 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Out-of-Domain Detection for Automated Driving
Oct 23, 2023

Ensuring safety in automated driving is a major challenge for the automotive industry. Special attention is paid to artificial intelligence, in particular to Deep Neural Networks (DNNs), which is considered a key technology in the realization of highly automated driving. DNNs learn from training data, which means that they only achieve good accuracy within the underlying data distribution of the training data. When leaving the training domain, a distributional shift is caused, which can lead to a drastic reduction of accuracy. In this work, we present a proof of concept for a safety mechanism that can detect the leaving of the domain online, i.e. at runtime. In our experiments with the Synthia data set we can show that a 100 % correct detection of whether the input data is inside or outside the domain is achieved. The ability to detect when the vehicle leaves the domain can be an important requirement for certification.
Improving Predictive Performance and Calibration by Weight Fusion in Semantic Segmentation
Jul 22, 2022

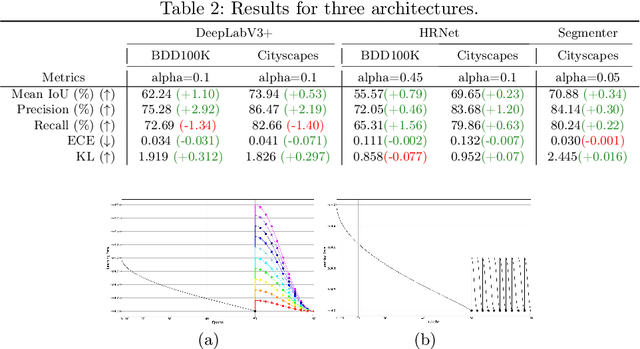
Averaging predictions of a deep ensemble of networks is apopular and effective method to improve predictive performance andcalibration in various benchmarks and Kaggle competitions. However, theruntime and training cost of deep ensembles grow linearly with the size ofthe ensemble, making them unsuitable for many applications. Averagingensemble weights instead of predictions circumvents this disadvantageduring inference and is typically applied to intermediate checkpoints ofa model to reduce training cost. Albeit effective, only few works haveimproved the understanding and the performance of weight averaging.Here, we revisit this approach and show that a simple weight fusion (WF)strategy can lead to a significantly improved predictive performance andcalibration. We describe what prerequisites the weights must meet interms of weight space, functional space and loss. Furthermore, we presenta new test method (called oracle test) to measure the functional spacebetween weights. We demonstrate the versatility of our WF strategy acrossstate of the art segmentation CNNs and Transformers as well as real worlddatasets such as BDD100K and Cityscapes. We compare WF with similarapproaches and show our superiority for in- and out-of-distribution datain terms of predictive performance and calibration.
Inspect, Understand, Overcome: A Survey of Practical Methods for AI Safety
Apr 29, 2021The use of deep neural networks (DNNs) in safety-critical applications like mobile health and autonomous driving is challenging due to numerous model-inherent shortcomings. These shortcomings are diverse and range from a lack of generalization over insufficient interpretability to problems with malicious inputs. Cyber-physical systems employing DNNs are therefore likely to suffer from safety concerns. In recent years, a zoo of state-of-the-art techniques aiming to address these safety concerns has emerged. This work provides a structured and broad overview of them. We first identify categories of insufficiencies to then describe research activities aiming at their detection, quantification, or mitigation. Our paper addresses both machine learning experts and safety engineers: The former ones might profit from the broad range of machine learning topics covered and discussions on limitations of recent methods. The latter ones might gain insights into the specifics of modern ML methods. We moreover hope that our contribution fuels discussions on desiderata for ML systems and strategies on how to propel existing approaches accordingly.
Strategy to Increase the Safety of a DNN-based Perception for HAD Systems
Feb 20, 2020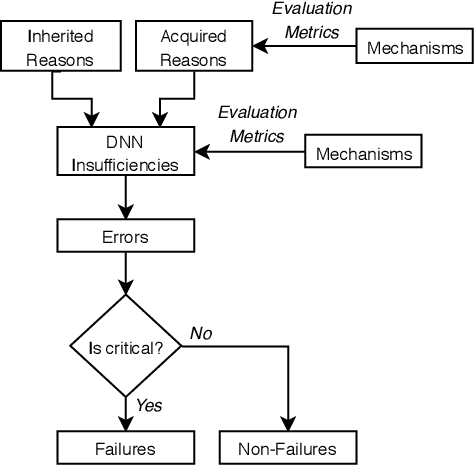
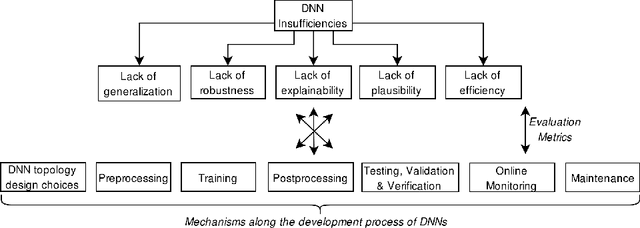
Safety is one of the most important development goals for highly automated driving (HAD) systems. This applies in particular to the perception function driven by Deep Neural Networks (DNNs). For these, large parts of the traditional safety processes and requirements are not fully applicable or sufficient. The aim of this paper is to present a framework for the description and mitigation of DNN insufficiencies and the derivation of relevant safety mechanisms to increase the safety of DNNs. To assess the effectiveness of these safety mechanisms, we present a categorization scheme for evaluation metrics.
Complexer-YOLO: Real-Time 3D Object Detection and Tracking on Semantic Point Clouds
Apr 16, 2019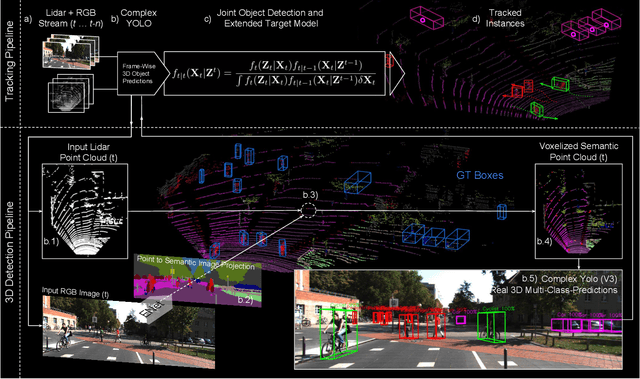
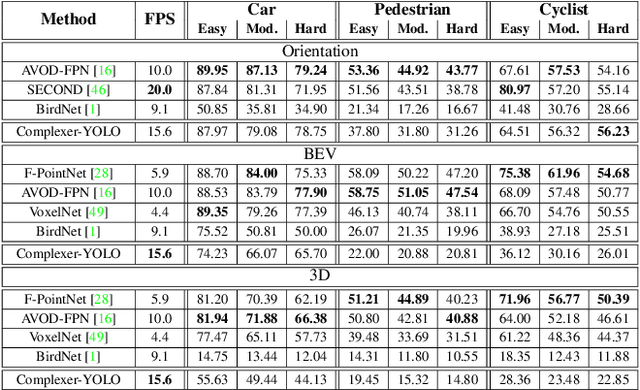
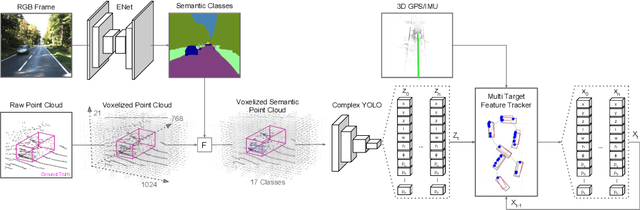
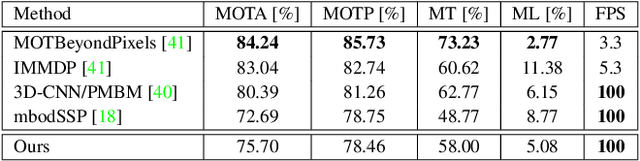
Accurate detection of 3D objects is a fundamental problem in computer vision and has an enormous impact on autonomous cars, augmented/virtual reality and many applications in robotics. In this work we present a novel fusion of neural network based state-of-the-art 3D detector and visual semantic segmentation in the context of autonomous driving. Additionally, we introduce Scale-Rotation-Translation score (SRTs), a fast and highly parameterizable evaluation metric for comparison of object detections, which speeds up our inference time up to 20\% and halves training time. On top, we apply state-of-the-art online multi target feature tracking on the object measurements to further increase accuracy and robustness utilizing temporal information. Our experiments on KITTI show that we achieve same results as state-of-the-art in all related categories, while maintaining the performance and accuracy trade-off and still run in real-time. Furthermore, our model is the first one that fuses visual semantic with 3D object detection.
Efficient Semantic Segmentation for Visual Bird's-eye View Interpretation
Nov 29, 2018


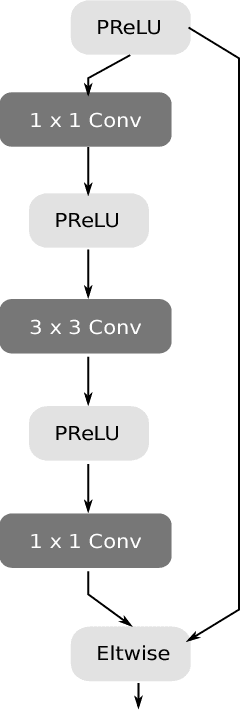
The ability to perform semantic segmentation in real-time capable applications with limited hardware is of great importance. One such application is the interpretation of the visual bird's-eye view, which requires the semantic segmentation of the four omnidirectional camera images. In this paper, we present an efficient semantic segmentation that sets new standards in terms of runtime and hardware requirements. Our two main contributions are the decrease of the runtime by parallelizing the ArgMax layer and the reduction of hardware requirements by applying the channel pruning method to the ENet model.