 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA deep learning approach for direction of arrival estimation using automotive-grade ultrasonic sensors
Feb 25, 2022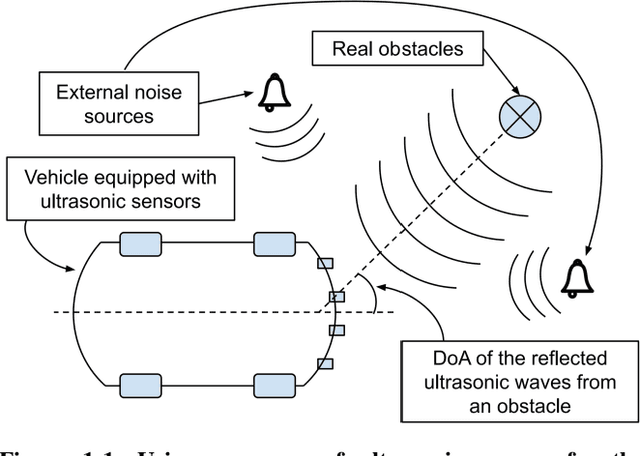
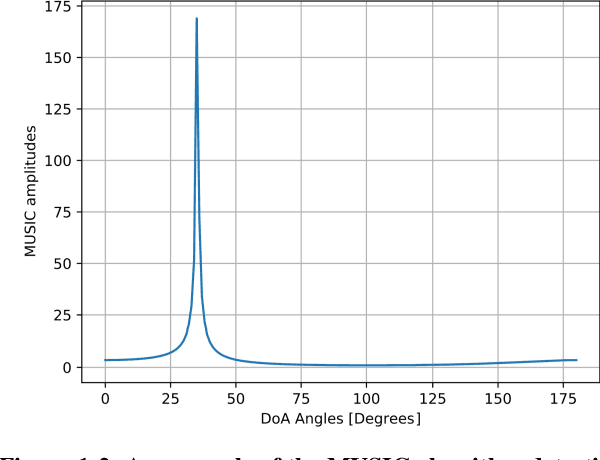
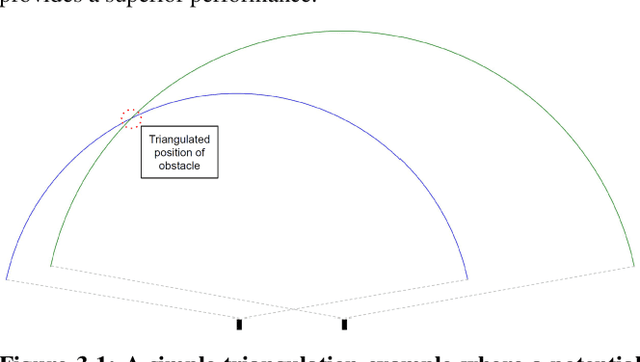
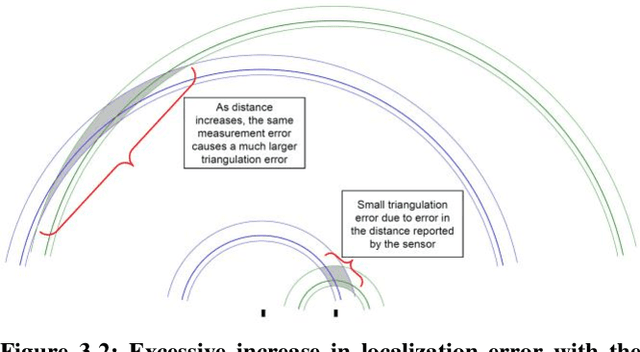
In this paper, a deep learning approach is presented for direction of arrival estimation using automotive-grade ultrasonic sensors which are used for driving assistance systems such as automatic parking. A study and implementation of the state of the art deterministic direction of arrival estimation algorithms is used as a benchmark for the performance of the proposed approach. Analysis of the performance of the proposed algorithms against the existing algorithms is carried out over simulation data as well as data from a measurement campaign done using automotive-grade ultrasonic sensors. Both sets of results clearly show the superiority of the proposed approach under realistic conditions such as noise from the environment as well as eventual errors in measurements. It is demonstrated as well how the proposed approach can overcome some of the known limitations of the existing algorithms such as precision dilution of triangulation and aliasing.
LiMoSeg: Real-time Bird's Eye View based LiDAR Motion Segmentation
Nov 08, 2021


Moving object detection and segmentation is an essential task in the Autonomous Driving pipeline. Detecting and isolating static and moving components of a vehicle's surroundings are particularly crucial in path planning and localization tasks. This paper proposes a novel real-time architecture for motion segmentation of Light Detection and Ranging (LiDAR) data. We use two successive scans of LiDAR data in 2D Bird's Eye View (BEV) representation to perform pixel-wise classification as static or moving. Furthermore, we propose a novel data augmentation technique to reduce the significant class imbalance between static and moving objects. We achieve this by artificially synthesizing moving objects by cutting and pasting static vehicles. We demonstrate a low latency of 8 ms on a commonly used automotive embedded platform, namely Nvidia Jetson Xavier. To the best of our knowledge, this is the first work directly performing motion segmentation in LiDAR BEV space. We provide quantitative results on the challenging SemanticKITTI dataset, and qualitative results are provided in https://youtu.be/2aJ-cL8b0LI.
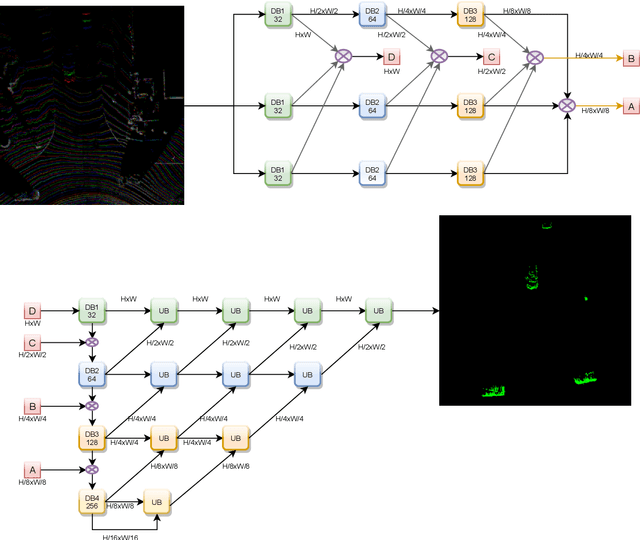
SynDistNet: Self-Supervised Monocular Fisheye Camera Distance Estimation Synergized with Semantic Segmentation for Autonomous Driving
Aug 10, 2020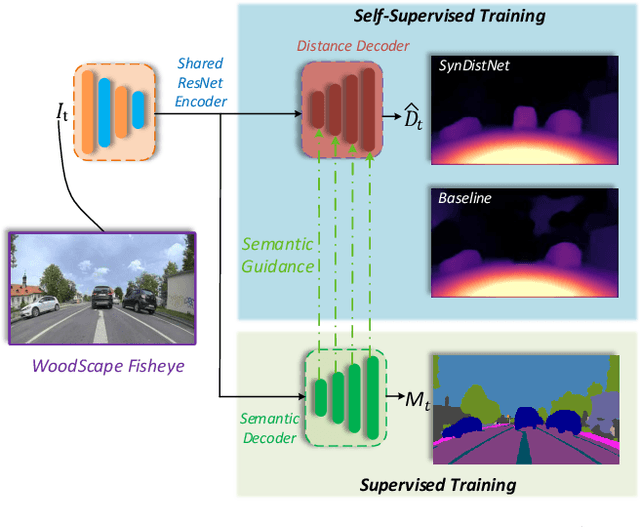
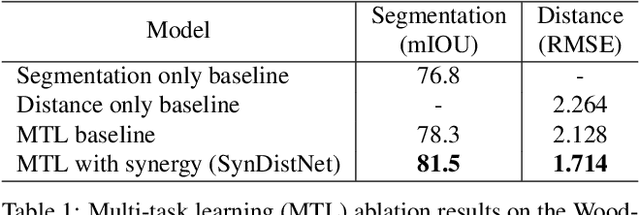
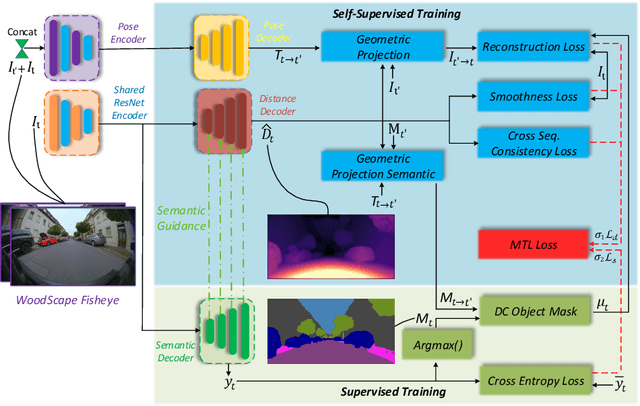
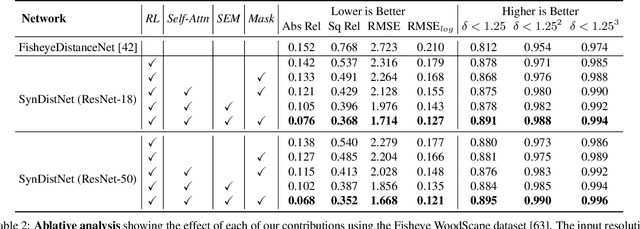
State-of-the-art self-supervised learning approaches for monocular depth estimation usually suffer from scale ambiguity. They do not generalize well when applied on distance estimation for complex projection models such as in fisheye and omnidirectional cameras. In this paper, we introduce a novel multi-task learning strategy to improve self-supervised monocular distance estimation on fisheye and pinhole camera images. Our contribution to this work is threefold: Firstly, we introduce a novel distance estimation network architecture using a self-attention based encoder coupled with robust semantic feature guidance to the decoder that can be trained in a one-stage fashion. Secondly, we integrate a generalized robust loss function, which improves performance significantly while removing the need for hyperparameter tuning with the reprojection loss. Finally, we reduce the artifacts caused by dynamic objects violating static world assumption by using a semantic masking strategy. We significantly improve upon the RMSE of previous work on fisheye by 25% reduction in RMSE. As there is limited work on fisheye cameras, we evaluated the proposed method on KITTI using a pinhole model.We achieved state-of-the-art performance among self-supervised methods without requiring an external scale estimation.