 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Quantum Efficiency Filters for Urban Hyperspectral Segmentation
Mar 27, 2026Hyperspectral sensing provides rich spectral information for scene understanding in urban driving, but its high dimensionality poses challenges for interpretation and efficient learning. We introduce Learnable Quantum Efficiency (LQE), a physics-inspired, interpretable dimensionality reduction (DR) method that parameterizes smooth high-order spectral response functions that emulate plausible sensor quantum efficiency curves. Unlike conventional methods or unconstrained learnable layers, LQE enforces physically motivated constraints, including a single dominant peak, smooth responses, and bounded bandwidth. This formulation yields a compact spectral representation that preserves discriminative information while remaining fully differentiable and end-to-end trainable within semantic segmentation models (SSMs). We conduct systematic evaluations across three publicly available multi-class hyperspectral urban driving datasets, comparing LQE against six conventional and seven learnable baseline DR methods across six SSMs. Averaged across all SSMs and configurations, LQE achieves the highest average mIoU, improving over conventional methods by 2.45\%, 0.45\%, and 1.04\%, and over learnable methods by 1.18\%, 1.56\%, and 0.81\% on HyKo, HSI-Drive, and Hyperspectral City, respectively. LQE maintains strong parameter efficiency (12--36 parameters compared to 51--22K for competing learnable approaches) and competitive inference latency. Ablation studies show that low-order configurations are optimal, while the learned spectral filters converge to dataset-intrinsic wavelength patterns. These results demonstrate that physics-informed spectral learning can improve both performance and interpretability, providing a principled bridge between hyperspectral perception and data-driven multispectral sensor design for automotive vision systems.
Hyperspectral Sensors and Autonomous Driving: Technologies, Limitations, and Opportunities
Aug 27, 2025Hyperspectral imaging (HSI) offers a transformative sensing modality for Advanced Driver Assistance Systems (ADAS) and autonomous driving (AD) applications, enabling material-level scene understanding through fine spectral resolution beyond the capabilities of traditional RGB imaging. This paper presents the first comprehensive review of HSI for automotive applications, examining the strengths, limitations, and suitability of current HSI technologies in the context of ADAS/AD. In addition to this qualitative review, we analyze 216 commercially available HSI and multispectral imaging cameras, benchmarking them against key automotive criteria: frame rate, spatial resolution, spectral dimensionality, and compliance with AEC-Q100 temperature standards. Our analysis reveals a significant gap between HSI's demonstrated research potential and its commercial readiness. Only four cameras meet the defined performance thresholds, and none comply with AEC-Q100 requirements. In addition, the paper reviews recent HSI datasets and applications, including semantic segmentation for road surface classification, pedestrian separability, and adverse weather perception. Our review shows that current HSI datasets are limited in terms of scale, spectral consistency, the number of spectral channels, and environmental diversity, posing challenges for the development of perception algorithms and the adequate validation of HSI's true potential in ADAS/AD applications. This review paper establishes the current state of HSI in automotive contexts as of 2025 and outlines key research directions toward practical integration of spectral imaging in ADAS and autonomous systems.
Hyperspectral Imaging-Based Perception in Autonomous Driving Scenarios: Benchmarking Baseline Semantic Segmentation Models
Oct 29, 2024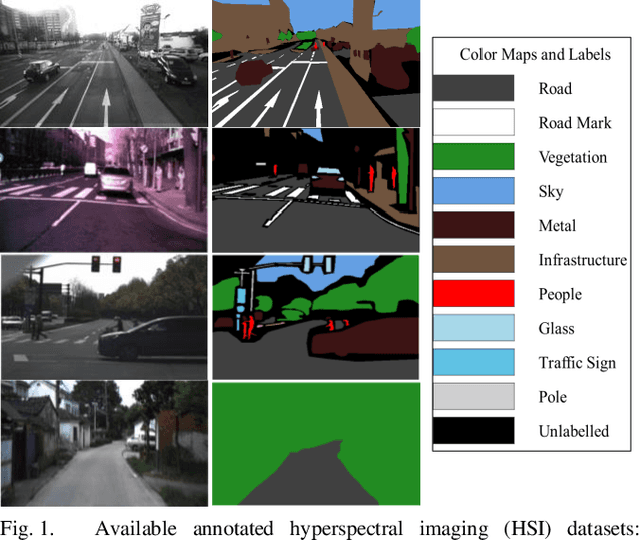

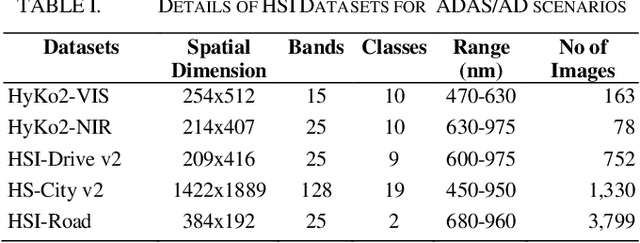
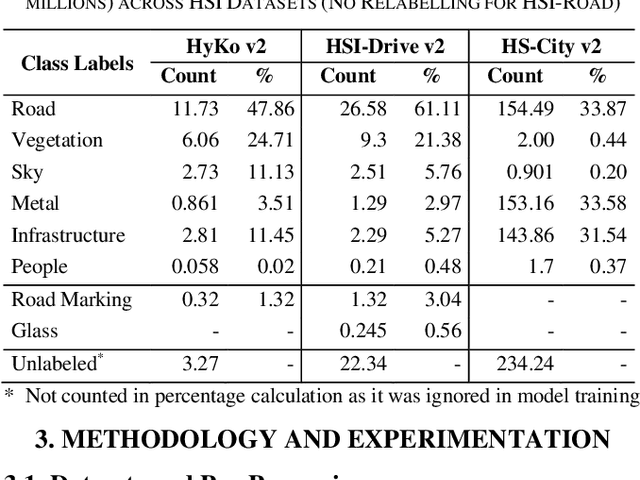
Hyperspectral Imaging (HSI) is known for its advantages over traditional RGB imaging in remote sensing, agriculture, and medicine. Recently, it has gained attention for enhancing Advanced Driving Assistance Systems (ADAS) perception. Several HSI datasets such as HyKo, HSI-Drive, HSI-Road, and Hyperspectral City have been made available. However, a comprehensive evaluation of semantic segmentation models (SSM) using these datasets is lacking. To address this gap, we evaluated the available annotated HSI datasets on four deep learning-based baseline SSMs: DeepLab v3+, HRNet, PSPNet, and U-Net, along with its two variants: Coordinate Attention (UNet-CA) and Convolutional Block-Attention Module (UNet-CBAM). The original model architectures were adapted to handle the varying spatial and spectral dimensions of the datasets. These baseline SSMs were trained using a class-weighted loss function for individual HSI datasets and evaluated using mean-based metrics such as intersection over union (IoU), recall, precision, F1 score, specificity, and accuracy. Our results indicate that UNet-CBAM, which extracts channel-wise features, outperforms other SSMs and shows potential to leverage spectral information for enhanced semantic segmentation. This study establishes a baseline SSM benchmark on available annotated datasets for future evaluation of HSI-based ADAS perception. However, limitations of current HSI datasets, such as limited dataset size, high class imbalance, and lack of fine-grained annotations, remain significant constraints for developing robust SSMs for ADAS applications.
Unleashing the Potential of Spiking Neural Networks by Dynamic Confidence
Mar 26, 2023This paper presents a new methodology to alleviate the fundamental trade-off between accuracy and latency in spiking neural networks (SNNs). The approach involves decoding confidence information over time from the SNN outputs and using it to develop a decision-making agent that can dynamically determine when to terminate each inference. The proposed method, Dynamic Confidence, provides several significant benefits to SNNs. 1. It can effectively optimize latency dynamically at runtime, setting it apart from many existing low-latency SNN algorithms. Our experiments on CIFAR-10 and ImageNet datasets have demonstrated an average 40% speedup across eight different settings after applying Dynamic Confidence. 2. The decision-making agent in Dynamic Confidence is straightforward to construct and highly robust in parameter space, making it extremely easy to implement. 3. The proposed method enables visualizing the potential of any given SNN, which sets a target for current SNNs to approach. For instance, if an SNN can terminate at the most appropriate time point for each input sample, a ResNet-50 SNN can achieve an accuracy as high as 82.47% on ImageNet within just 4.71 time steps on average. Unlocking the potential of SNNs needs a highly-reliable decision-making agent to be constructed and fed with a high-quality estimation of ground truth. In this regard, Dynamic Confidence represents a meaningful step toward realizing the potential of SNNs.
Revisiting Modality Imbalance In Multimodal Pedestrian Detection
Feb 24, 2023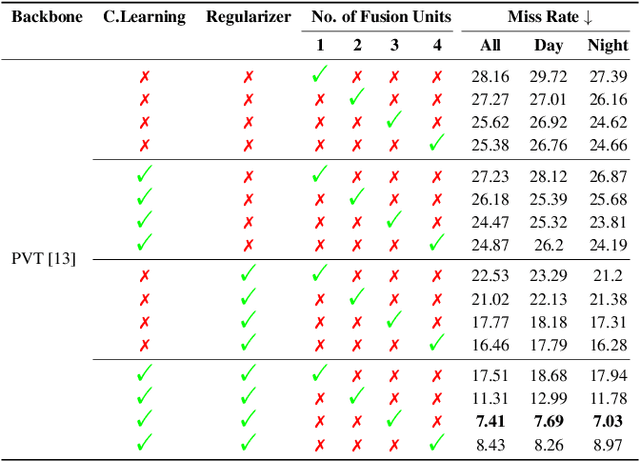
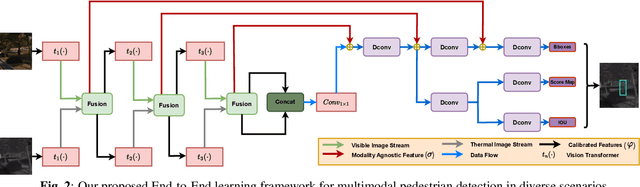
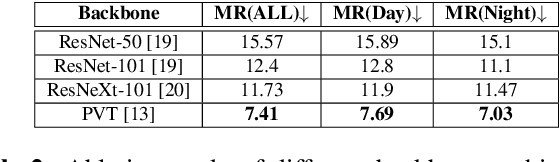

Multimodal learning, particularly for pedestrian detection, has recently received emphasis due to its capability to function equally well in several critical autonomous driving scenarios such as low-light, night-time, and adverse weather conditions. However, in most cases, the training distribution largely emphasizes the contribution of one specific input that makes the network biased towards one modality. Hence, the generalization of such models becomes a significant problem where the non-dominant input modality during training could be contributing more to the course of inference. Here, we introduce a novel training setup with regularizer in the multimodal architecture to resolve the problem of this disparity between the modalities. Specifically, our regularizer term helps to make the feature fusion method more robust by considering both the feature extractors equivalently important during the training to extract the multimodal distribution which is referred to as removing the imbalance problem. Furthermore, our decoupling concept of output stream helps the detection task by sharing the spatial sensitive information mutually. Extensive experiments of the proposed method on KAIST and UTokyo datasets shows improvement of the respective state-of-the-art performance.
Deep Multi-Task Networks For Occluded Pedestrian Pose Estimation
Jun 15, 2022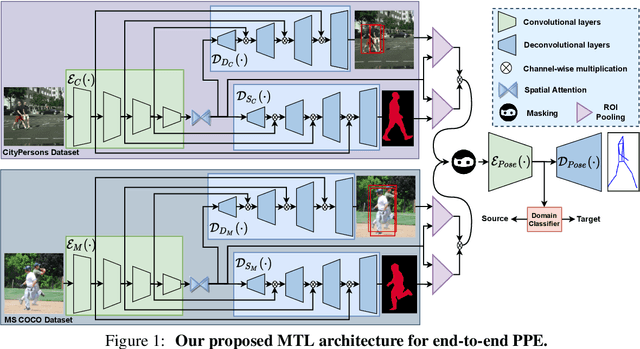
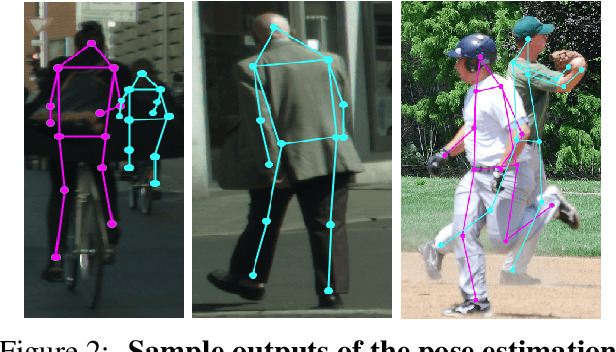
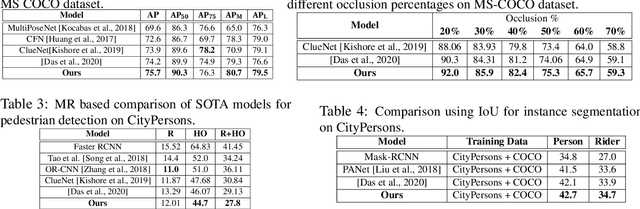
Most of the existing works on pedestrian pose estimation do not consider estimating the pose of an occluded pedestrians, as the annotations of the occluded parts are not available in relevant automotive datasets. For example, CityPersons, a well-known dataset for pedestrian detection in automotive scenes does not provide pose annotations, whereas MS-COCO, a non-automotive dataset, contains human pose estimation. In this work, we propose a multi-task framework to extract pedestrian features through detection and instance segmentation tasks performed separately on these two distributions. Thereafter, an encoder learns pose specific features using an unsupervised instance-level domain adaptation method for the pedestrian instances from both distributions. The proposed framework has improved state-of-the-art performances of pose estimation, pedestrian detection, and instance segmentation.
E-Scooter Rider Detection and Classification in Dense Urban Environments
May 20, 2022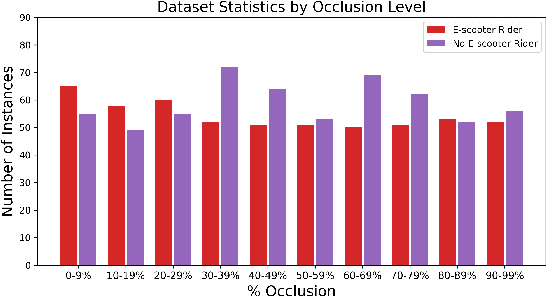

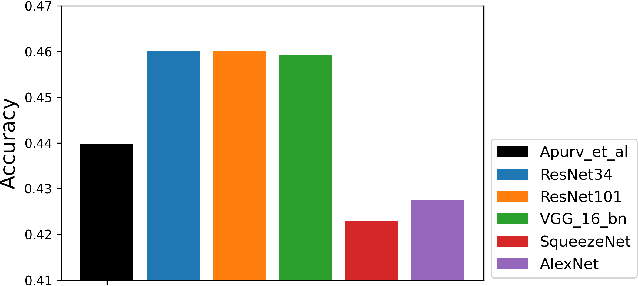
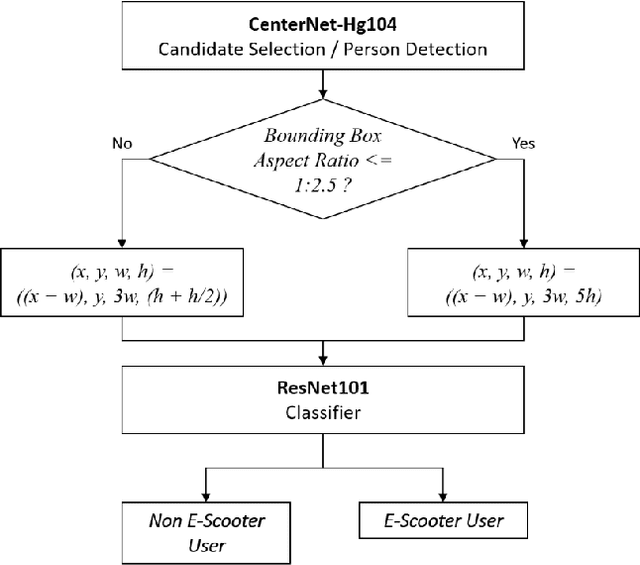
Accurate detection and classification of vulnerable road users is a safety critical requirement for the deployment of autonomous vehicles in heterogeneous traffic. Although similar in physical appearance to pedestrians, e-scooter riders follow distinctly different characteristics of movement and can reach speeds of up to 45kmph. The challenge of detecting e-scooter riders is exacerbated in urban environments where the frequency of partial occlusion is increased as riders navigate between vehicles, traffic infrastructure and other road users. This can lead to the non-detection or mis-classification of e-scooter riders as pedestrians, providing inaccurate information for accident mitigation and path planning in autonomous vehicle applications. This research introduces a novel benchmark for partially occluded e-scooter rider detection to facilitate the objective characterization of detection models. A novel, occlusion-aware method of e-scooter rider detection is presented that achieves a 15.93% improvement in detection performance over the current state of the art.
The Impact of Partial Occlusion on Pedestrian Detectability
May 12, 2022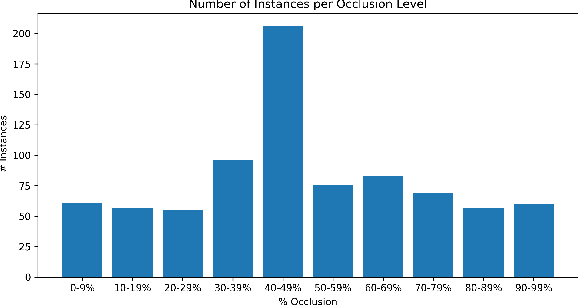

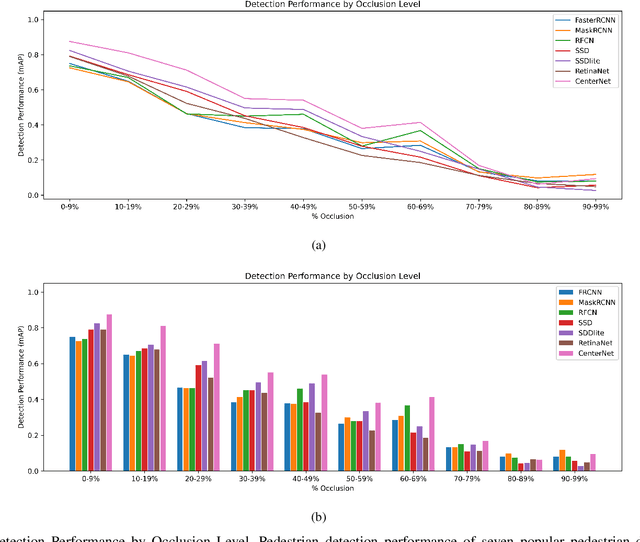
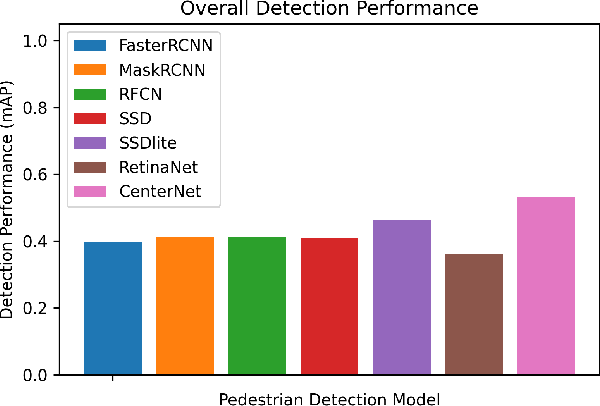
Robust detection of vulnerable road users is a safety critical requirement for the deployment of autonomous vehicles in heterogeneous traffic. One of the most complex outstanding challenges is that of partial occlusion where a target object is only partially available to the sensor due to obstruction by another foreground object. A number of leading pedestrian detection benchmarks provide annotation for partial occlusion, however each benchmark varies greatly in their definition of the occurrence and severity of occlusion. Recent research demonstrates that a high degree of subjectivity is used to classify occlusion level in these cases and occlusion is typically categorized into 2 to 3 broad categories such as partially and heavily occluded. This can lead to inaccurate or inconsistent reporting of pedestrian detection model performance depending on which benchmark is used. This research introduces a novel, objective benchmark for partially occluded pedestrian detection to facilitate the objective characterization of pedestrian detection models. Characterization is carried out on seven popular pedestrian detection models for a range of occlusion levels from 0-99%. Results demonstrate that pedestrian detection performance degrades, and the number of false negative detections increase as pedestrian occlusion level increases. Of the seven popular pedestrian detection routines characterized, CenterNet has the greatest overall performance, followed by SSDlite. RetinaNet has the lowest overall detection performance across the range of occlusion levels.
An Objective Method for Pedestrian Occlusion Level Classification
May 11, 2022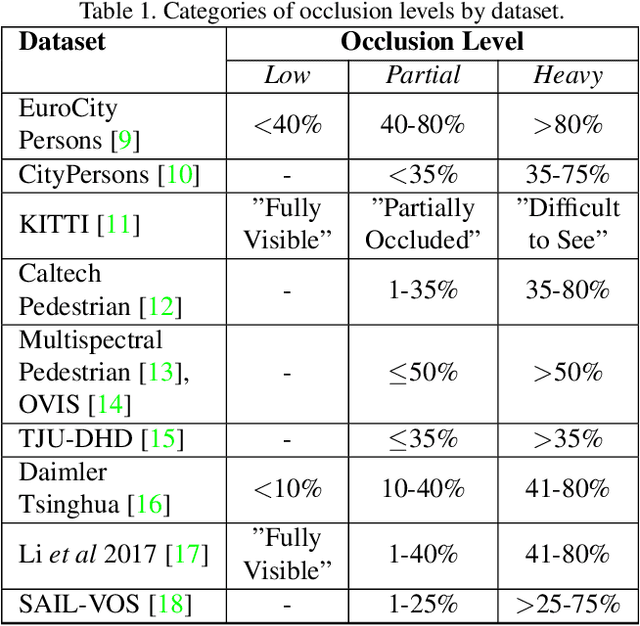
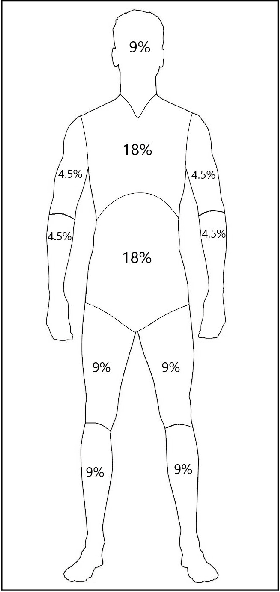

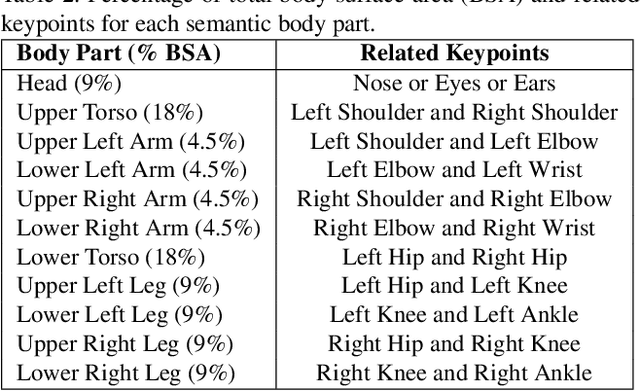
Pedestrian detection is among the most safety-critical features of driver assistance systems for autonomous vehicles. One of the most complex detection challenges is that of partial occlusion, where a target object is only partially available to the sensor due to obstruction by another foreground object. A number of current pedestrian detection benchmarks provide annotation for partial occlusion to assess algorithm performance in these scenarios, however each benchmark varies greatly in their definition of the occurrence and severity of occlusion. In addition, current occlusion level annotation methods contain a high degree of subjectivity by the human annotator. This can lead to inaccurate or inconsistent reporting of an algorithm's detection performance for partially occluded pedestrians, depending on which benchmark is used. This research presents a novel, objective method for pedestrian occlusion level classification for ground truth annotation. Occlusion level classification is achieved through the identification of visible pedestrian keypoints and through the use of a novel, effective method of 2D body surface area estimation. Experimental results demonstrate that the proposed method reflects the pixel-wise occlusion level of pedestrians in images and is effective for all forms of occlusion, including challenging edge cases such as self-occlusion, truncation and inter-occluding pedestrians.
An FPGA Implementation of Convolutional Spiking Neural Networks for Radioisotope Identification
Feb 24, 2021
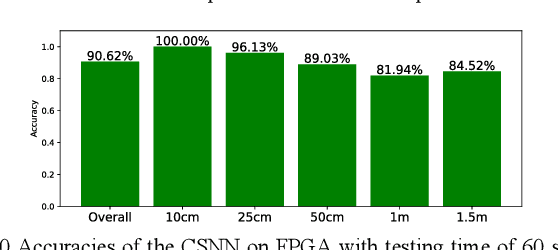
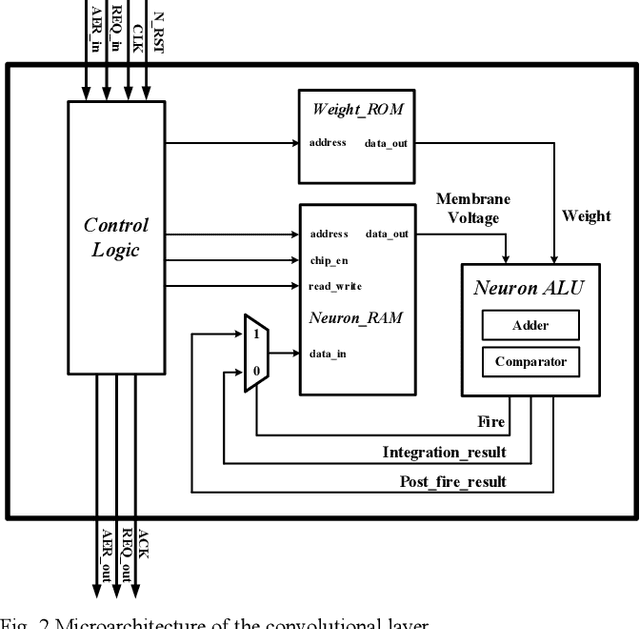
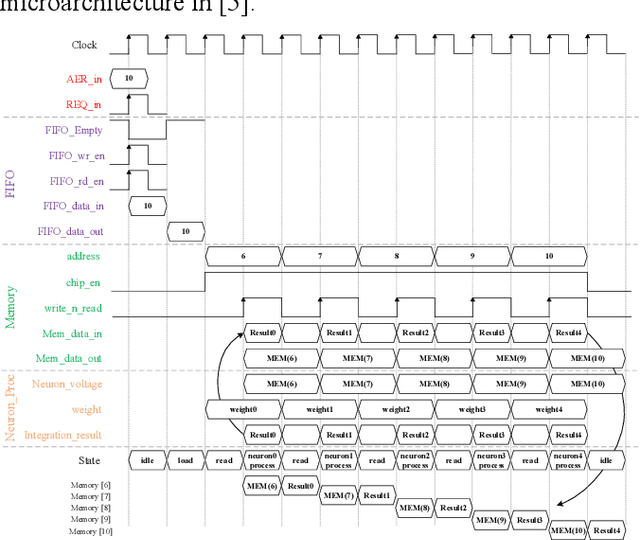
This paper details the FPGA implementation methodology for Convolutional Spiking Neural Networks (CSNN) and applies this methodology to low-power radioisotope identification using high-resolution data. Power consumption of 75 mW has been achieved on an FPGA implementation of a CSNN, with an inference accuracy of 90.62% on a synthetic dataset. The chip validation method is presented. Prototyping was accelerated by evaluating SNN parameters using SpiNNaker neuromorphic platform.