be trivially extended to include semantic segmentation classes like road without any additional computation. The proposed model has a latency of 4 ms on the embedded Nvidia Xavier platform. The model is 5X faster than other top accuracy models with a minimal accuracy degradation of 2% in Average Precision at IoU=0.5 on KITTI dataset.