 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Quantum Efficiency Filters for Urban Hyperspectral Segmentation
Mar 27, 2026Hyperspectral sensing provides rich spectral information for scene understanding in urban driving, but its high dimensionality poses challenges for interpretation and efficient learning. We introduce Learnable Quantum Efficiency (LQE), a physics-inspired, interpretable dimensionality reduction (DR) method that parameterizes smooth high-order spectral response functions that emulate plausible sensor quantum efficiency curves. Unlike conventional methods or unconstrained learnable layers, LQE enforces physically motivated constraints, including a single dominant peak, smooth responses, and bounded bandwidth. This formulation yields a compact spectral representation that preserves discriminative information while remaining fully differentiable and end-to-end trainable within semantic segmentation models (SSMs). We conduct systematic evaluations across three publicly available multi-class hyperspectral urban driving datasets, comparing LQE against six conventional and seven learnable baseline DR methods across six SSMs. Averaged across all SSMs and configurations, LQE achieves the highest average mIoU, improving over conventional methods by 2.45\%, 0.45\%, and 1.04\%, and over learnable methods by 1.18\%, 1.56\%, and 0.81\% on HyKo, HSI-Drive, and Hyperspectral City, respectively. LQE maintains strong parameter efficiency (12--36 parameters compared to 51--22K for competing learnable approaches) and competitive inference latency. Ablation studies show that low-order configurations are optimal, while the learned spectral filters converge to dataset-intrinsic wavelength patterns. These results demonstrate that physics-informed spectral learning can improve both performance and interpretability, providing a principled bridge between hyperspectral perception and data-driven multispectral sensor design for automotive vision systems.
Vision-Language Models vs Human: Perceptual Image Quality Assessment
Mar 25, 2026Psychophysical experiments remain the most reliable approach for perceptual image quality assessment (IQA), yet their cost and limited scalability encourage automated approaches. We investigate whether Vision Language Models (VLMs) can approximate human perceptual judgments across three image quality scales: contrast, colorfulness and overall preference. Six VLMs four proprietary and two openweight models are benchmarked against psychophysical data. This work presents a systematic benchmark of VLMs for perceptual IQA through comparison with human psychophysical data. The results reveal strong attribute dependent variability models with high human alignment for colorfulness (ρup to 0.93) underperform on contrast and vice-versa. Attribute weighting analysis further shows that most VLMs assign higher weights to colorfulness compared to contrast when evaluating overall preference similar to the psychophysical data. Intramodel consistency analysis reveals a counterintuitive tradeoff: the most self consistent models are not necessarily the most human aligned suggesting response variability reflects sensitivity to scene dependent perceptual cues. Furthermore, human-VLM agreement is increased with perceptual separability, indicating VLMs are more reliable when stimulus differences are clearly expressed.
Hyperspectral Sensors and Autonomous Driving: Technologies, Limitations, and Opportunities
Aug 27, 2025Hyperspectral imaging (HSI) offers a transformative sensing modality for Advanced Driver Assistance Systems (ADAS) and autonomous driving (AD) applications, enabling material-level scene understanding through fine spectral resolution beyond the capabilities of traditional RGB imaging. This paper presents the first comprehensive review of HSI for automotive applications, examining the strengths, limitations, and suitability of current HSI technologies in the context of ADAS/AD. In addition to this qualitative review, we analyze 216 commercially available HSI and multispectral imaging cameras, benchmarking them against key automotive criteria: frame rate, spatial resolution, spectral dimensionality, and compliance with AEC-Q100 temperature standards. Our analysis reveals a significant gap between HSI's demonstrated research potential and its commercial readiness. Only four cameras meet the defined performance thresholds, and none comply with AEC-Q100 requirements. In addition, the paper reviews recent HSI datasets and applications, including semantic segmentation for road surface classification, pedestrian separability, and adverse weather perception. Our review shows that current HSI datasets are limited in terms of scale, spectral consistency, the number of spectral channels, and environmental diversity, posing challenges for the development of perception algorithms and the adequate validation of HSI's true potential in ADAS/AD applications. This review paper establishes the current state of HSI in automotive contexts as of 2025 and outlines key research directions toward practical integration of spectral imaging in ADAS and autonomous systems.
V-CAS: A Realtime Vehicle Anti Collision System Using Vision Transformer on Multi-Camera Streams
Nov 04, 2024This paper introduces a real-time Vehicle Collision Avoidance System (V-CAS) designed to enhance vehicle safety through adaptive braking based on environmental perception. V-CAS leverages the advanced vision-based transformer model RT-DETR, DeepSORT tracking, speed estimation, brake light detection, and an adaptive braking mechanism. It computes a composite collision risk score based on vehicles' relative accelerations, distances, and detected braking actions, using brake light signals and trajectory data from multiple camera streams to improve scene perception. Implemented on the Jetson Orin Nano, V-CAS enables real-time collision risk assessment and proactive mitigation through adaptive braking. A comprehensive training process was conducted on various datasets for comparative analysis, followed by fine-tuning the selected object detection model using transfer learning. The system's effectiveness was rigorously evaluated on the Car Crash Dataset (CCD) from YouTube and through real-time experiments, achieving over 98% accuracy with an average proactive alert time of 1.13 seconds. Results indicate significant improvements in object detection and tracking, enhancing collision avoidance compared to traditional single-camera methods. This research demonstrates the potential of low-cost, multi-camera embedded vision transformer systems to advance automotive safety through enhanced environmental perception and proactive collision avoidance mechanisms.
SFA-UNet: More Attention to Multi-Scale Contrast and Contextual Information in Infrared Small Object Segmentation
Oct 30, 2024



Computer vision researchers have extensively worked on fundamental infrared visual recognition for the past few decades. Among various approaches, deep learning has emerged as the most promising candidate. However, Infrared Small Object Segmentation (ISOS) remains a major focus due to several challenges including: 1) the lack of effective utilization of local contrast and global contextual information; 2) the potential loss of small objects in deep models; and 3) the struggling to capture fine-grained details and ignore noise. To address these challenges, we propose a modified U-Net architecture, named SFA-UNet, by combining Scharr Convolution (SC) and Fast Fourier Convolution (FFC) in addition to vertical and horizontal Attention gates (AG) into UNet. SFA-UNet utilizes double convolution layers with the addition of SC and FFC in its encoder and decoder layers. SC helps to learn the foreground-to-background contrast information whereas FFC provide multi-scale contextual information while mitigating the small objects vanishing problem. Additionally, the introduction of vertical AGs in encoder layers enhances the model's focus on the targeted object by ignoring irrelevant regions. We evaluated the proposed approach on publicly available, SIRST and IRSTD datasets, and achieved superior performance by an average 0.75% with variance of 0.025 of all combined metrics in multiple runs as compared to the existing state-of-the-art methods
Hyperspectral Imaging-Based Perception in Autonomous Driving Scenarios: Benchmarking Baseline Semantic Segmentation Models
Oct 29, 2024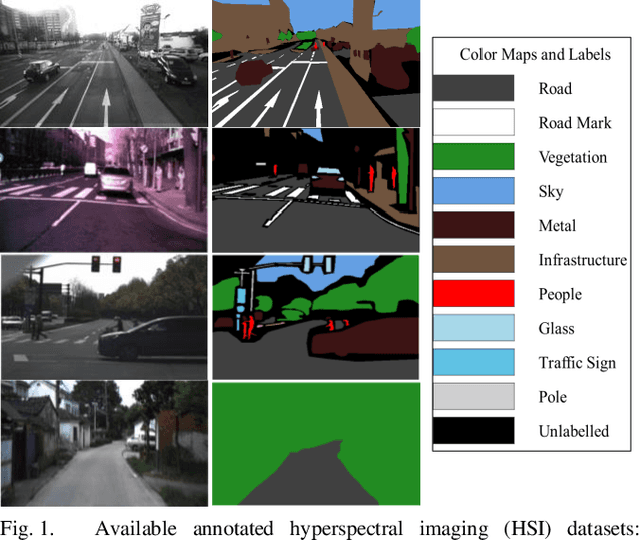

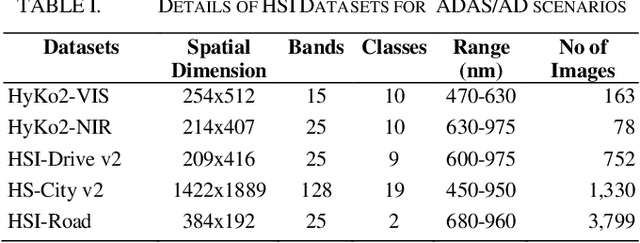
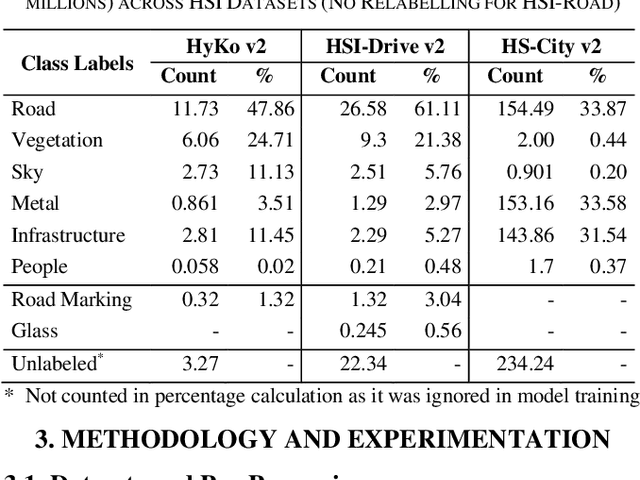
Hyperspectral Imaging (HSI) is known for its advantages over traditional RGB imaging in remote sensing, agriculture, and medicine. Recently, it has gained attention for enhancing Advanced Driving Assistance Systems (ADAS) perception. Several HSI datasets such as HyKo, HSI-Drive, HSI-Road, and Hyperspectral City have been made available. However, a comprehensive evaluation of semantic segmentation models (SSM) using these datasets is lacking. To address this gap, we evaluated the available annotated HSI datasets on four deep learning-based baseline SSMs: DeepLab v3+, HRNet, PSPNet, and U-Net, along with its two variants: Coordinate Attention (UNet-CA) and Convolutional Block-Attention Module (UNet-CBAM). The original model architectures were adapted to handle the varying spatial and spectral dimensions of the datasets. These baseline SSMs were trained using a class-weighted loss function for individual HSI datasets and evaluated using mean-based metrics such as intersection over union (IoU), recall, precision, F1 score, specificity, and accuracy. Our results indicate that UNet-CBAM, which extracts channel-wise features, outperforms other SSMs and shows potential to leverage spectral information for enhanced semantic segmentation. This study establishes a baseline SSM benchmark on available annotated datasets for future evaluation of HSI-based ADAS perception. However, limitations of current HSI datasets, such as limited dataset size, high class imbalance, and lack of fine-grained annotations, remain significant constraints for developing robust SSMs for ADAS applications.