 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and Efficient Hierarchical Visual Topological Mapping
Apr 07, 2024



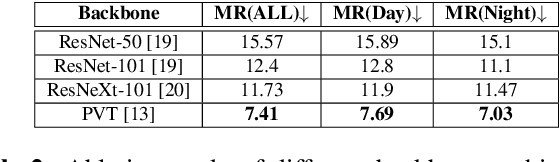
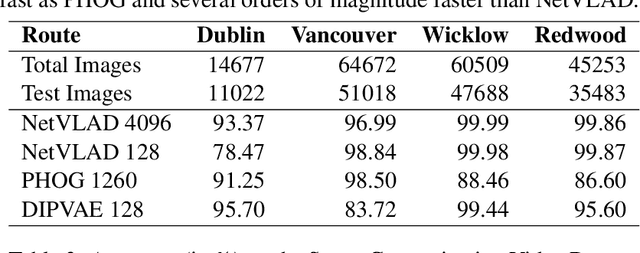
Hierarchical topological representations can significantly reduce search times within mapping and localization algorithms. Although recent research has shown the potential for such approaches, limited consideration has been given to the suitability and comparative performance of different global feature representations within this context. In this work, we evaluate state-of-the-art hand-crafted and learned global descriptors using a hierarchical topological mapping technique on benchmark datasets and present results of a comprehensive evaluation of the impact of the global descriptor used. Although learned descriptors have been incorporated into place recognition methods to improve retrieval accuracy and enhance overall recall, the problem of scalability and efficiency when applied to longer trajectories has not been adequately addressed in a majority of research studies. Based on our empirical analysis of multiple runs, we identify that continuity and distinctiveness are crucial characteristics for an optimal global descriptor that enable efficient and scalable hierarchical mapping, and present a methodology for quantifying and contrasting these characteristics across different global descriptors. Our study demonstrates that the use of global descriptors based on an unsupervised learned Variational Autoencoder (VAE) excels in these characteristics and achieves significantly lower runtime. It runs on a consumer grade desktop, up to 2.3x faster than the second best global descriptor, NetVLAD, and up to 9.5x faster than the hand-crafted descriptor, PHOG, on the longest track evaluated (St Lucia, 17.6 km), without sacrificing overall recall performance.
Surround-View Fisheye Optics in Computer Vision and Simulation: Survey and Challenges
Feb 21, 2024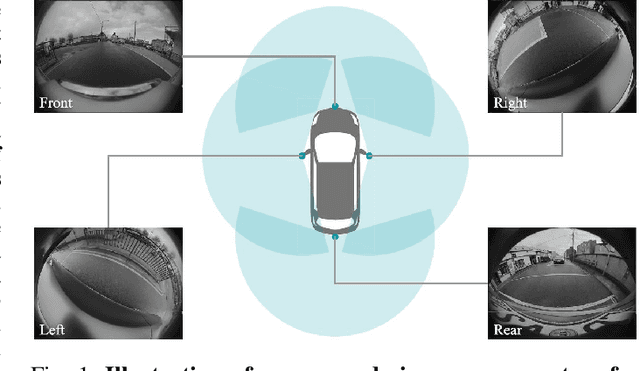

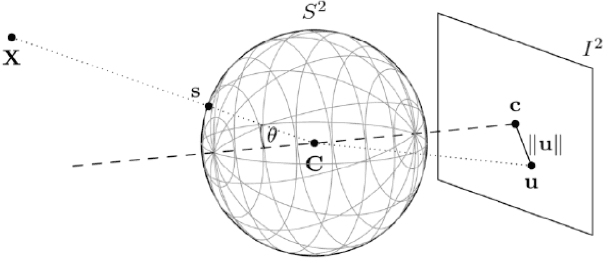

In this paper, we provide a survey on automotive surround-view fisheye optics, with an emphasis on the impact of optical artifacts on computer vision tasks in autonomous driving and ADAS. The automotive industry has advanced in applying state-of-the-art computer vision to enhance road safety and provide automated driving functionality. When using camera systems on vehicles, there is a particular need for a wide field of view to capture the entire vehicle's surroundings, in areas such as low-speed maneuvering, automated parking, and cocoon sensing. However, one crucial challenge in surround-view cameras is the strong optical aberrations of the fisheye camera, which is an area that has received little attention in the literature. Additionally, a comprehensive dataset is needed for testing safety-critical scenarios in vehicle automation. The industry has turned to simulation as a cost-effective strategy for creating synthetic datasets with surround-view camera imagery. We examine different simulation methods (such as model-driven and data-driven simulations) and discuss the simulators' ability (or lack thereof) to model real-world optical performance. Overall, this paper highlights the optical aberrations in automotive fisheye datasets, and the limitations of optical reality in simulated fisheye datasets, with a focus on computer vision in surround-view optical systems.
Revisiting Modality Imbalance In Multimodal Pedestrian Detection
Feb 24, 2023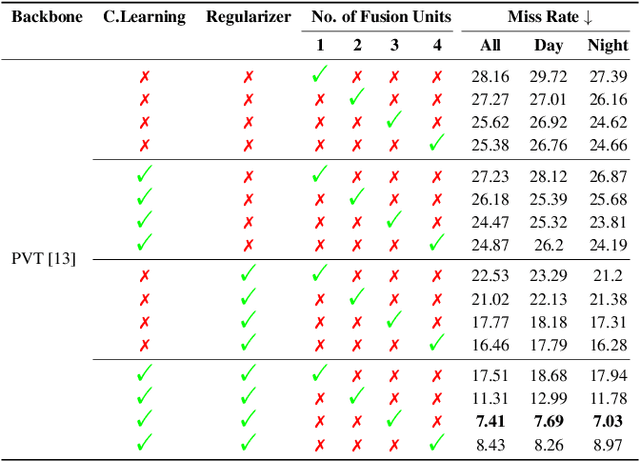
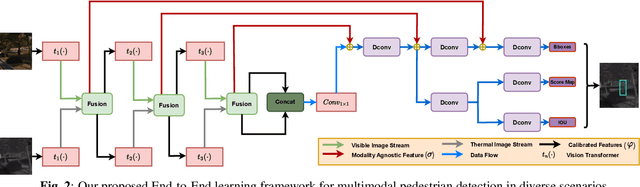

Multimodal learning, particularly for pedestrian detection, has recently received emphasis due to its capability to function equally well in several critical autonomous driving scenarios such as low-light, night-time, and adverse weather conditions. However, in most cases, the training distribution largely emphasizes the contribution of one specific input that makes the network biased towards one modality. Hence, the generalization of such models becomes a significant problem where the non-dominant input modality during training could be contributing more to the course of inference. Here, we introduce a novel training setup with regularizer in the multimodal architecture to resolve the problem of this disparity between the modalities. Specifically, our regularizer term helps to make the feature fusion method more robust by considering both the feature extractors equivalently important during the training to extract the multimodal distribution which is referred to as removing the imbalance problem. Furthermore, our decoupling concept of output stream helps the detection task by sharing the spatial sensitive information mutually. Extensive experiments of the proposed method on KAIST and UTokyo datasets shows improvement of the respective state-of-the-art performance.
Fast and Efficient Scene Categorization for Autonomous Driving using VAEs
Oct 26, 2022

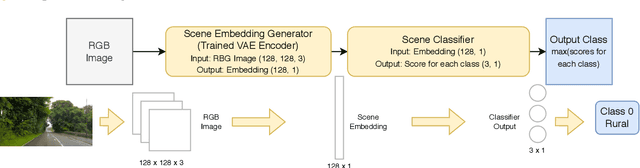
Scene categorization is a useful precursor task that provides prior knowledge for many advanced computer vision tasks with a broad range of applications in content-based image indexing and retrieval systems. Despite the success of data driven approaches in the field of computer vision such as object detection, semantic segmentation, etc., their application in learning high-level features for scene recognition has not achieved the same level of success. We propose to generate a fast and efficient intermediate interpretable generalized global descriptor that captures coarse features from the image and use a classification head to map the descriptors to 3 scene categories: Rural, Urban and Suburban. We train a Variational Autoencoder in an unsupervised manner and map images to a constrained multi-dimensional latent space and use the latent vectors as compact embeddings that serve as global descriptors for images. The experimental results evidence that the VAE latent vectors capture coarse information from the image, supporting their usage as global descriptors. The proposed global descriptor is very compact with an embedding length of 128, significantly faster to compute, and is robust to seasonal and illuminational changes, while capturing sufficient scene information required for scene categorization.
* Published in the 24th Irish Machine Vision and Image Processing Conference (IMVIP 2022)
Deep Multi-Task Networks For Occluded Pedestrian Pose Estimation
Jun 15, 2022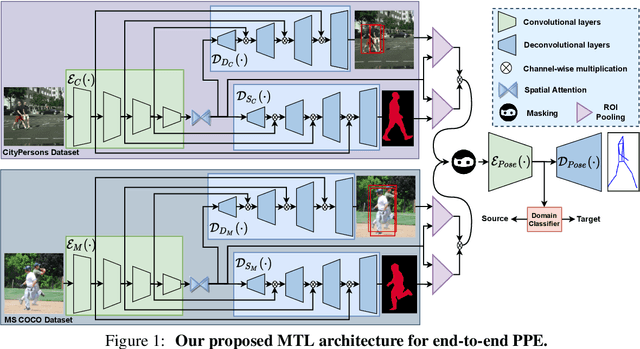
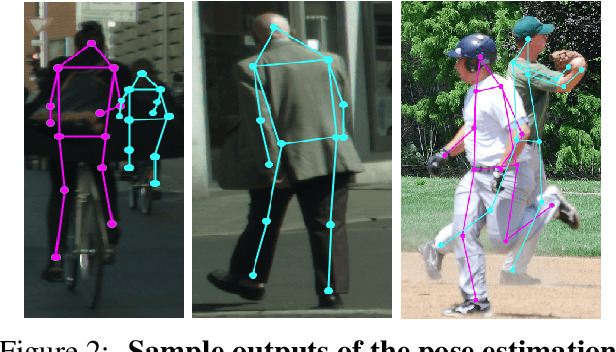
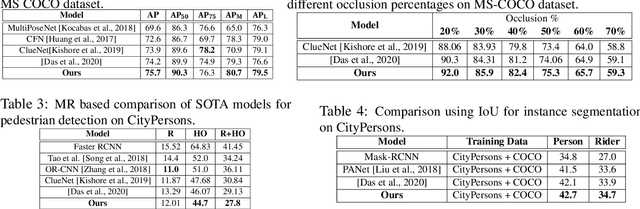
Most of the existing works on pedestrian pose estimation do not consider estimating the pose of an occluded pedestrians, as the annotations of the occluded parts are not available in relevant automotive datasets. For example, CityPersons, a well-known dataset for pedestrian detection in automotive scenes does not provide pose annotations, whereas MS-COCO, a non-automotive dataset, contains human pose estimation. In this work, we propose a multi-task framework to extract pedestrian features through detection and instance segmentation tasks performed separately on these two distributions. Thereafter, an encoder learns pose specific features using an unsupervised instance-level domain adaptation method for the pedestrian instances from both distributions. The proposed framework has improved state-of-the-art performances of pose estimation, pedestrian detection, and instance segmentation.
2.5D Vehicle Odometry Estimation
Nov 16, 2021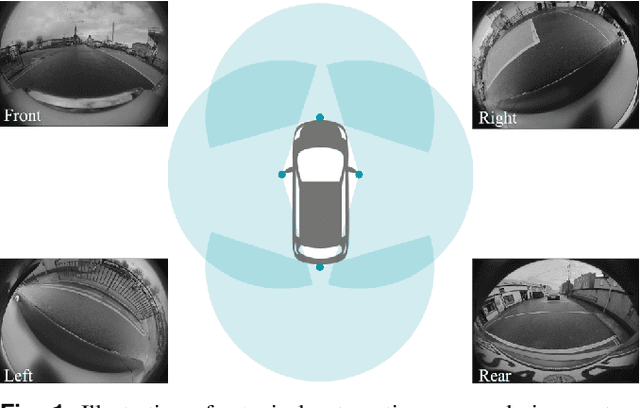

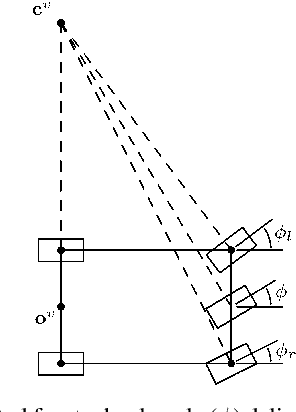
It is well understood that in ADAS applications, a good estimate of the pose of the vehicle is required. This paper proposes a metaphorically named 2.5D odometry, whereby the planar odometry derived from the yaw rate sensor and four wheel speed sensors is augmented by a linear model of suspension. While the core of the planar odometry is a yaw rate model that is already understood in the literature, we augment this by fitting a quadratic to the incoming signals, enabling interpolation, extrapolation, and a finer integration of the vehicle position. We show, by experimental results with a DGPS/IMU reference, that this model provides highly accurate odometry estimates, compared with existing methods. Utilising sensors that return the change in height of vehicle reference points with changing suspension configurations, we define a planar model of the vehicle suspension, thus augmenting the odometry model. We present an experimental framework and evaluations criteria by which the goodness of the odometry is evaluated and compared with existing methods. This odometry model has been designed to support low-speed surround-view camera systems that are well-known. Thus, we present some application results that show a performance boost for viewing and computer vision applications using the proposed odometry
* 13 pages, 16 figures, 2 tables
A 2.5D Vehicle Odometry Estimation for Vision Applications
May 06, 2021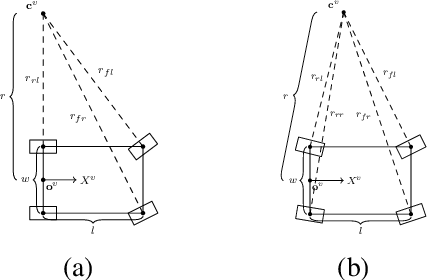

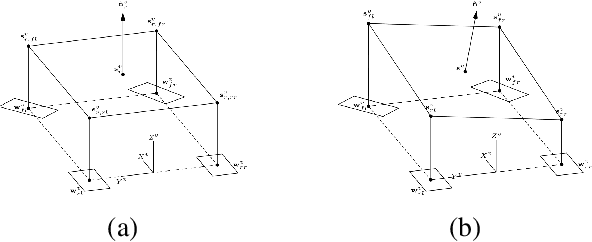
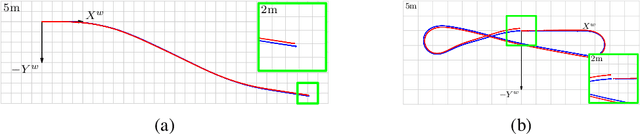
This paper proposes a method to estimate the pose of a sensor mounted on a vehicle as the vehicle moves through the world, an important topic for autonomous driving systems. Based on a set of commonly deployed vehicular odometric sensors, with outputs available on automotive communication buses (e.g. CAN or FlexRay), we describe a set of steps to combine a planar odometry based on wheel sensors with a suspension model based on linear suspension sensors. The aim is to determine a more accurate estimate of the camera pose. We outline its usage for applications in both visualisation and computer vision.
Vision-based Driver Assistance Systems: Survey, Taxonomy and Advances
Apr 26, 2021



Vision-based driver assistance systems is one of the rapidly growing research areas of ITS, due to various factors such as the increased level of safety requirements in automotive, computational power in embedded systems, and desire to get closer to autonomous driving. It is a cross disciplinary area encompassing specialised fields like computer vision, machine learning, robotic navigation, embedded systems, automotive electronics and safety critical software. In this paper, we survey the list of vision based advanced driver assistance systems with a consistent terminology and propose a taxonomy. We also propose an abstract model in an attempt to formalize a top-down view of application development to scale towards autonomous driving system.
Computer vision in automated parking systems: Design, implementation and challenges
Apr 26, 2021

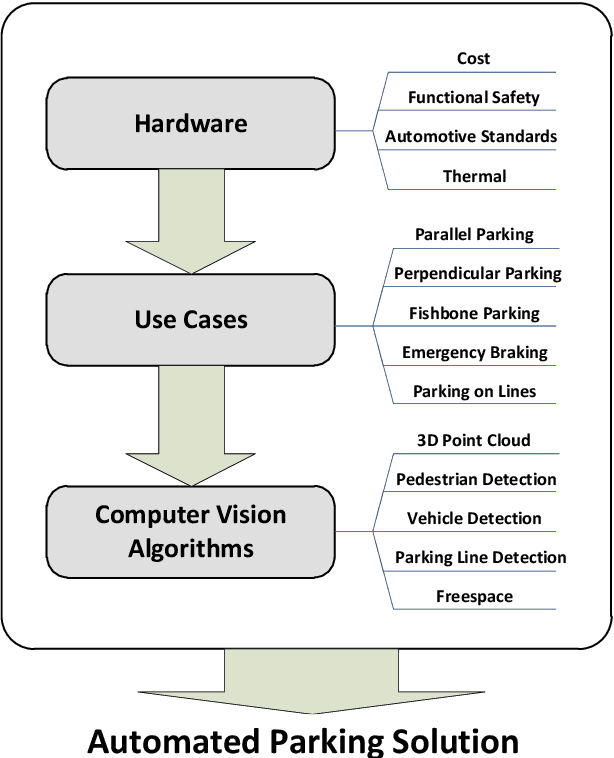

Automated driving is an active area of research in both industry and academia. Automated Parking, which is automated driving in a restricted scenario of parking with low speed manoeuvring, is a key enabling product for fully autonomous driving systems. It is also an important milestone from the perspective of a higher end system built from the previous generation driver assistance systems comprising of collision warning, pedestrian detection, etc. In this paper, we discuss the design and implementation of an automated parking system from the perspective of computer vision algorithms. Designing a low-cost system with functional safety is challenging and leads to a large gap between the prototype and the end product, in order to handle all the corner cases. We demonstrate how camera systems are crucial for addressing a range of automated parking use cases and also, to add robustness to systems based on active distance measuring sensors, such as ultrasonics and radar. The key vision modules which realize the parking use cases are 3D reconstruction, parking slot marking recognition, freespace and vehicle/pedestrian detection. We detail the important parking use cases and demonstrate how to combine the vision modules to form a robust parking system. To the best of the authors' knowledge, this is the first detailed discussion of a systemic view of a commercial automated parking system.
Near-field Sensing Architecture for Low-Speed Vehicle Automation using a Surround-view Fisheye Camera System
Mar 31, 2021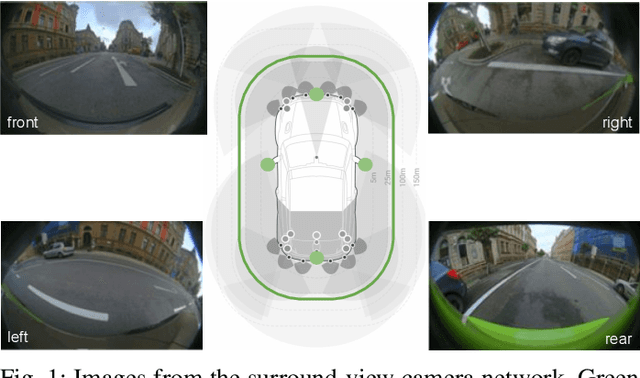
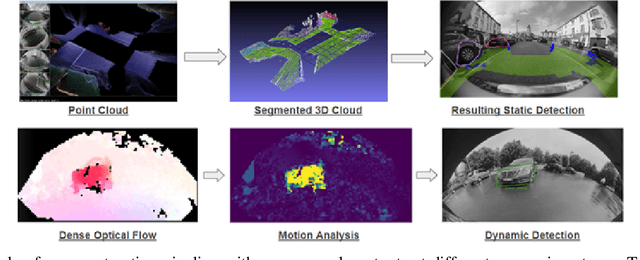
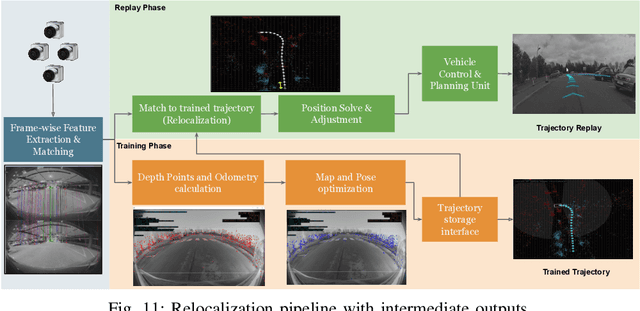
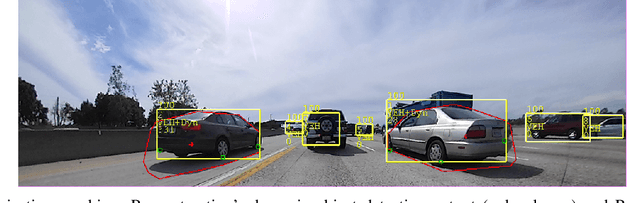
Cameras are the primary sensor in automated driving systems. They provide high information density and are optimal for detecting road infrastructure cues laid out for human vision. Surround view cameras typically comprise of four fisheye cameras with 190{\deg} field-of-view covering the entire 360{\deg} around the vehicle focused on near field sensing. They are the principal sensor for low-speed, high accuracy and close-range sensing applications, such as automated parking, traffic jam assistance and low-speed emergency braking. In this work, we describe our visual perception architecture on surround view cameras designed for a system deployed in commercial vehicles, provide a functional review of the different stages of such a computer vision system, and discuss some of the current technological challenges. We have designed our system into four modular components namely Recognition, Reconstruction, Relocalization and Reorganization. We jointly call this the 4R Architecture. We discuss how each component accomplishes a specific aspect and how they are synergized to form a complete system. Qualitative results are presented in the video at \url{https://youtu.be/ae8bCOF77uY}.